小样本如何进行深度学习?西北工夏勇教授这一份54页《医学影像小数据深度学习》PPT为你讲解
【导读】基于神经网络的深度学习方法往往需要大量标注样本,而在很多领域往往是缺乏充足样本数据的,比如在医疗领域,高质量的医疗影像大数据样本很难获取,且人工标注成本较高,缺乏病理或手术金标准。因此,亟待研究基于小样本数据集或弱标签标注的深度学习方法。将小样本弱标签的医学影像数据应用于肿瘤鉴别诊断等实际医疗场景,对于提高医学诊断准确率,具有重要现实意义。小数据深度学习是当前的一个研究热点。西北工业大学夏勇教授在VALSE Webinar带来了《医学影像小数据深度学习》的分享报告,分析在医学影像“小数据”上进行深度学习研究所面临的挑战,也将介绍报告人在应用深度学习技术进行医学影像分析的经验和体会。是小数据医疗深度学习从业者不可多得的参阅材料。
本文获得VALSE授权转载并编辑!
http://valser.org/article-286-1.html

夏勇,男,西北工业大学教授、博导,分别于2001、2004和2007年从西北工业大学计算机学院获得学士、硕士和博士学位;2007年1月起,在悉尼大学信息技术学院生物医学与多媒体技术(BMIT)实验室开展博士后研究;2013年底回到西北工业大学计算机学院工作,现为西工大计算机学院多学科交叉计算研究中心执行主任;现主持国家自然基金面上项目两项,发表学术论文百余篇;担任中国计算机学会青工委委员、中国图象图形学学会视觉大数据专委会常委、中国体视学学会图像分析分会常委、陕西省抗癌协会肿瘤影像专业委员会青年委员会常委及智慧医疗组指导委员会主任委员等;并担任MICCAI-MCV15/16、MICCAI-DLMIA17/18、MICCAI-BIA18、ISBI 2017、ACM MM2018等多个国际会议的TCP或Session Chair。
个人主页:
http://jszy.nwpu.edu.cn/yongxia.html
《医学影像小数据深度学习》简介

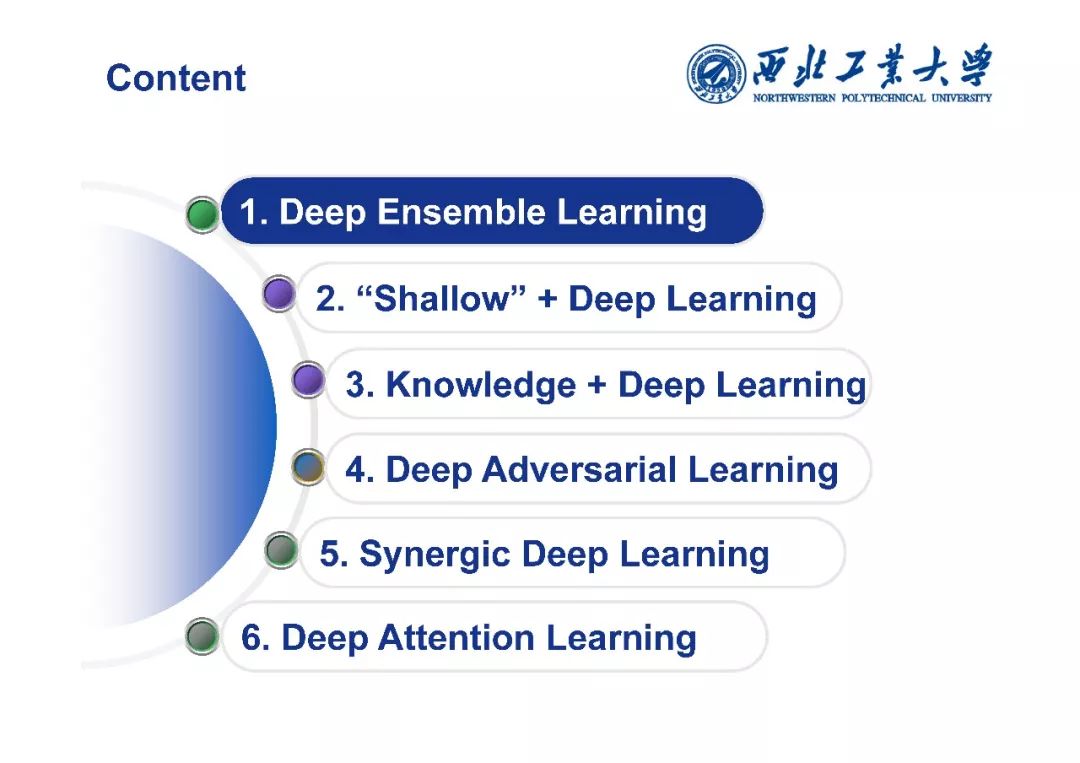
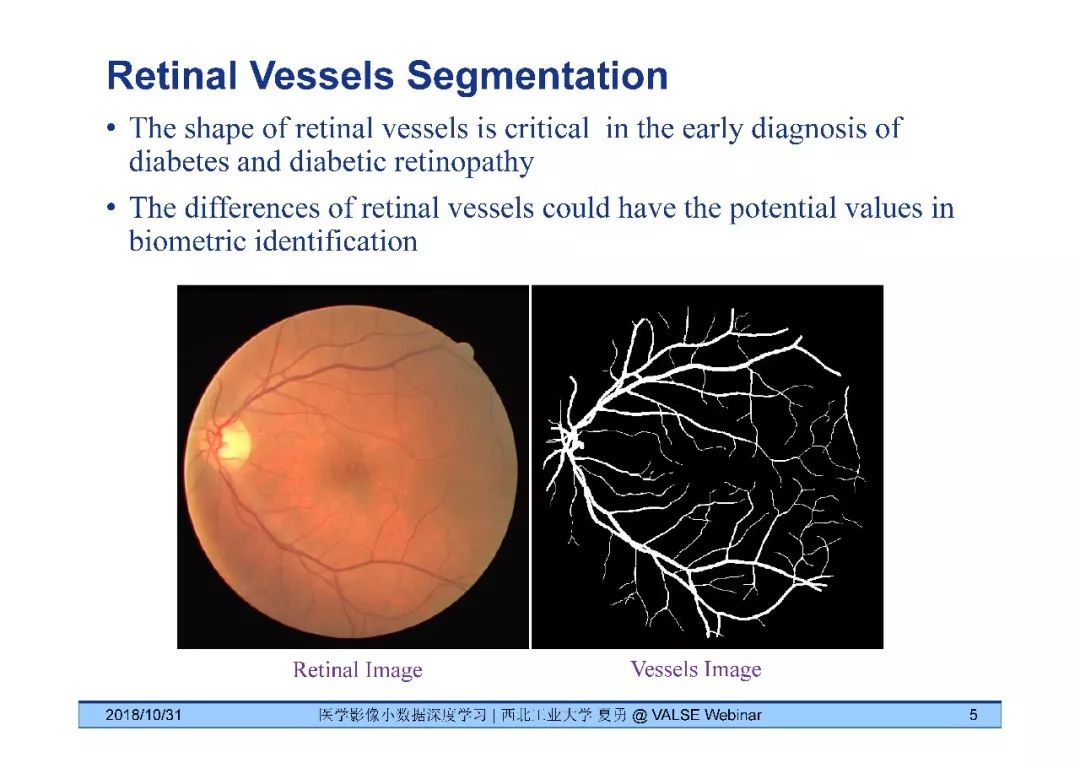
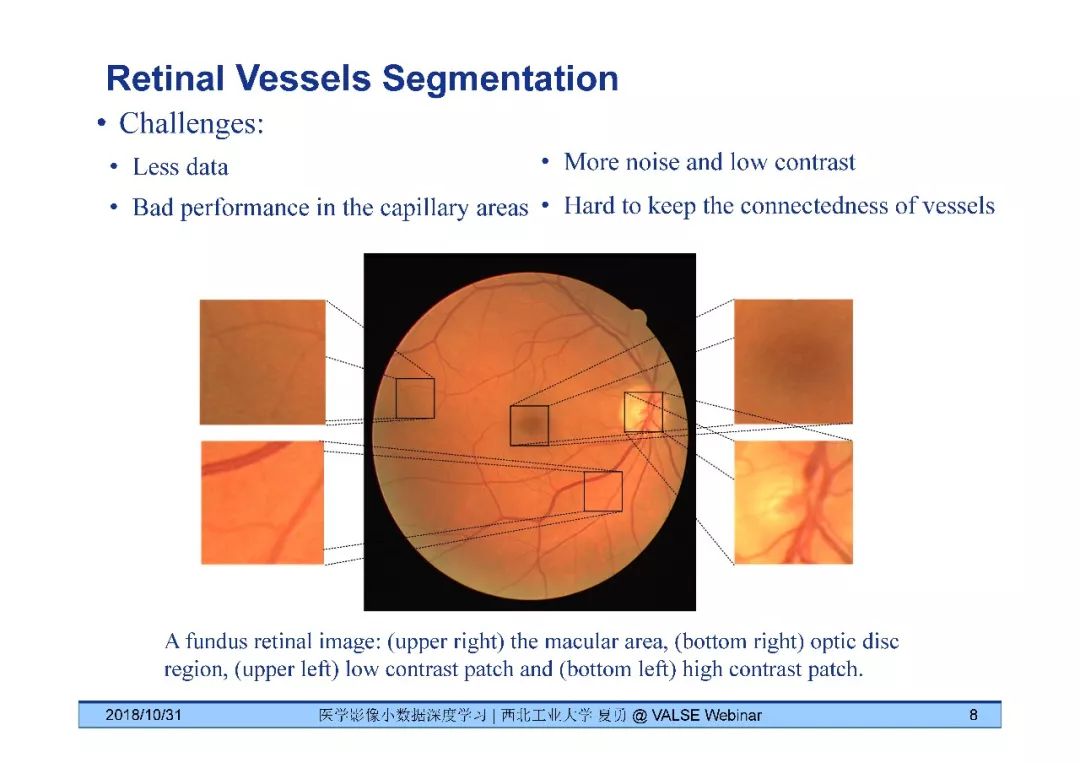
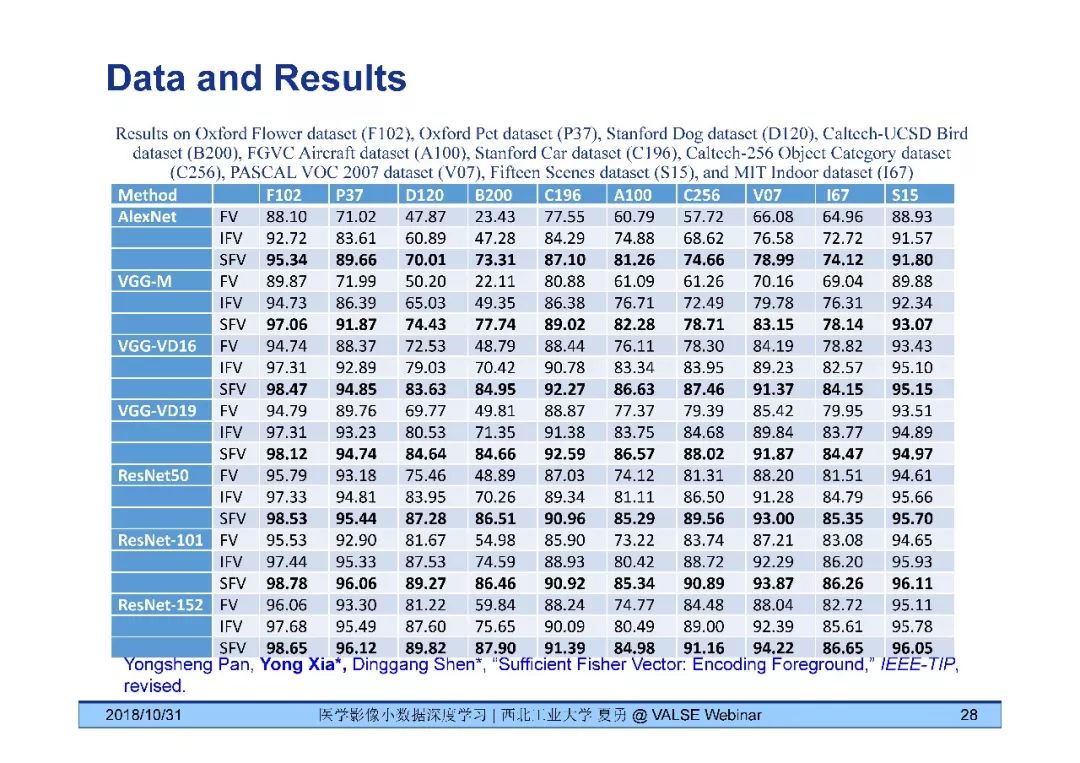
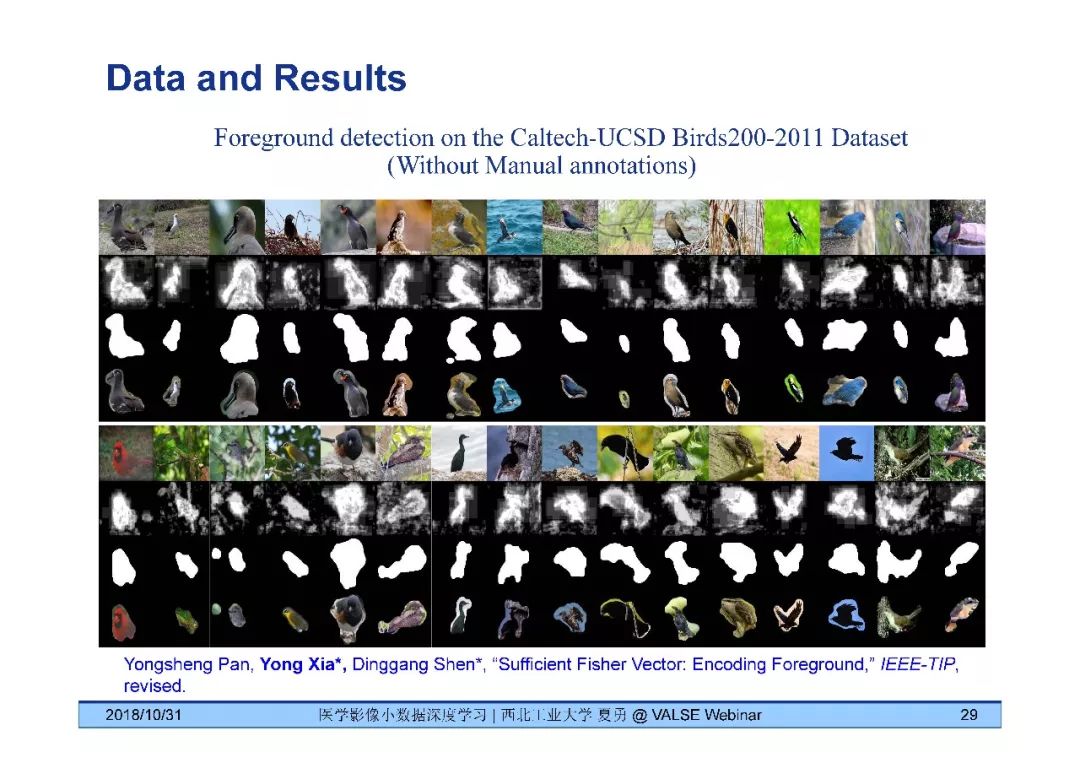
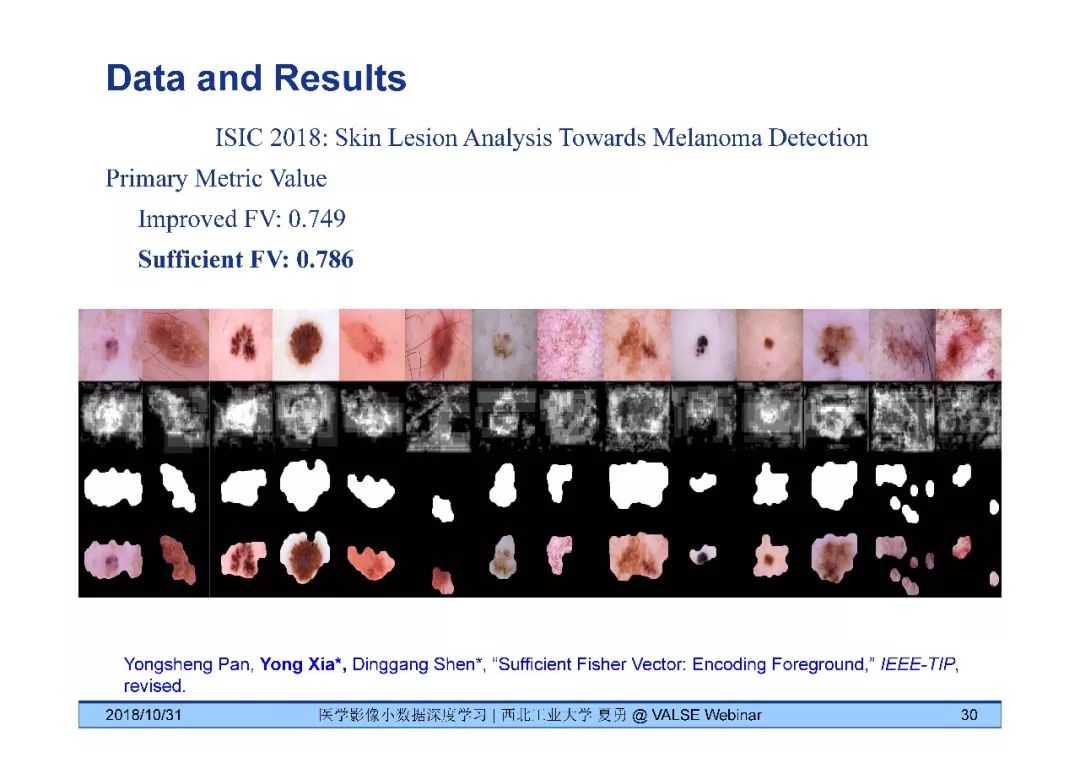
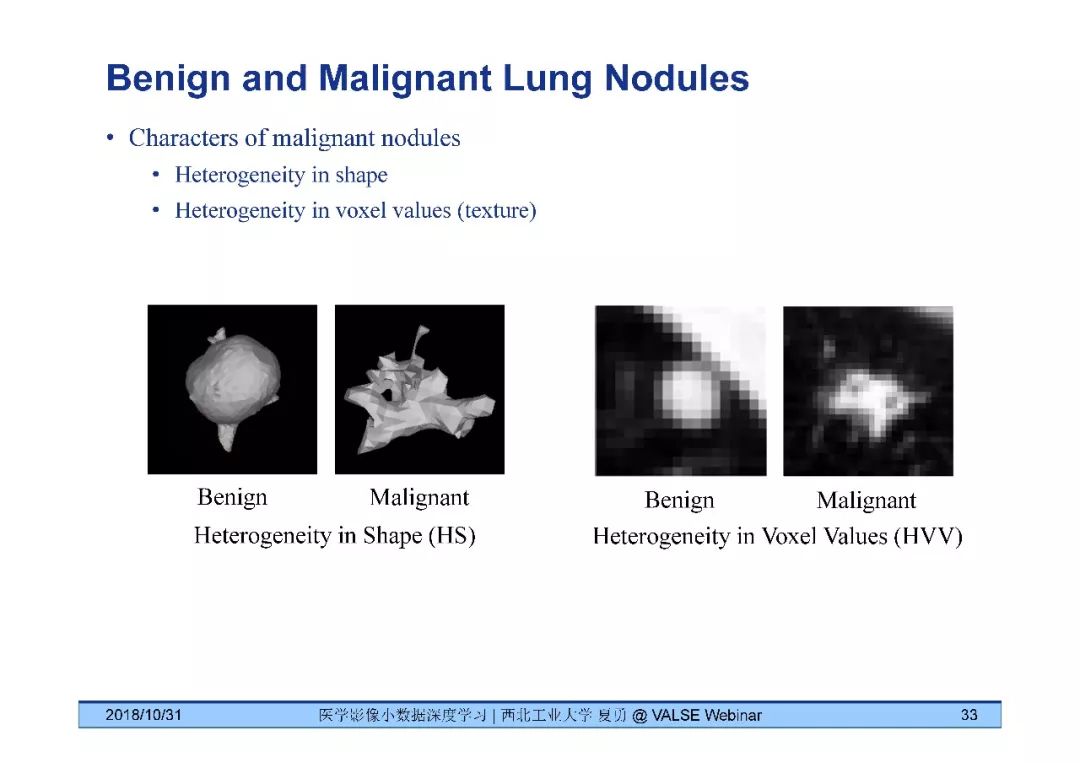
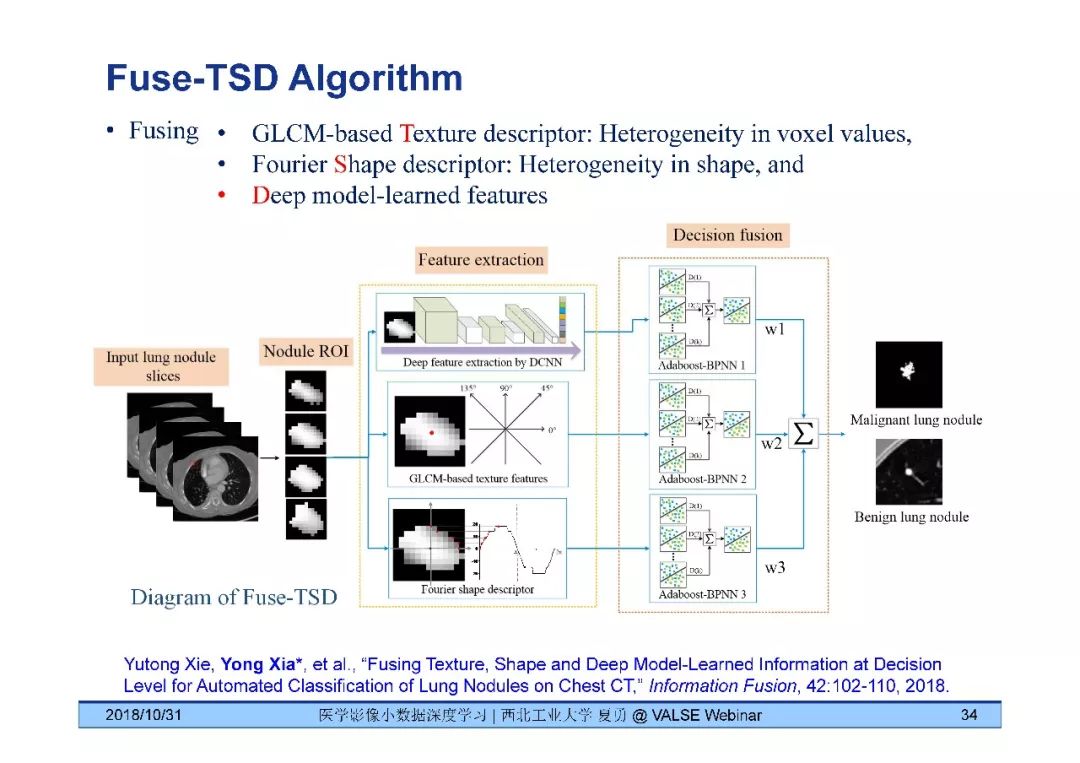
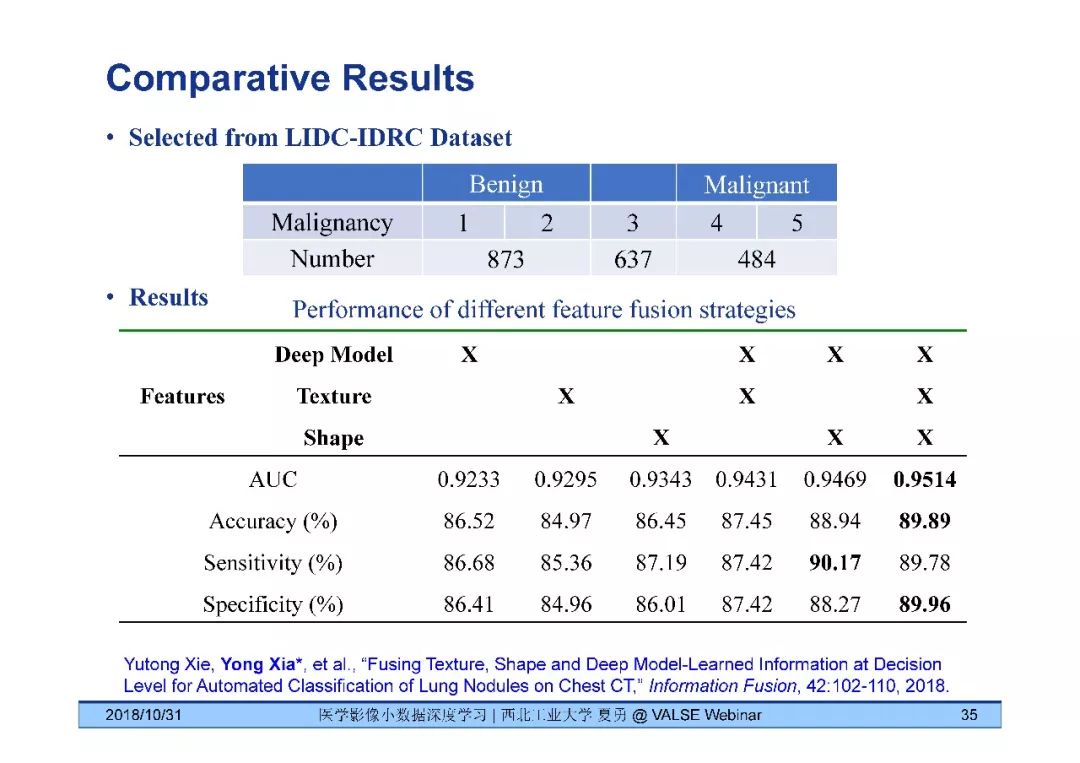
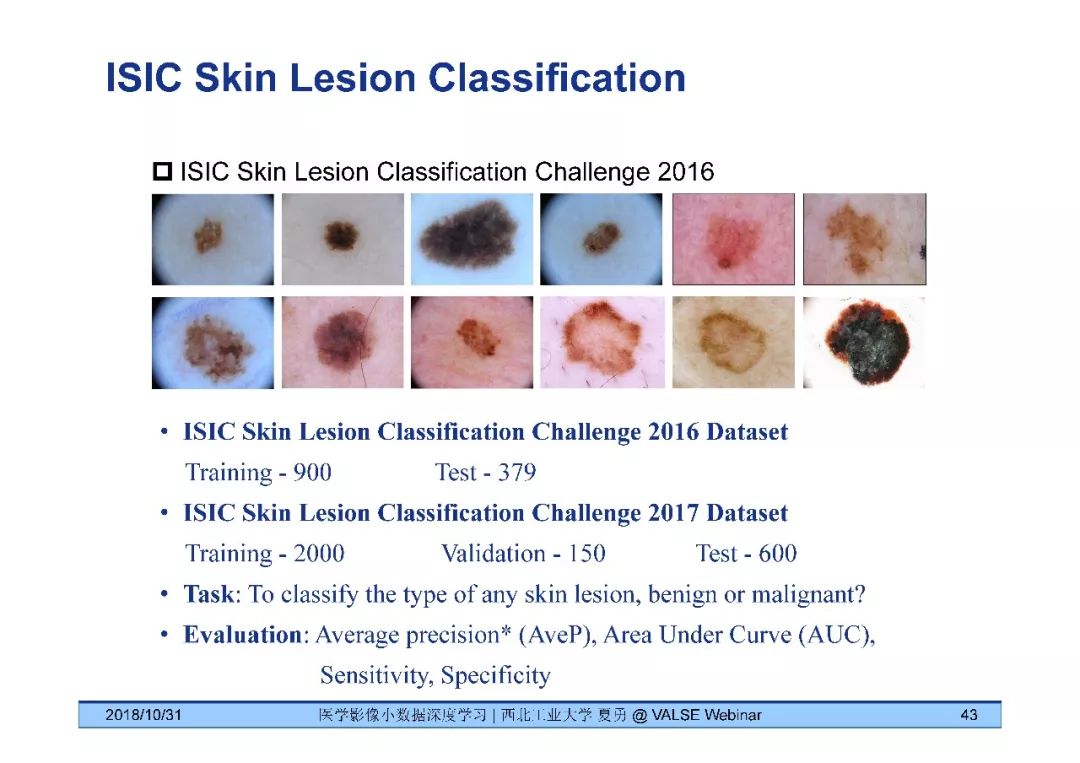
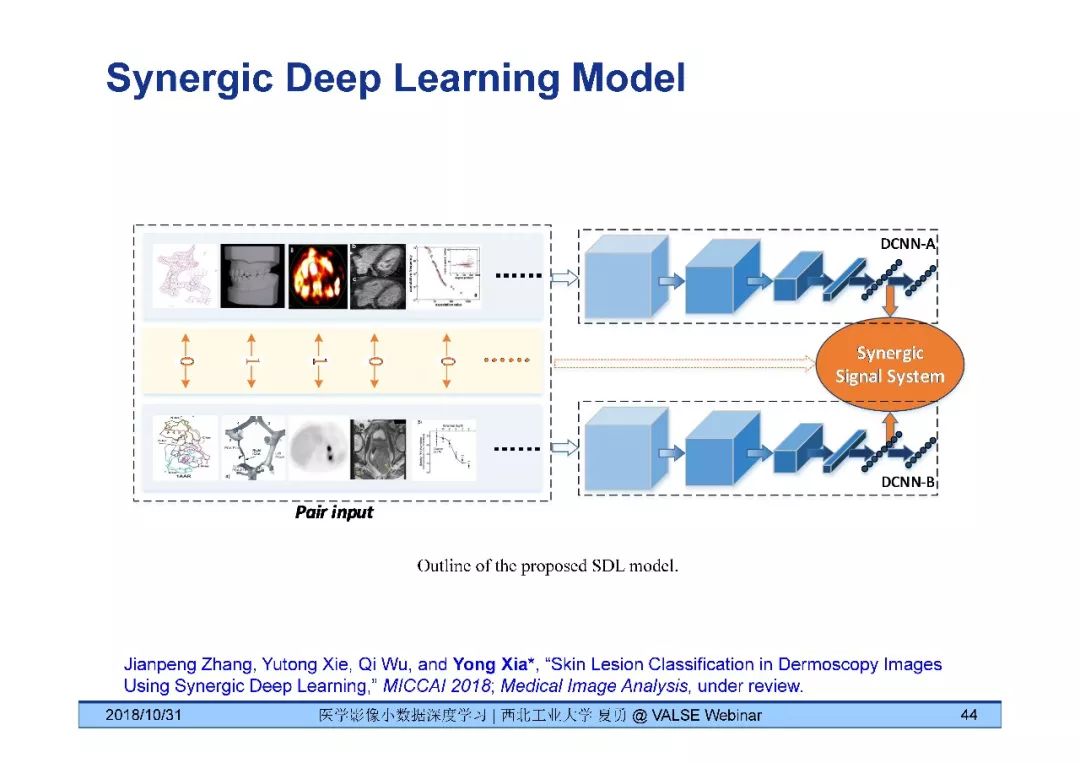
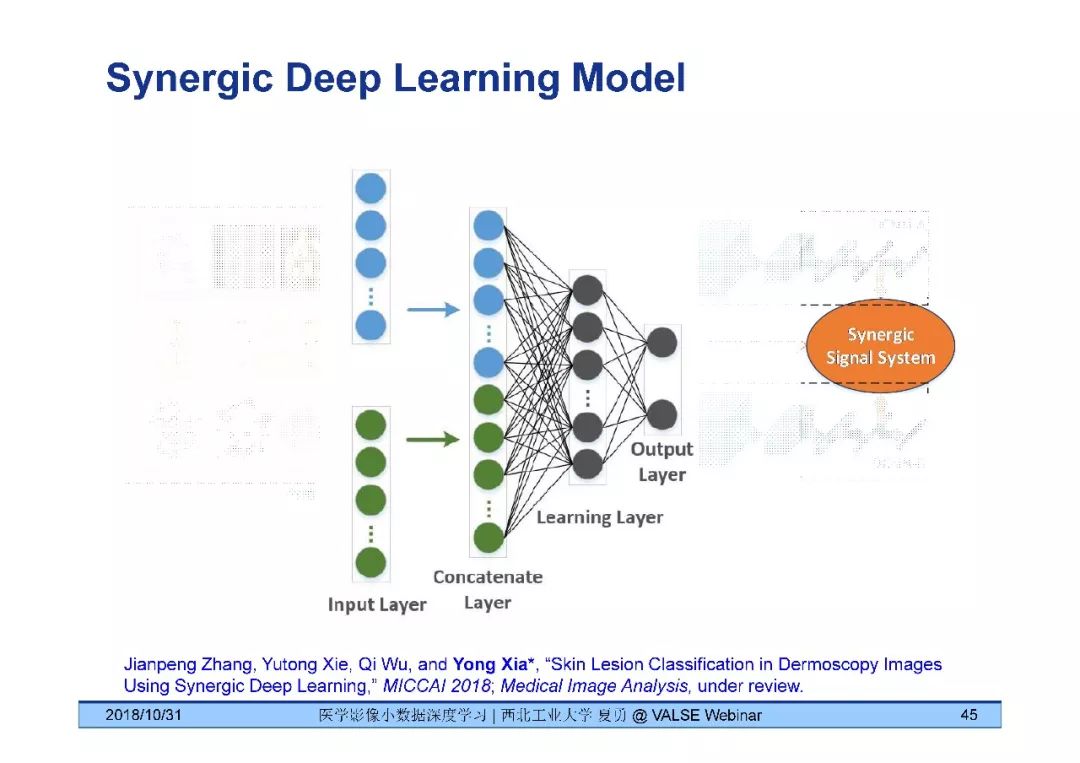
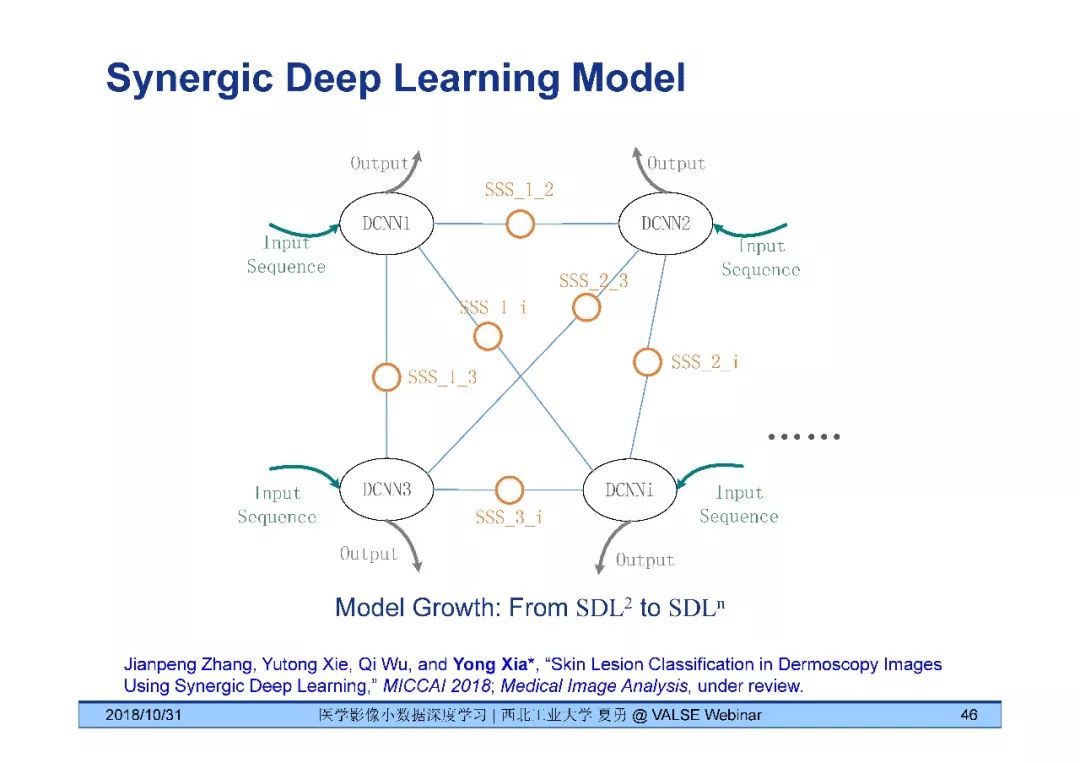
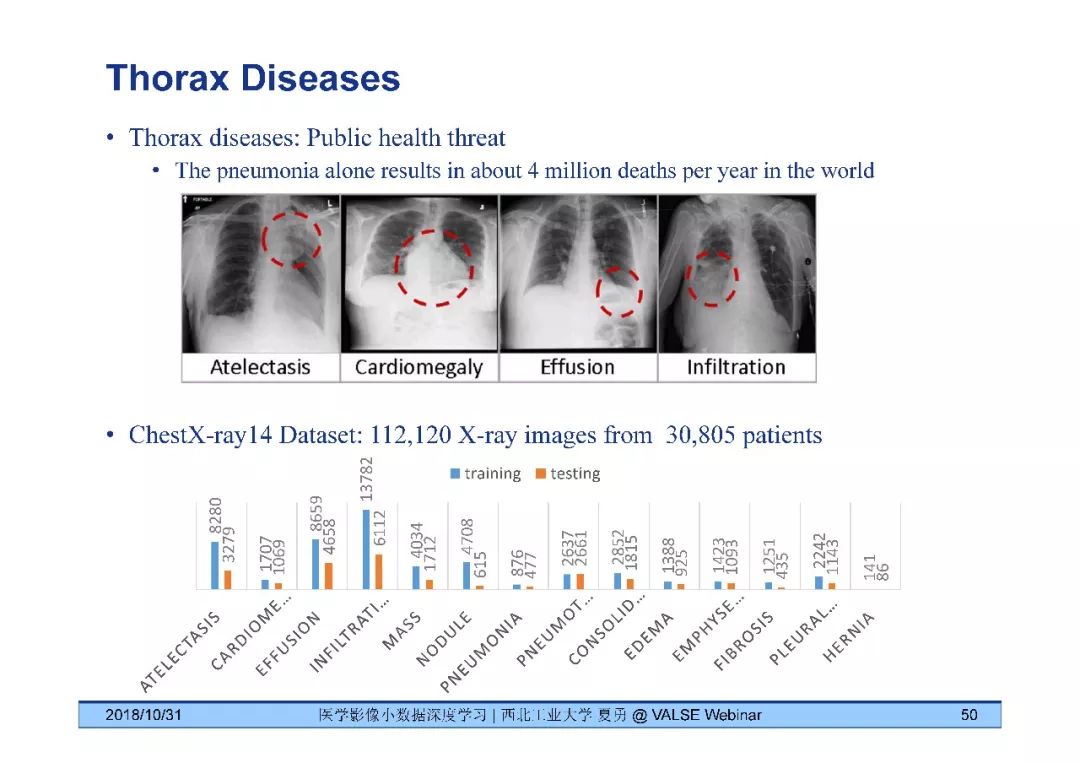
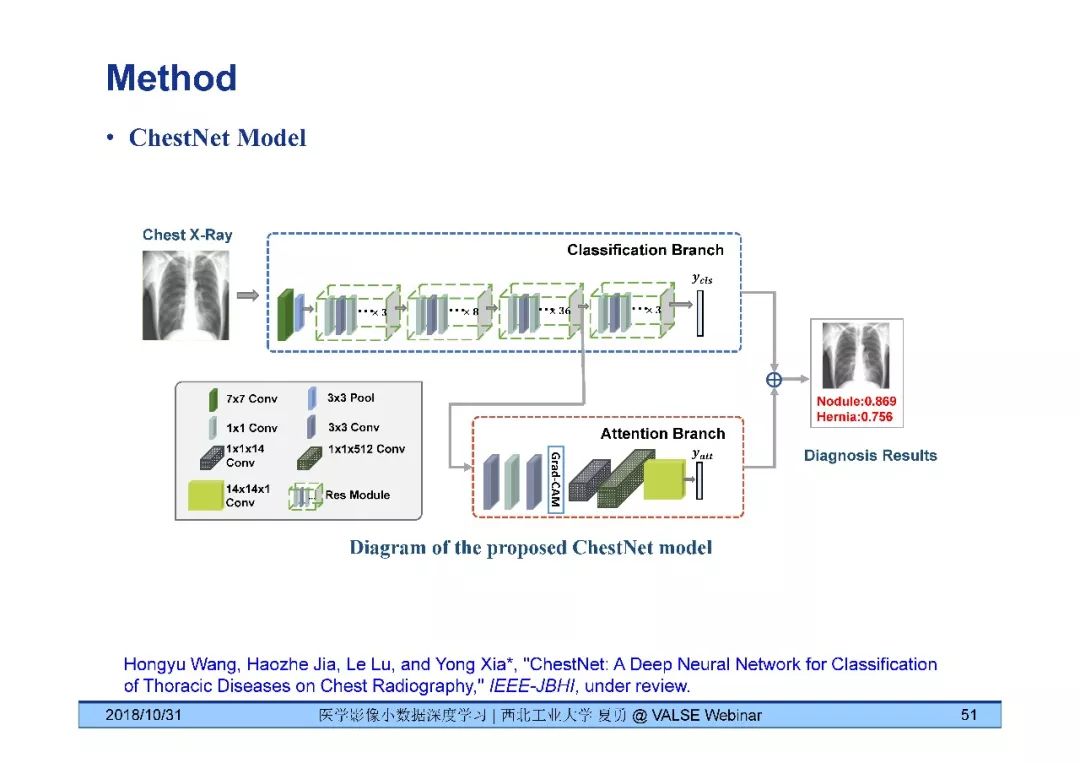
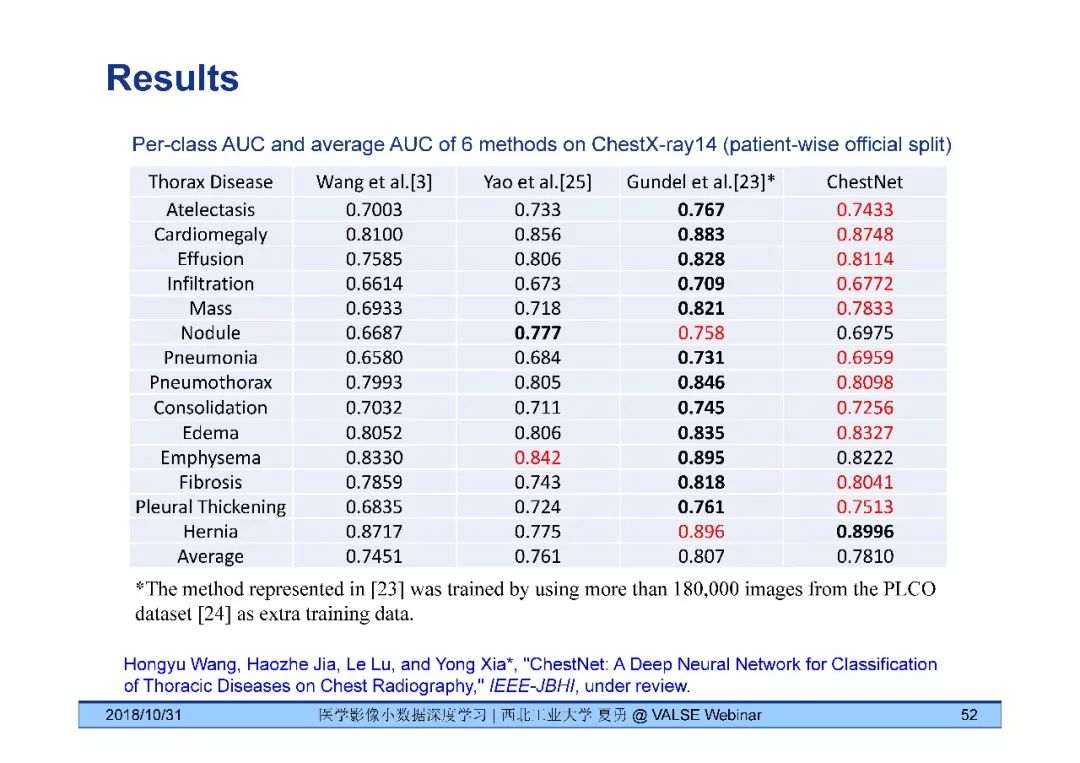
夏勇教授针对医学影像分析问题中数据量有限,无法发挥深度学习潜能的问题,介绍了六种应对的经验,包括使用:(1)并联或串联的深度集成学习、(2)与传统方法相结合的深度学习、(3)与领域先验知识相结合的深度学习、(4)深度对抗学习、(5)深度协同学习(Synergic Deep Learning)和(6)深度注意力学习,并以解决乳腺癌病理图像诊断、视网膜图像中血管分割、皮肤病诊断、肺结节良恶性诊断和基于X光胸片的14种肺部疾病诊断等问题为例,展示了上述策略在使用深度学习进行医学影像小数据分析时的性能。
请上夏老师主页获取讲义PPT或者
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“MSDL” 就可以获取《医学影像小数据深度学习》PPT下载链接~
《医学影像小数据深度学习》导读
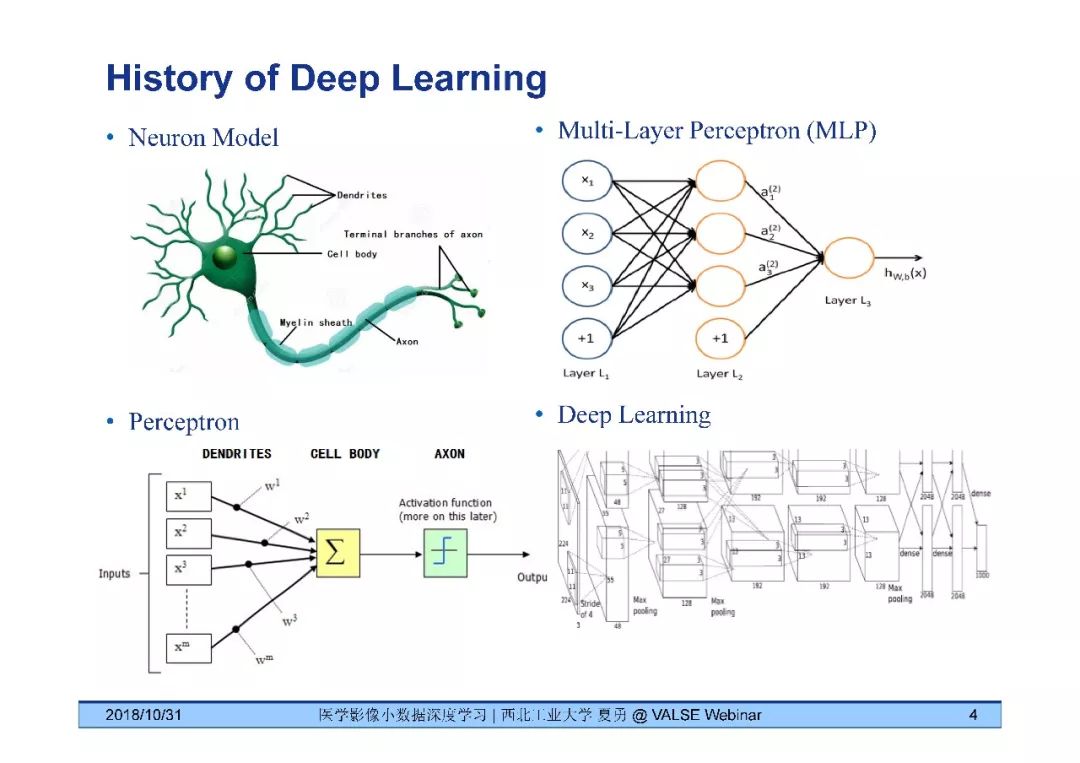
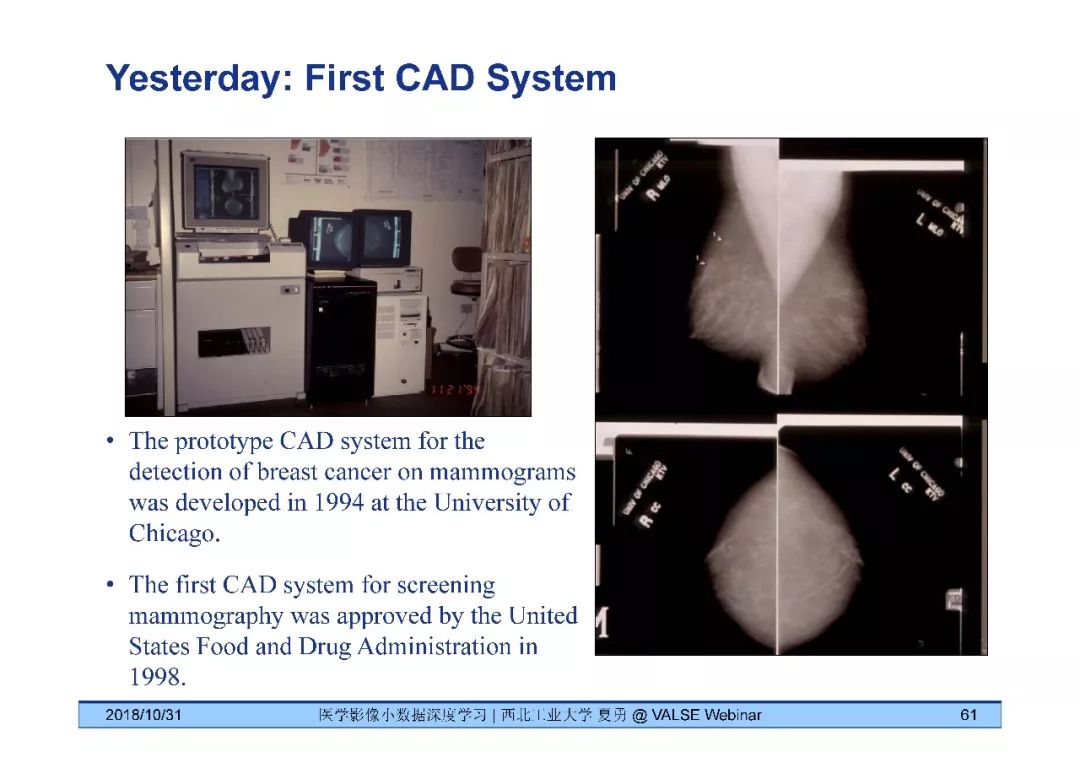
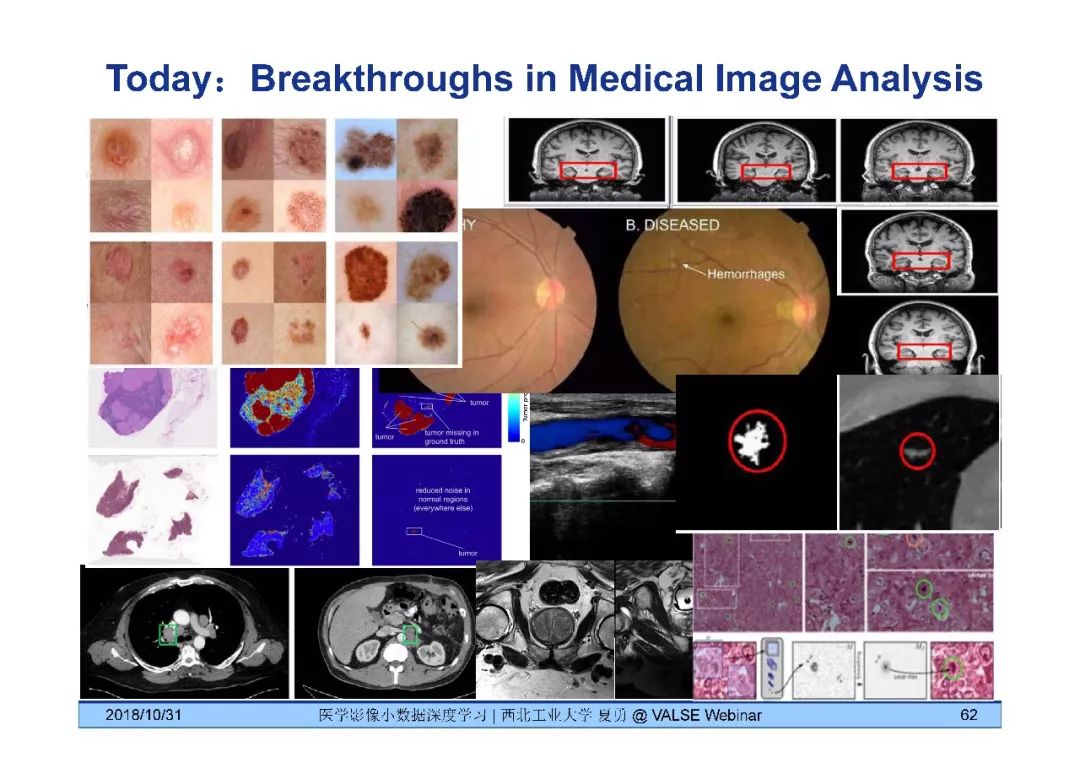
深度学习发展历史
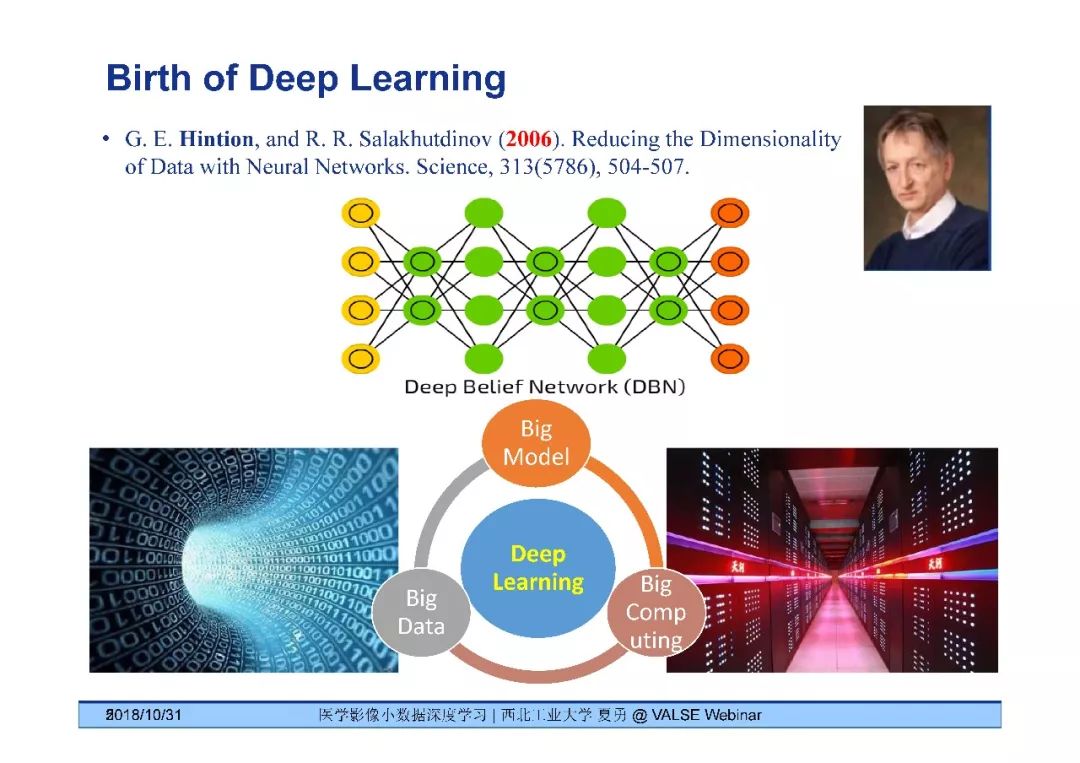
2006年Hinton开启深度学习
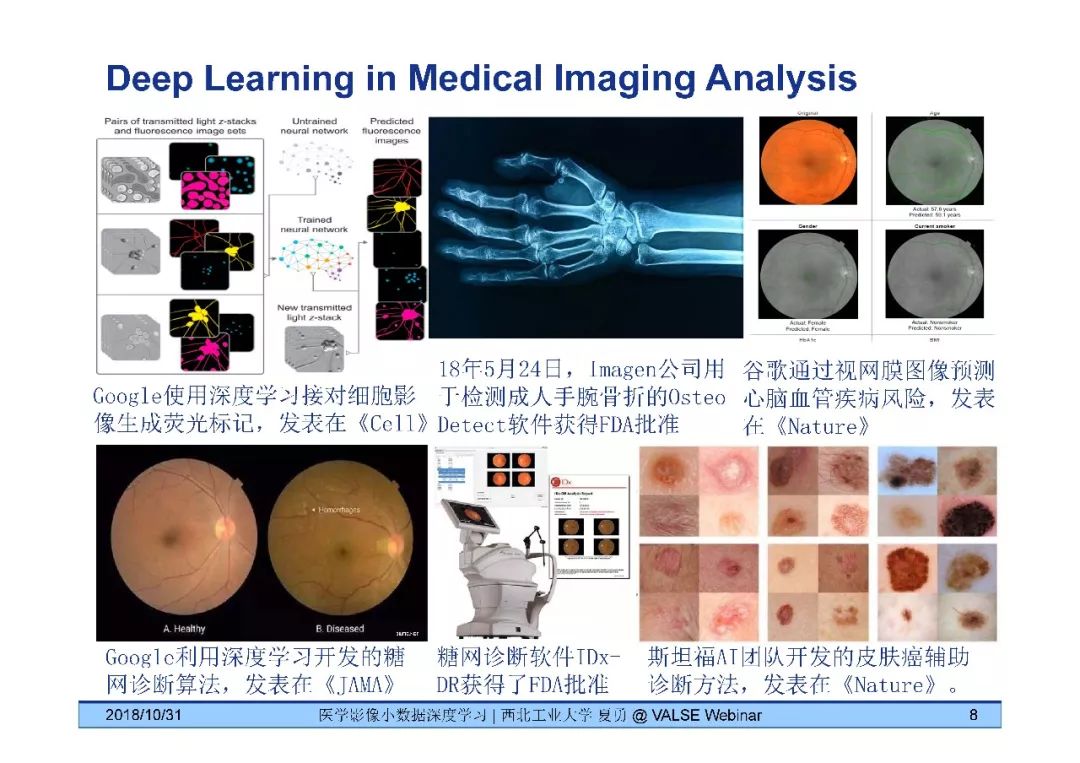
计算机视觉中的深度学习

医疗影像深度学习
报告目录内容:1)并联或串联的深度集成学习、(2)与传统方法相结合的深度学习、(3)与领域先验知识相结合的深度学习、(4)深度对抗学习、(5)深度协同学习(Synergic Deep Learning)和(6)深度注意力学习




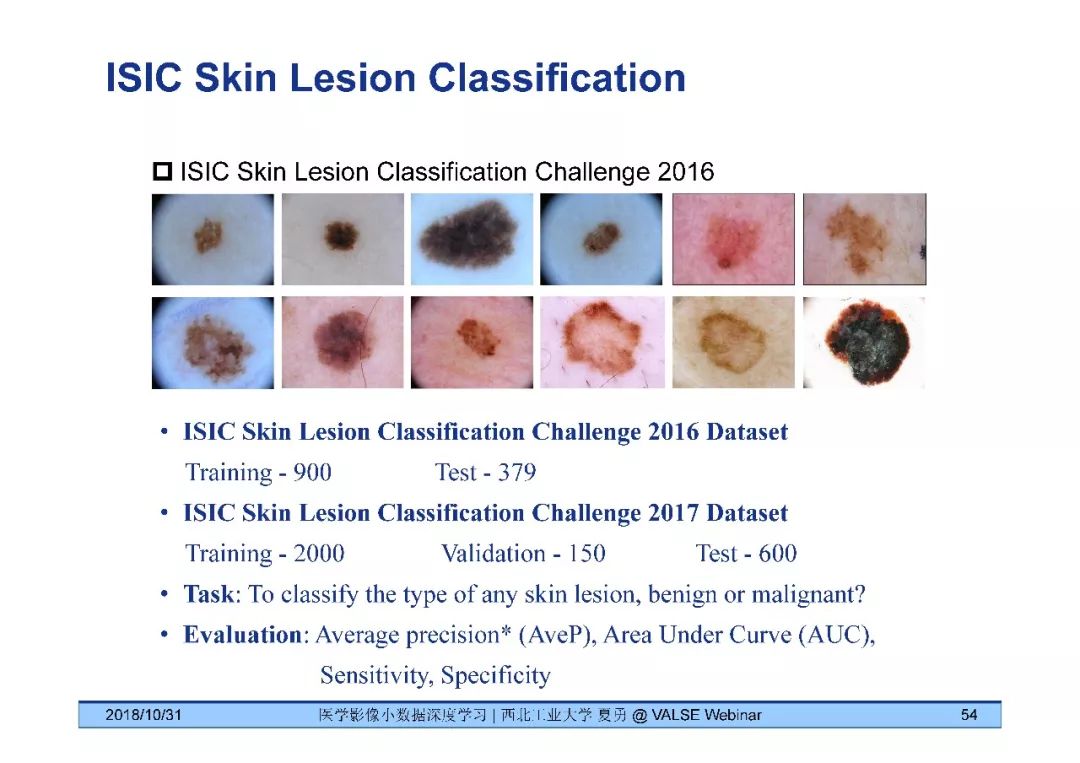
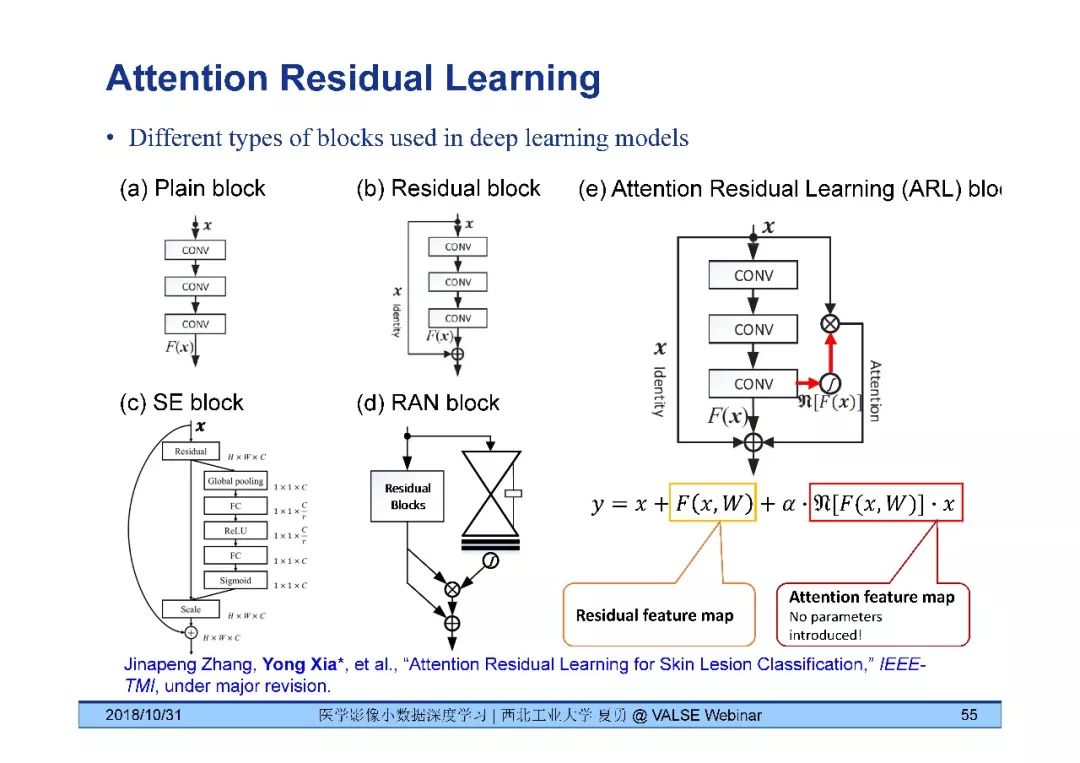
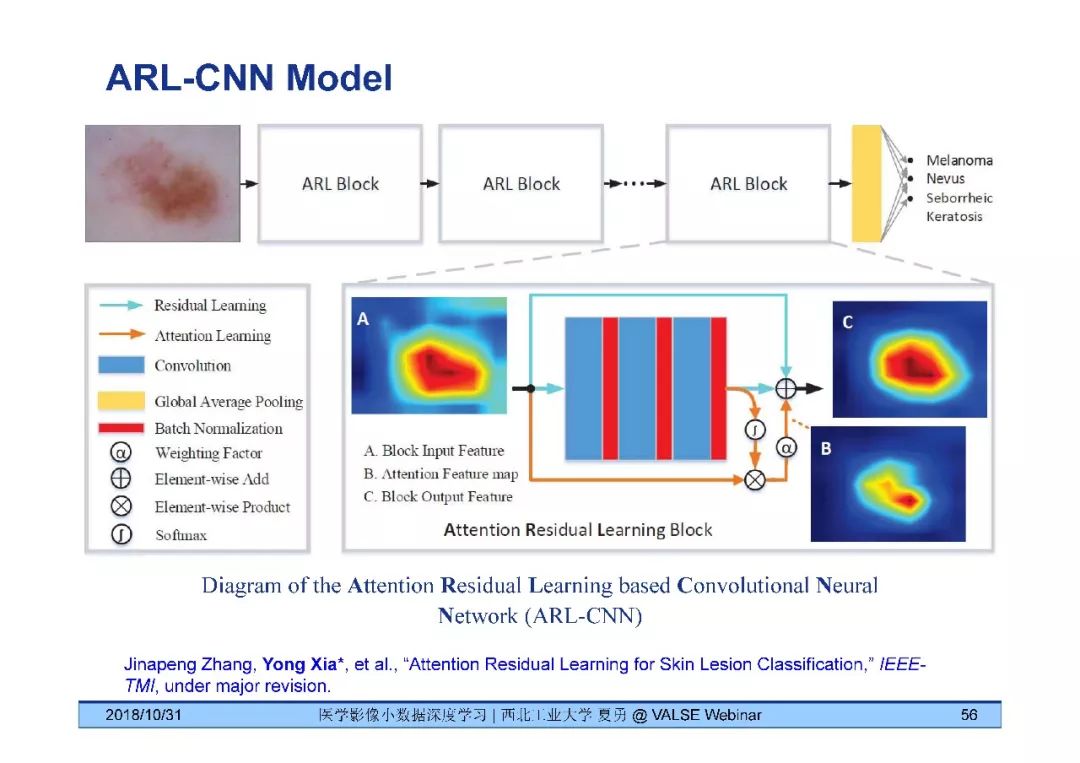
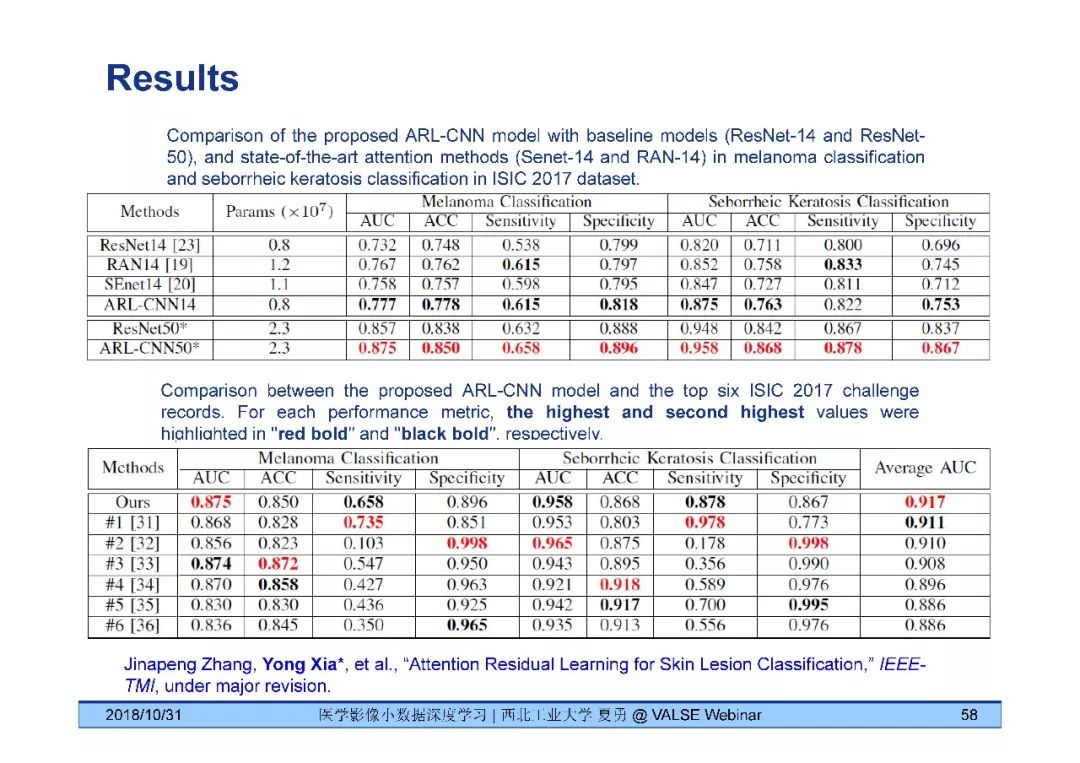




《医学影像小数据深度学习》问答
问答部分:
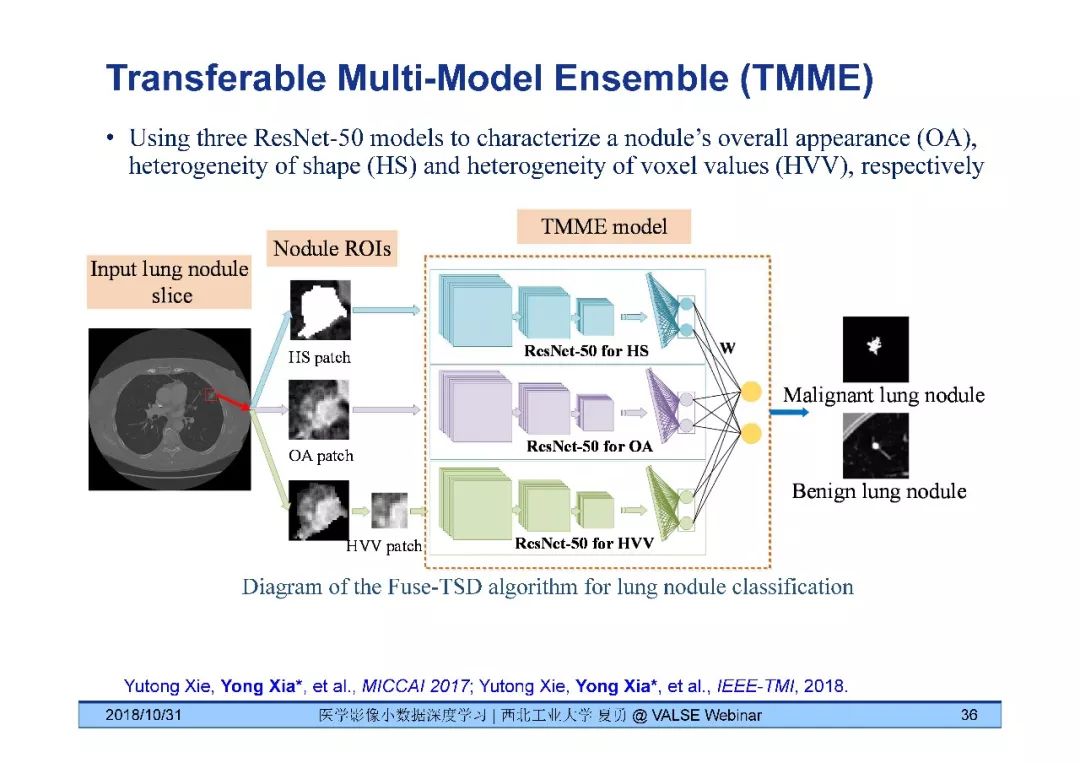
问题1:TMME的学习方法和Mask R-CNN的方式区别?
回答:TMME和Mask R-CNN这两种模型还是有些不一样的。Mask R-CNN模型可以检测目标,还可以对目标做分割;而TMME模型的主要任务是分类,可以看成是三个分类网络的集成,即分别从三个角度(纹理、形状和整体)提取图像信息,然后综合利用这些信息做分类。
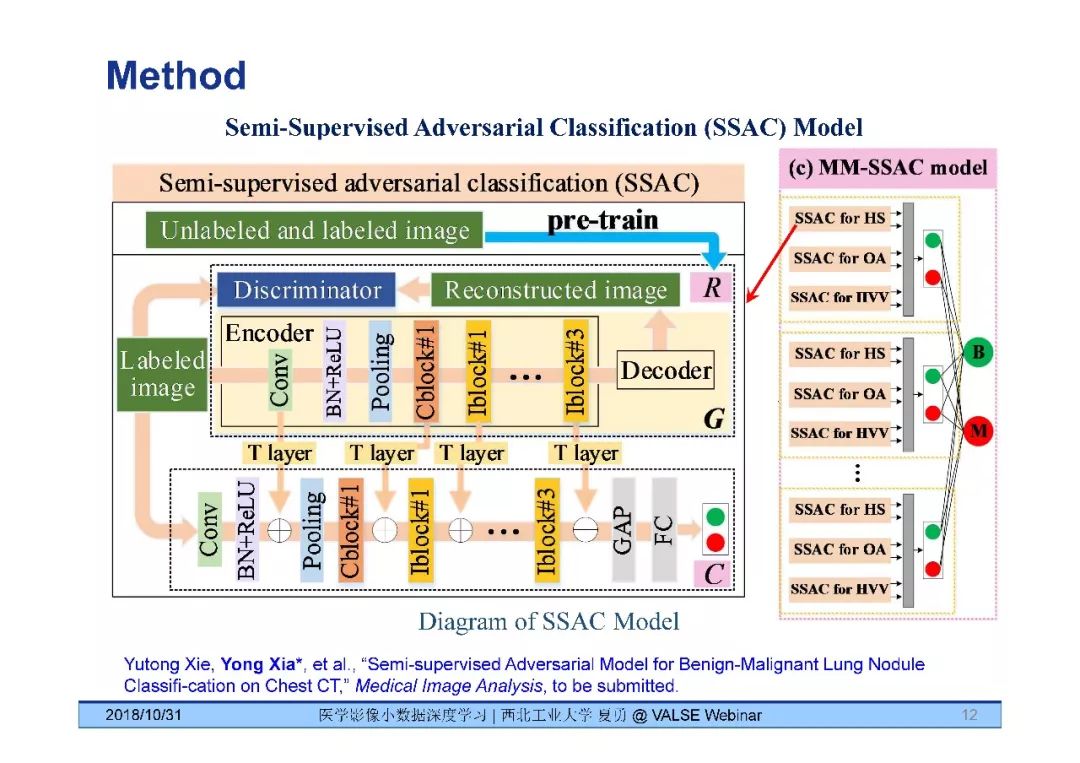
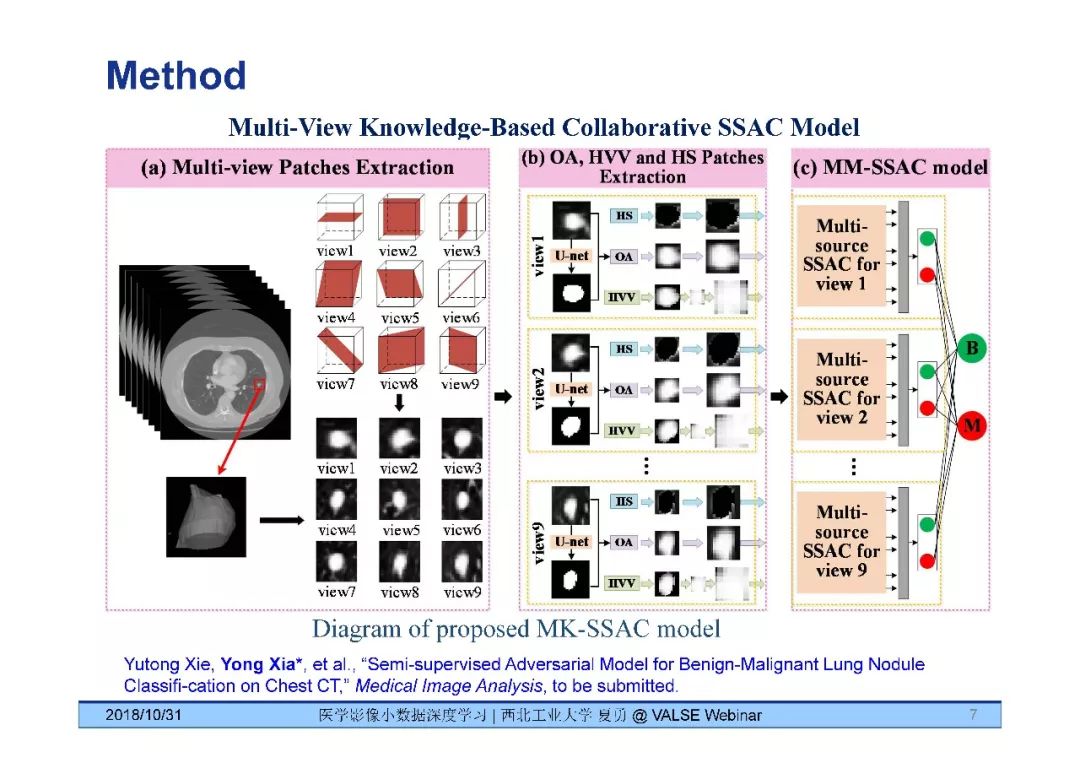
问题2:SSAC可不可以认为是一种多视角的数据扩充?
回答:SSAC模型本身的特点是同时使用有和没有良恶性类别标签的肺结节数据进行半监督学习,模型的输入是二维的图像块。我们在SSAC模型的基础上,还运用了多视角基于知识的协作学习(Multi-View Knowledge-Based Collaborative Learning, MV-KBC),进而想模型推广为MK-SSAC模型。这个模型使用了一种多视角的数据扩充,即在水平位、冠状位、矢状位和六个对角位分别提取图像块,在每一种视角的图像块上,像TMME模型一样,分别用三个SSAC模型从三个角度(纹理、形状和整体)提取图像信息。这样一来,我们总共使用了九个视角下的27个模型,共同进行分类决策。
问题3:以医学影像(核磁、CT等)为序列影像,是否可以直接使用3D-CNN的方式实现检测和分割?
回答:是的,而且像3D DenseNet和3D UNet这样的3D-CNN模型往往都能取得不错的效果。需要注意的是待处理影像的层厚,如果层厚很大(例如在水平截面上的空间解析度是1.0*1.0 mm2,而层厚是5mm),使用3D-CNN模型的效果也许就不好了。
问题4:是否研究过数据规模的影响?
回答:对于大部分医学影像分析问题而言,目前可以使用的数据量在训练深度学习模型的时候都偏小,这也解释了很多时候使用外部训练数据可以进一步提高模型的效果。我们曾经研究过进一步减少训练数据量对模型性能的影响。一如预测,当训练数据进一步减小的时候,深度模型会更早陷入过拟合,从而使其性能随训练数据的减少快速下降。相对而言,如果结合使用深度模型学习的特征和传统方法提取的特征,则性能的下降会变得比较温和。这显示,当因为训练数减少,深度模型过拟合的时候,传统方法提取的特征会起到一定的性能补偿作用(Jianpeng Zhang et al., IEEE-JBHI, 22(5), 2018)。
问题5:Attention Branch与Self Attention的对比?
回答:我们认为,很多分类网络本身就可以学习到attention map,利用这种Self Attention相比在模型中使用独立的Attention Branch可以降低模型的参数规模,而且我们在皮肤病诊断数据上的实验结果显示,利用这种Self Attention可以得到更准确的attention map,特别是在目标区域较小的时候。
问题6:半监督学习模型在医学影像的应用?
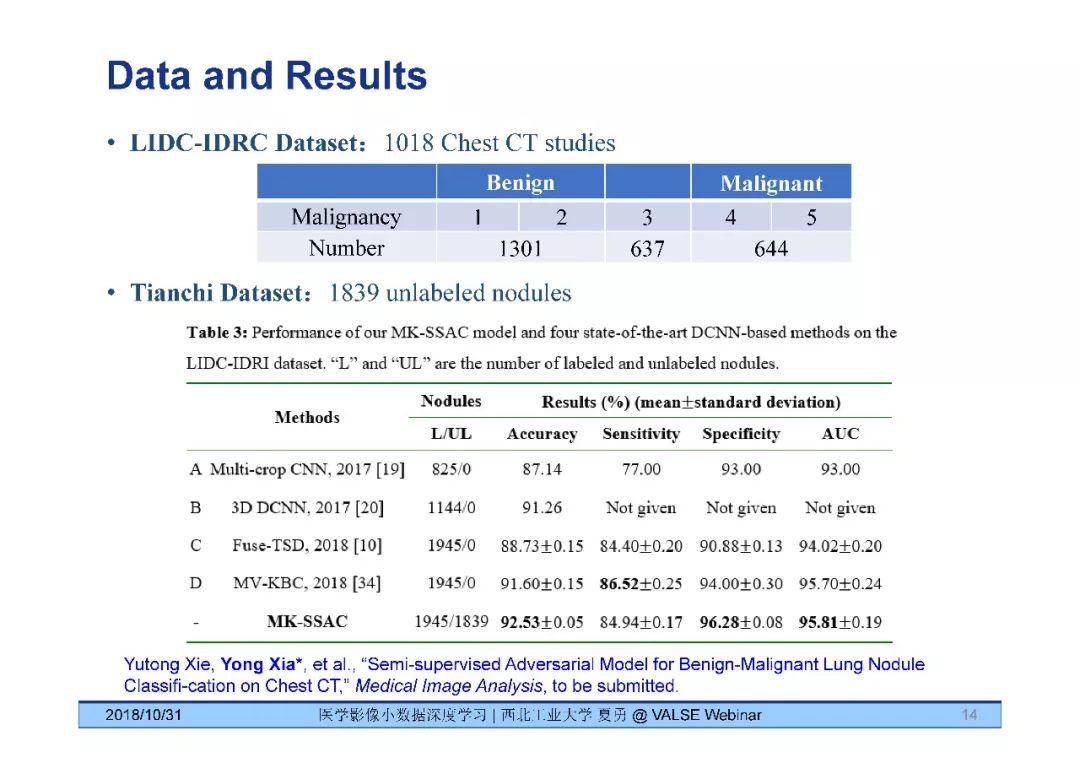
回答:我相信半监督学习在医学影像分析中的会有很好的应用。这是因为,医学影像数据量小的原因有二:数据获取困难和数据标注困难。很多时候,比起数据获取,恐怕数据标注是更困难的。如果可以使用没有标注的数据学习,则可能减少对数据标注的依赖,或者进一步提高图像分析的性能。例如,我们以阿里天池肺结节检测竞赛的数据做为未标注良恶性的数据,以LIDC-IDRC数据库做为有标记良恶性的数据,通过使用我们构造的MK-SSAC模型同时从这两个数据库上学习,取得了比仅从LIDC-IDRC数据库上学习更好的分类性能。
问题7:对于小数据集医学影像的特征提取问题?
回答:针对医学影像的特征提取问题,目前还没有通用的特征提取方法,需要根据具体的成像模态和影像分析问题来提取特征。一般而言,推荐结合使用深度模型学习到的特征和根据领域知识设计的特征。
问题8:注意力模型的实验部分展示的注意力热图的获得?
回答:注意力热图是用CAM (Class Activation Mapping)方法得到的。所展示的热力图是最后一个ARL模块产生的热力图。
录像视频在线观看地址:
http://www.iqiyi.com/u/2289191062
参考文献:
[1] Yongsheng Pan, Yong Xia, "Residual Network based Aggregation Model for Skin Lesion Classification," arXiv:1807.09150.
[2] Haozhe Jia, Yang Song, Donghao Zhang, Heng Huang, Dagan Feng, Michael Fulham, Yong Xia, Weidong Cai, "3D Global Convolutional Adversarial Network for Prostate MR Volume Segmentation," arXiv:1807.06742.
[3] Junjie Zhang, Yong Xia, Yanning Zhang, "A Pulmonary Nodule Detection Model Based on Progressive Resolution and Hierarchical Saliency," arXiv:1807.00598.
[4] Hongyu Wang, Yong Xia, "ChestNet: A Deep Neural Network for Classification of Thoracic Diseases on Chest Radiography," arXiv:1807.03058.
[5] Yutong Xie, Yong Xia*, Jinapeng Zhang, Yang Song, Dagan Feng, Michael Fulham, and Weidong Cai, "Knowledge-based Collaborative Deep Learning for Benign-Malignant Lung Nodule Classification on Chest CT," IEEE Transactions on Medical Imaging, in press.
[6] Jianpeng Zhang, Yong Xia*, Yutong Xie, Michael Fulham, and David Dagan Feng, "Classification of Medical Images in the Biomedical Literature by Jointly Using Deep and Handcrafted Visual Features," IEEE Journal of Biomedical and Health Informatics, vol. 22, no. 5, pp 1521–1530, Sep. 2018.
[7] Yongsheng Pan, Mingxia Liu, Chunfeng Lian, Tao Zhou, Yong Xia*, and Dinggang Shen, "Synthesizing Missing PET from MRI with Cycle-consistent Generative Adversarial Networks for Alzheimer's Disease Diagnosis," MICCAI 2018.
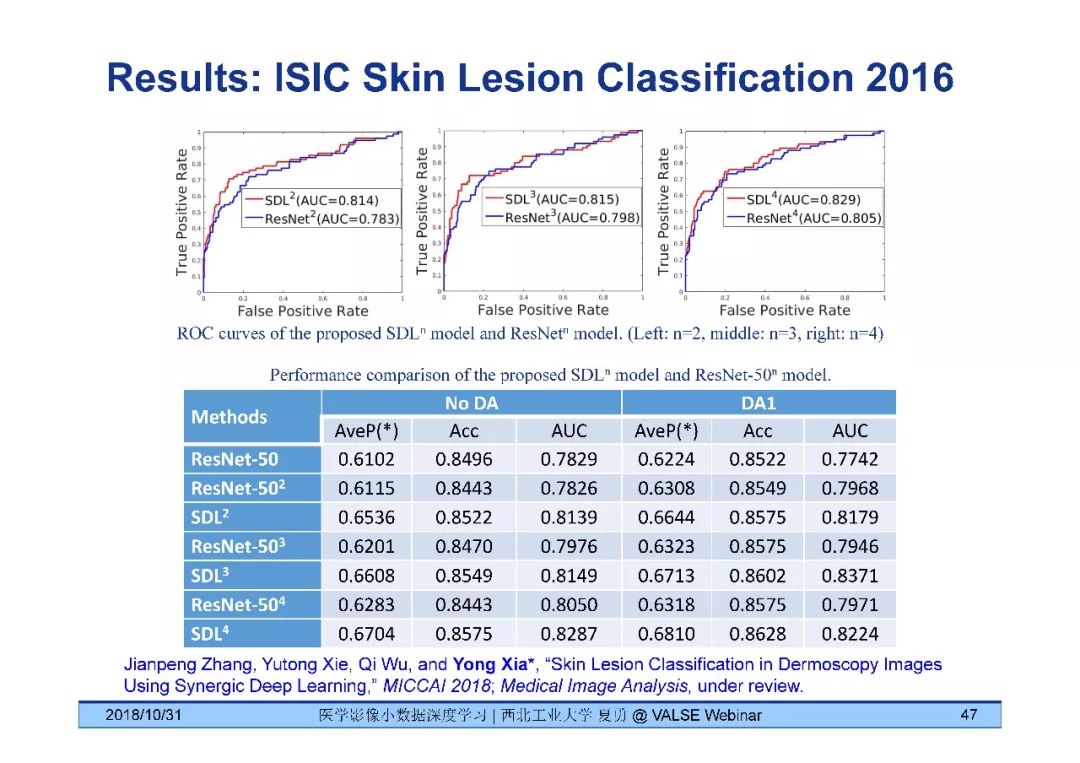
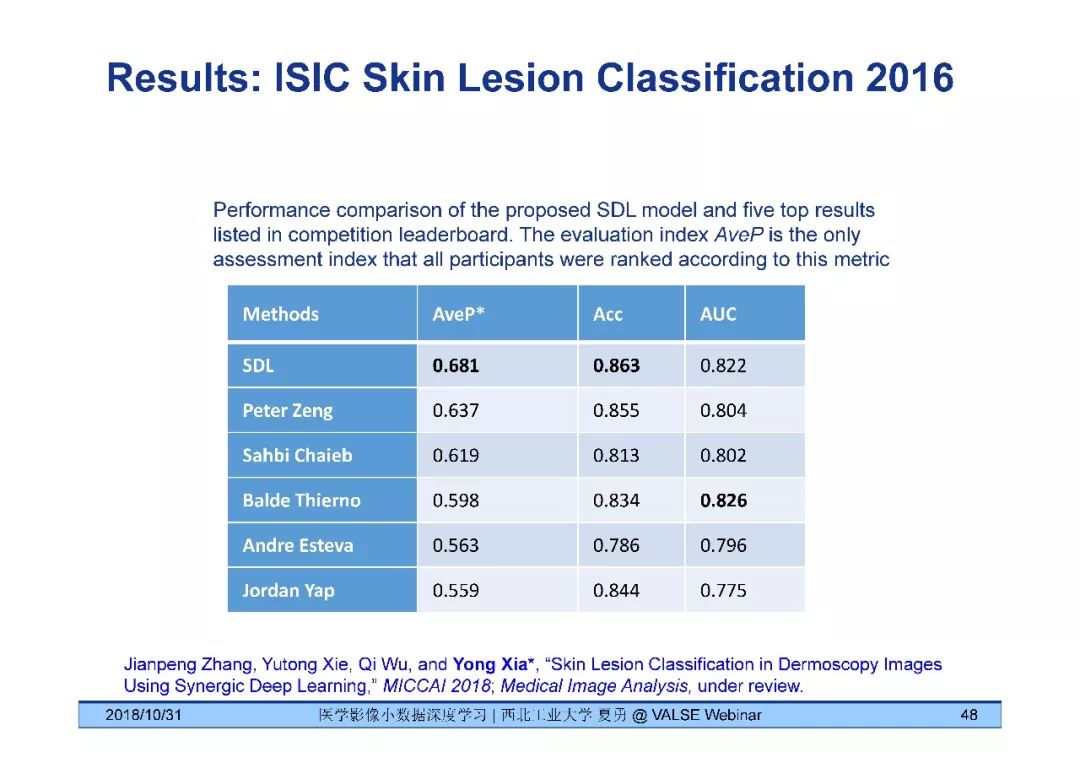
[8] Jianpeng Zhang, Yutong Xie, Qi Wu, and Yong Xia*, "Skin Lesion Classification in Dermoscopy Images Using Synergic Deep Learning," MICCAI 2018.
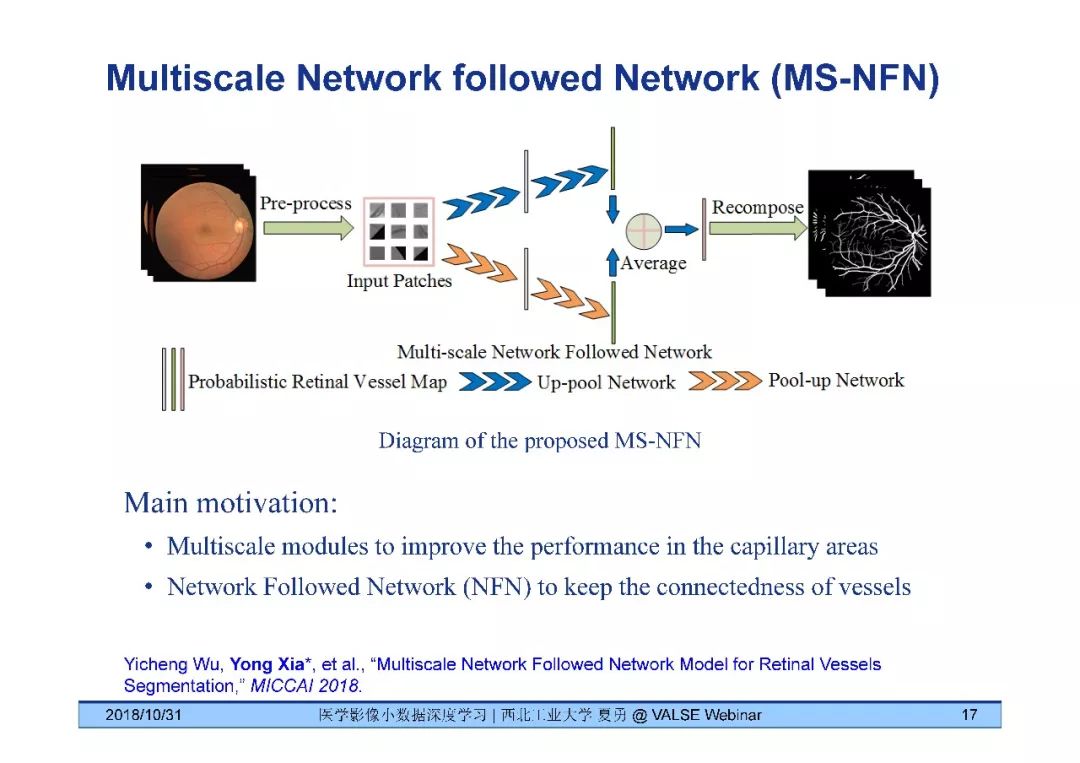
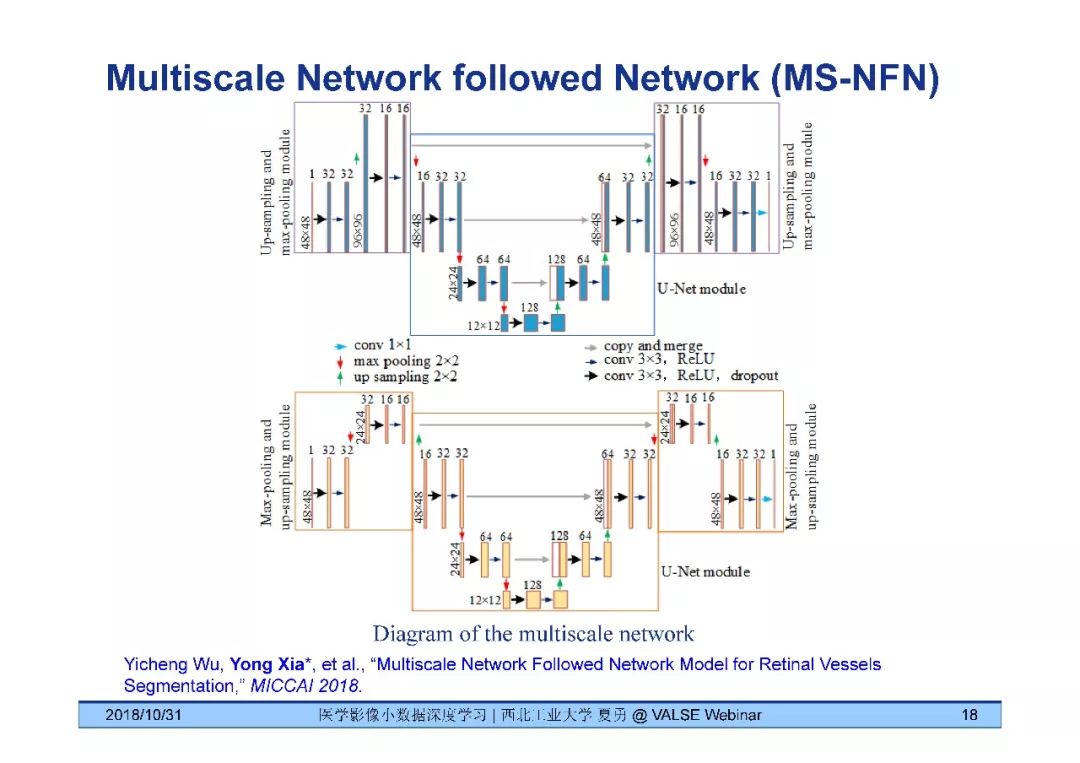
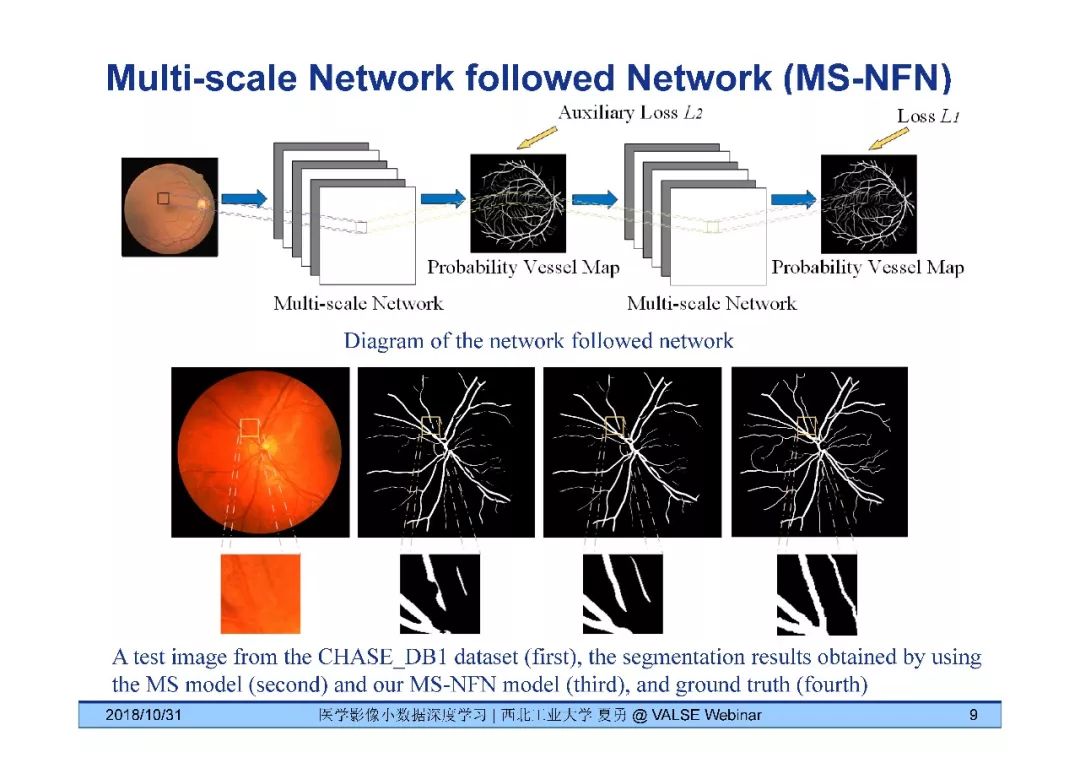
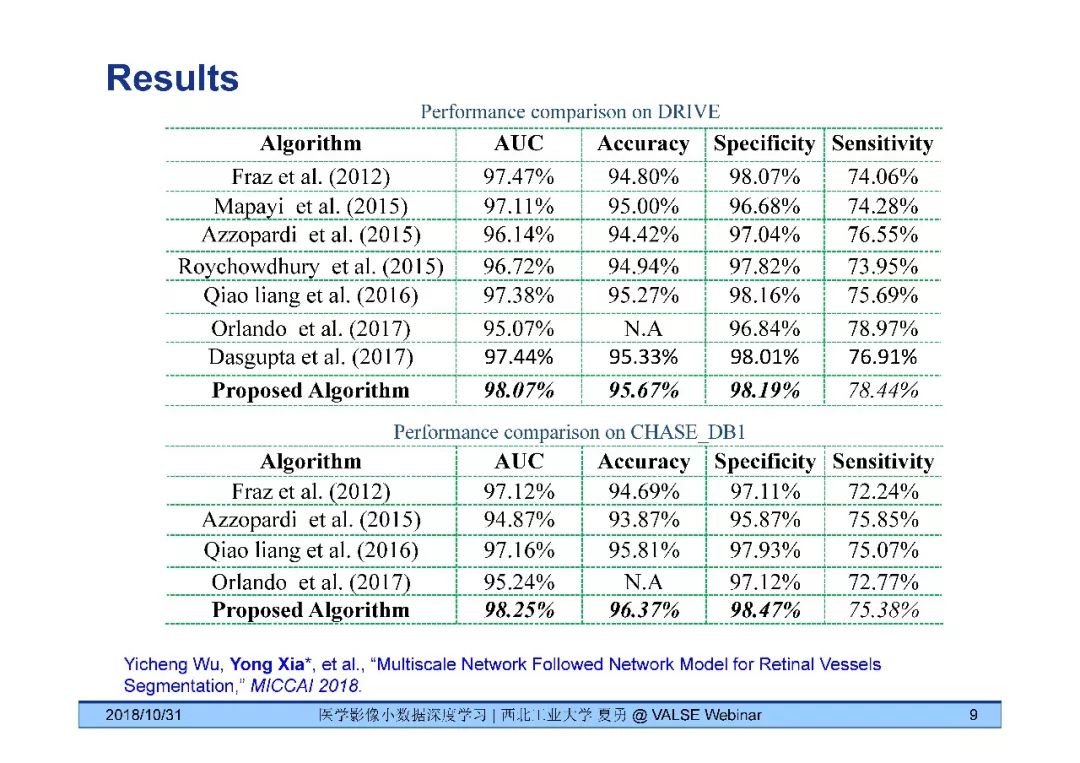
[9] Yicheng Wu, Yong Xia*, Yang Song, Yanning Zhang, and Weidong Cai "Multiscale Network Followed Network Model for Retinal Vessels Segmentation," MICCAI 2018.
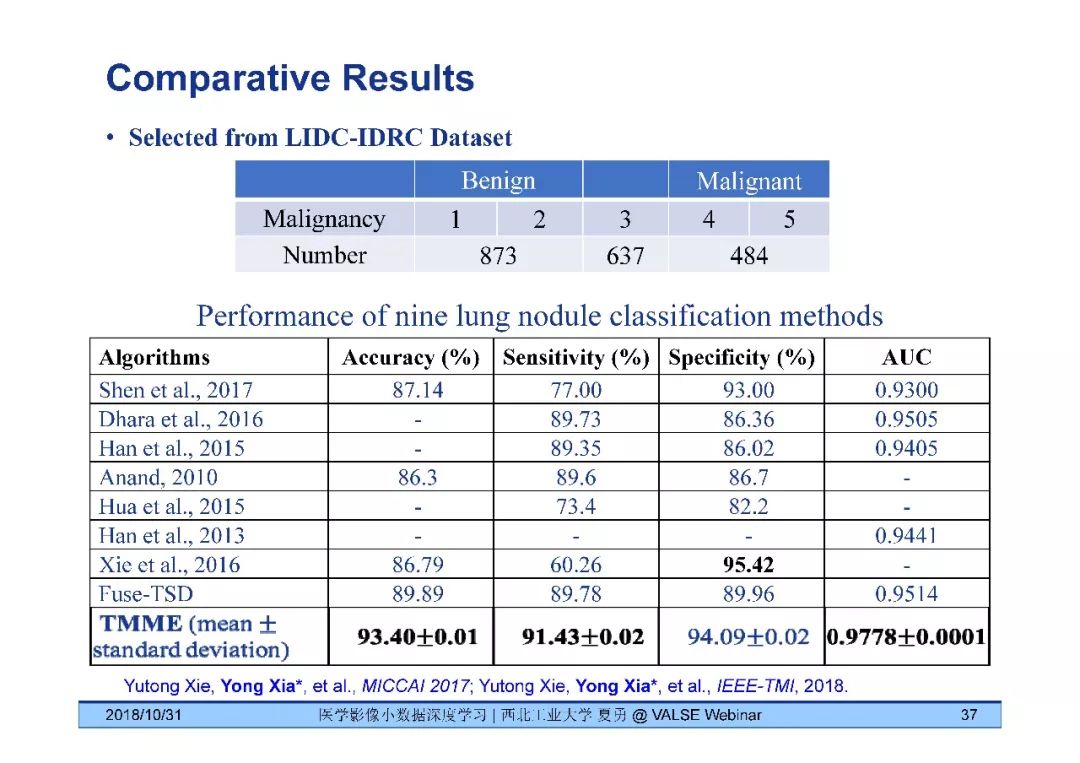
[10] Yutong Xie, Yong Xia*, Jianpeng Zhang, Weidong Cai, Michael Fulham and David Dagan Feng, "Transferable Multi-model Ensemble for Benign-Malignant Lung Nodule Classification on Chest CT," MICCAI 2017.
VALSE简介
VALSE(Vision and Learning Seminar) 视觉与学习青年学者研讨会 的主要目的是为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。
http://valser.org

-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



