

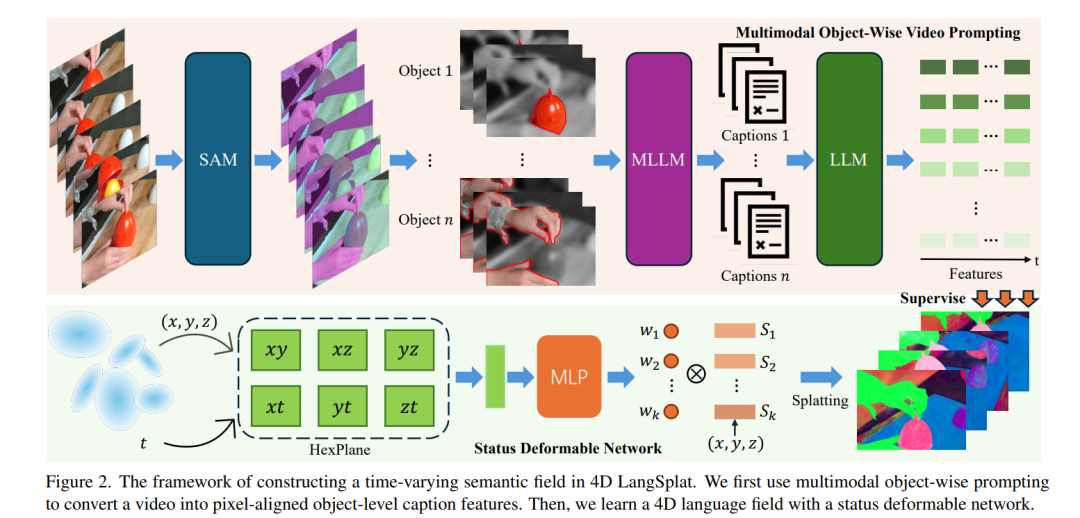
学习4D语言场以实现动态场景中时间敏感且开放式的语言查询,对于许多实际应用至关重要。尽管LangSplat成功地将CLIP特征嵌入到3D高斯表示中,在3D静态场景中实现了精度和效率,但它无法处理动态4D场,因为CLIP是为静态图像-文本任务设计的,无法捕捉视频中的时间动态。现实世界环境本质上是动态的,对象语义会随时间演变。构建精确的4D语言场需要获取像素对齐的、对象级别的视频特征,而当前的视觉模型难以实现这一点。为了解决这些挑战,我们提出了4D LangSplat,它通过学习4D语言场来高效处理动态场景中时间无关或时间敏感的开放词汇查询。4D LangSplat绕过了从视觉特征中学习语言场的过程,而是直接通过多模态大语言模型(MLLMs)从对象级别的视频描述生成的文本中学习。具体而言,我们提出了一种多模态对象级别视频提示方法,包括视觉和文本提示,指导MLLMs为视频中的对象生成详细、时间一致且高质量的描述。这些描述通过大语言模型编码为高质量的句子嵌入,随后作为像素对齐的、对象特定的特征监督,通过共享嵌入空间促进开放词汇文本查询。认识到4D场景中的对象在不同状态之间表现出平滑过渡,我们进一步提出了一种状态可变形网络,以有效建模这些随时间变化的连续状态。我们在多个基准测试中的结果表明,4D LangSplat在时间敏感和时间无关的开放词汇查询中均实现了精确且高效的结果。
成为VIP会员查看完整内容