如何以低成本实现语言模型的强推理能力? 受这一根本性问题驱动,我们提出了 Tina —— 一个以高成本效率实现的轻量级推理模型家族。Tina 显示出,即使仅使用极少的资源,也能显著提升推理性能。这一成果通过在强化学习(RL)过程中对一个仅 15 亿参数的微型基础模型应用 低秩适配(LoRA) 的参数高效更新方式实现。
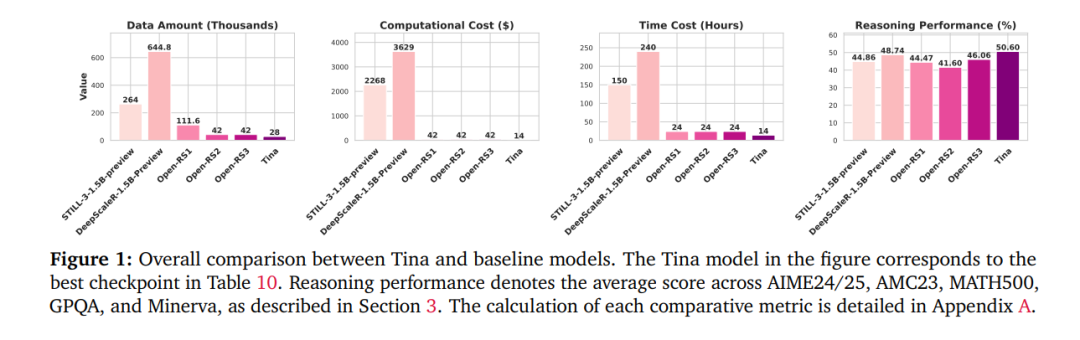
这种极简方法训练出的模型,在推理性能方面不仅具有竞争力,有时甚至超越了在相同基础模型上构建的最先进强化学习推理模型(SOTA)。值得注意的是,Tina 实现这一性能仅消耗现有 SOTA 模型后训练计算成本的极小一部分。事实上,性能最优的 Tina 模型在 AIME24 基准上提升了超过 20% 的推理表现,Pass@1 准确率达到 43.33%,后训练与评估成本仅为 9 美元(约为传统方法成本的 1/260)。
我们的工作揭示了使用 LoRA 实现高效强化学习推理的惊人有效性。我们在多个开源推理数据集和不同消融实验设置中验证了这一点,均基于一组固定的超参数。
此外,我们提出,该方法之所以高效,可能归因于 LoRA 能快速引导模型适应由 RL 奖励机制所鼓励的推理结构格式,同时在很大程度上保留了基础模型原有的知识。 为促进研究开放性与可复现性,我们已完整开源所有代码、训练日志、模型权重与检查点文件。
1 引言
语言模型(Language Models,LMs)在多种任务中表现出日益增强的能力,但在实现稳健的多步推理方面仍面临挑战(Wang 和 Neiswanger, 2025;Xu 等, 2025)。推理能力对于许多需要复杂问题求解的应用至关重要,如科学发现、复杂规划等。通过监督微调(Supervised Fine-Tuning, SFT)增强复杂推理能力是目前常见的做法,通常依赖于知识蒸馏过程(Min 等, 2024;Huang 等, 2024),模型通过模仿更强模型(如 OpenAI 的 o1,2024)生成的推理轨迹(例如逐步思考)来进行学习。这种方法虽然有效,但依赖于高质量的专家演示,这些演示通常获取成本高昂。此外,这种模仿过程也可能导致模型仅习得表层的“复制”,而非发展出动态推理路径的能力。 相比之下,强化学习(Reinforcement Learning, RL)允许模型直接从可验证的奖励信号中灵活学习(DeepSeek-AI, 2025;Lambert 等, 2025),促使模型探索更多逻辑路径,甚至可能发现更具鲁棒性的解法。然而,传统的 RL 流程通常结构复杂,且极为耗费计算资源。这也引出了我们研究的核心问题: 如何以更低成本有效地通过强化学习赋予语言模型推理能力?
为解答这个问题,我们有意选择极简化路径。与动辄数百亿参数的大模型(如 Qwen-7B/32B、QwQ-32B-preview 等 [Min 等, 2024;NovaSky Team, 2025;Zeng 等, 2025;Muennighoff 等, 2025;Cui 等, 2025;Lyu 等, 2025;OpenThoughts Team, 2025;Hu 等, 2025])不同,我们聚焦于小型模型,尤其选用 DeepSeek-R1-Distill-Qwen-1.5B(参数规模仅 15 亿)作为基础模型。该模型因其基因(来自 DeepSeek/Qwen 系列)和蒸馏过程,预期具备比同规模通用预训练模型更强的初始推理能力。这一战略性选择有助于更严格地评估 RL 的增量效果,从而更准确地量化 RL 技术本身的贡献。 更重要的是,选用小型架构显著降低了实验门槛。为了进一步提升 RL 阶段的效率,我们引入了低秩适配(LoRA)(Hu 等, 2021)作为参数高效的后训练手段。LoRA 允许仅通过训练极少量的新参数改变模型行为,与我们追求以最经济方式实现推理能力的核心动机高度契合。 通过将“小模型架构”与“LoRA 强化学习微调”结合,我们提出了 Tina 模型家族(Tiny Inference Architecture),实现了在极低成本下的显著推理性能。我们工作贡献如下:
**• 高效 RL 推理的显著效果
我们展示了 Tina 模型在推理任务中的表现可媲美,甚至在某些情况下超越,在相同基础模型上使用全参数训练的最先进 RL 模型(详见图1与表3)。特别是,性能最优的 Tina 模型在 AIME24 基准上获得 超过 20% 的推理性能提升,Pass@1 准确率达 43.33%。
**• 快速适应推理格式的假设
根据 Tina 模型后训练阶段的表现,我们提出假设:LoRA 的效率与效果源于其在 RL 过程中能够快速适应推理输出格式,同时在很大程度上保留基础模型的原始知识。相较于全参数训练中需要的深层知识整合,这是一种更具计算效率的推理增强方式。我们通过只训练 LoRA 参数来测试该假设,表明仅适配推理格式即可获得显著推理能力提升的可能性。这一发现也与近期研究一致——小模型在推理任务上依旧表现出色(Hugging Face, 2025;DeepSeek-AI, 2025),而大模型更适合存储世界知识(Allen-Zhu 和 Li, 2025)。
**• 推理强化学习的民主化路径
我们提供了一种可复现、极具成本效益的方法,降低了进入 RL 推理研究的门槛。最优 Tina 模型的复现成本仅为 9 美元,而重现本文全部实验与分析的总成本也仅为 526 美元。为了推动研究开放,我们已完整开源代码、训练日志、评估脚本及所有模型权重与检查点。