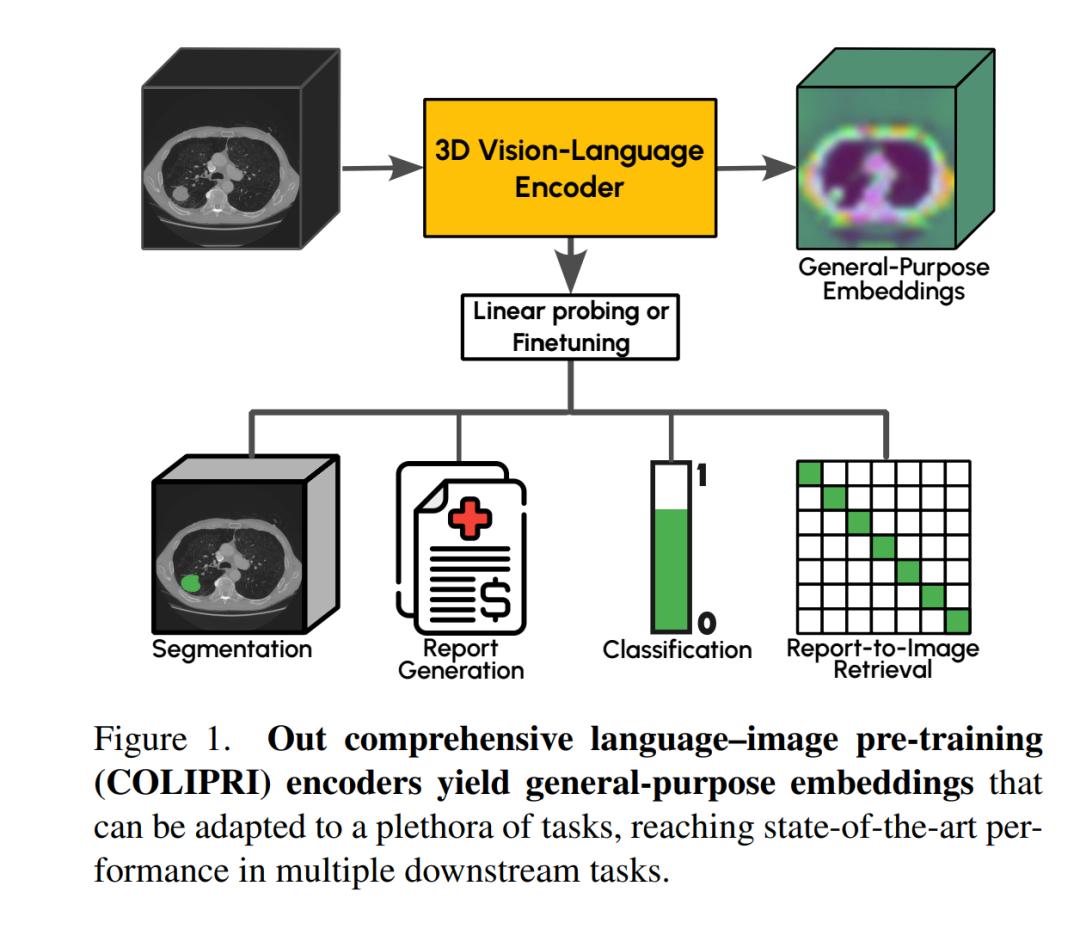
视觉–语言预训练(Vision–Language Pre-training),即通过对齐图像与配对文本,是一种强大的范式,可用于直接构建可执行分类与检索任务的编码器(encoder),并可进一步应用于分割与报告生成等下游任务。在三维医学影像领域,这类能力使视觉–语言编码器(Vision–Language Encoders,VLEs)能够辅助放射科医生完成诸如检索具有相似异常特征的患者或预测异常概率等任务。尽管这一方法论前景广阔,但当前三维 VLE 的能力仍受到数据可用性的限制。 在本文中,我们通过引入额外的归纳偏置(inductive biases)来缓解数据稀缺的问题:提出了报告生成目标,并将视觉–语言预训练与仅视觉预训练相结合。这一设计使我们能够同时利用仅含图像的数据集和图像–文本配对的三维数据集,从而显著增加模型可接触的训练数据量。借助这些额外的归纳偏置,并结合三维医学影像领域的最佳实践,我们提出了综合语言–图像预训练(Comprehensive Language–Image Pre-trained, COLIPRI)编码器系列。我们的 COLIPRI 编码器在报告生成、分类探测(classification probing)和零样本分类(zero-shot classification)等任务上均达到了最新的性能水平,并在语义分割任务上保持了具有竞争力的表现。1. 引言 对比式语言–图像预训练(Contrastive Language–Image Pre-training,CLIP)[31] 已经成为学习通用图像与文本表征的最强范式之一。除了作为适应下游任务 [11, 23] 的强大起点外,语言对齐的视觉嵌入还能使模型利用自然语言执行开放集分类 [31] 与开放集分割 [55]。
在三维医学影像领域,这一训练范式尤为相关,原因在于: i) 在临床环境中,每一份影像通常都伴随着医生的诊断报告。因此,这类配对数据在医院中非常丰富,尽管出于隐私考虑,这些报告很少被公开共享。 ii) CLIP 的目标函数将影像的全局表征与其对应报告进行对齐,使模型能够通过学习到的潜在表征实现多模态检索(文本到图像、图像到文本)。这种语义检索功能可为放射科医生提供一组有价值的参考病例,从而辅助诊疗决策或作为教学工具。 iii) 模型的零样本分类(zero-shot classification)能力能够以快速且低成本的方式提供初步诊断意见 [52]; iv) 零样本分割(zero-shot segmentation)则能够在扫描图像上对决策进行定位,使临床医生能更直观地验证或否定模型的建议。
尽管潜力巨大,医学影像领域的视觉–语言预训练研究尚不如通用领域成熟。像 CLIP [31]、Perception Encoder [5] 或 SigLIP 2 [43] 等方法已在通用领域确立地位,而三维医学视觉–语言编码器(VLEs)[3, 12] 直到最近才开始受到关注。我们认为主要原因在于两点: 1)医学领域缺乏大规模、公开可用的数据集; 2)该领域在模态与工程实现上存在特定的技术挑战。
在本研究中,我们展示了如何通过图像–文本配对与仅图像的开放访问 CT 数据集,将视觉–语言预训练成功迁移至三维医学影像领域,从而应对上述问题。
**数据可用性
目前仅有的几种大规模三维图像–报告配对数据集包括: CT-RATE(2.5 万对图像–报告)[12]、INSPECT(1.9 万对)[15]¹、BIMCV-R(8 千对)[8],以及 Merlin 数据集(2.55 万对)[3]。 虽然这些数据集的规模在三维影像领域内已属可观,但它们总计约 7.8 万对图像–报告样本,仍远低于首个 CLIP 模型 [31] 所使用的 4 亿对图像–文本数据,更无法与 SigLIP 2 [43] 采用的 WebLI 数据集(包含 100 亿张图像和 120 亿条替代文本 [7])相比。 除配对报告数据外,大量未配对的医学图像也能显著扩充可用训练数据。例如:UK Biobank [20] 含有超过 10 万个全身 MRI 样本;NLST 数据集 [39] 含有 7.3 万个胸部 CT;OpenMind 数据集 [44] 则包含 11.4 万个三维脑 MRI 体积。² 虽然这些研究数据大多伴随临床报告采集,但报告未公开发布,因此仅含图像的数据集远比图像–报告配对数据丰富。
**工程挑战
三维医学影像的体素(voxel)数量通常比通用领域或二维医学影像的像素数量高出数个数量级。例如,一份典型的胸部 CT 体积包含约 512×512×200 个体素,使得在训练时以原始分辨率使用整幅影像几乎不可行,因为 VRAM 占用极高。若是全身 CT 扫描,切片数量甚至可超过一千张。 因此,通常采用两种策略: * 在图像的裁剪块(crop)上训练 [29, 34]; * 或使用下采样后的影像 [3, 12]。
前者会导致问题,因为临床报告往往描述整个体积,而不仅是某个局部视野(FOV);后者则可能丢失关键信息,影响对特定异常的检测。
**主要贡献
在本研究中,我们通过结合三维医学影像领域的最佳实践并引入多种归纳偏置(inductive biases),显著提升了当前三维医学视觉–语言模型的性能。我们的贡献可总结如下: 1. CLIP 范式的适配研究:在三维医学影像背景下,系统性分析 CLIP 训练范式中的关键设计选择,以最大化有限视觉–语言数据的价值。 1. 报告生成目标(RRG):引入类似 CapPa [42] 的放射学报告生成目标,以充分利用文本报告中丰富的监督信号。 1. 视觉自监督目标结合:在 CLIP 目标的基础上引入视觉自监督目标(类似 Maninis 等人 [24] 与 Naeem 等人 [26]),从而将未配对的图像纳入训练集,并提供更局部化的监督信号以支持密集型下游任务。
我们通过零样本分类、分类探测、报告生成与语义分割(见图 1)等任务对所得模型进行了全面评估,展示了当前编码器的优势与局限性。