语言模型(LMs)显著推动了自然语言处理的发展,并在多个领域取得了卓越进展。然而,其“黑箱”特性引发了关于其内部机制和决策过程可解释性的重大担忧。这种缺乏透明性的问题在高风险领域尤为突出,在这些场景下,相关利益方需要理解模型输出背后的逻辑,以确保问责性。另一方面,尽管可解释人工智能(XAI)方法在非语言模型的背景下已得到广泛研究,但在应用于语言模型时却面临诸多局限。这主要源于语言模型复杂的体系结构、庞大的训练语料以及广泛的泛化能力。现有的多项综述虽已探讨了语言模型中的XAI,但往往未能充分捕捉因架构多样性与模型能力演进所带来的独特挑战。为弥补这一空白,本综述系统梳理了针对语言模型的XAI技术,并特别依据其底层的Transformer架构类型(仅编码器、仅解码器以及编码器-解码器)进行组织,分析了方法在不同架构下的适配方式,并评估了其各自的优势与局限。此外,我们从合理性(plausibility)与忠实性(faithfulness)两个维度对这些技术进行评价,从而提供一个结构化的视角来考察其有效性。最后,我们指出了开放的研究挑战,并展望了潜在的未来发展方向,旨在为持续推进健壮、透明且可解释的语言模型XAI方法提供指导。
1 引言
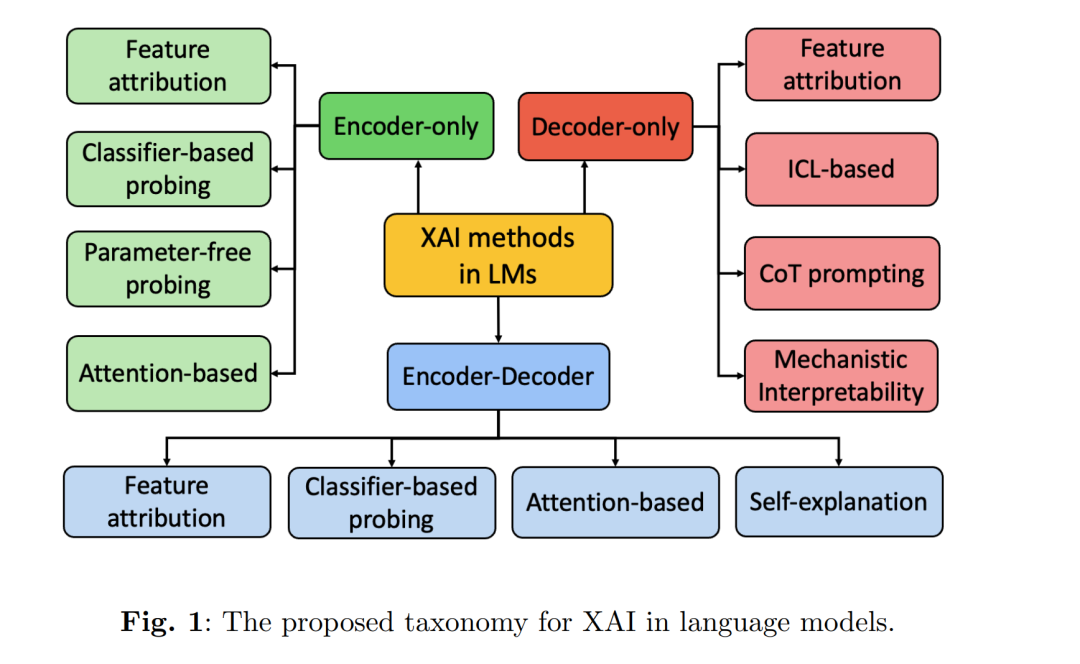
在不断发展的自然语言处理(NLP)领域,语言模型(LMs),如 BERT [1]、T5 [2]、GPT-4 [3] 和 LLaMA-2 [4],在机器翻译、代码生成、医疗诊断以及个性化教育等广泛任务与应用场景中展现了显著进展 [5–8]。尽管取得了这些突破,LMs 由于其庞大的参数规模、海量的训练数据以及复杂的体系结构,天然具有“黑箱”特性,使得理解其内部机制和决策过程变得十分困难 [9]。这种缺乏透明性的情况带来了若干关键限制,包括信任度下降、问责性减弱,以及在识别偏差或调试输出错误时的难度增加。因此,当 LMs 部署在医疗、金融和法律等高风险领域时,这些挑战尤为关键,因为在这些场景中透明性和问责性至关重要,错误可能导致严重后果 [9–11]。 另一方面,为增强非语言模型领域的透明性与问责性而发展出的可解释人工智能(XAI)方法已得到广泛研究 [12–15]。例如,特征归因技术(feature attribution),如 Integrated Gradients [16],在非语言模型任务中被广泛用于解释模型预测,其方法是量化单个输入特征对预测结果的贡献。然而,直接将这些方法应用于 LMs 却面临困难,原因在于其庞大的参数规模和广泛的泛化能力 [17]。这促使研究者设计专门面向 LMs 的 XAI 方法。例如,Chain-of-Thought(CoT)提示 [18, 19] 通过暴露中间推理步骤提升透明性,而自解释(self-explanation)方法则在预测结果旁生成可读的自然语言解释 [20, 21]。虽然已有多项综述探讨了 LMs 中的 XAI,但它们往往忽视了由 Transformer 编码器与解码器不同组合所带来的架构特定挑战 [22–26]。由于每种架构在处理和表征信息方式上各不相同 [27],这些差异导致了可解释性问题的显著差异。因此,需要一个统一的框架,系统性地考察跨架构的 XAI 方法,并应对 LMs 带来的独特可解释性挑战。 为此,本文综述了面向语言模型的 XAI 方法,按照其底层 Transformer 架构进行组织,讨论了相关的评价机制,并指出了开放挑战与未来研究方向。据我们所知,这是首个针对 LMs 提出系统化框架的综述,围绕 Transformer 架构引入标准化的分类体系,分析架构特定挑战,并评估现有的解释性方法。通过从“架构感知”(architecture-aware)的角度对比不同的可解释性方法,本文提供了一个整体视角来审视当前方法及其有效性。本文的主要贡献如下: * 提出了一个基于底层 Transformer 架构的 LMs XAI 方法分类体系; * 对这些方法进行了比较分析,突出其关键特征与在不同设计选择下的局限性; * 探讨了解释方法的评估策略,强调从“忠实性(faithfulness)”与“合理性(plausibility)”双重视角来保证可靠性。