腾讯 AI Lab 正式开源PocketFlow 让深度学习放入手机
来源:新浪科技
链接:
https://tech.sina.com.cn/d/2018-11-04/doc-ihnknmqw4932015.shtml
11月1日,腾讯AI Lab在南京举办的腾讯全球合作伙伴论坛上宣布正式开源“PocketFlow”项目, 该项目是一个自动化深度学习模型压缩与加速框架,整合多种模型压缩与加速算法并利用强化学习自动搜索合适压缩参数,解决传统深度学习模型由于模型体积太大,计算资源消耗高而难以在移动设备上部署的痛点,同时极大程度的降低了模型压缩的技术门槛,赋能移动端AI应用开发。
这是一款适用于各个专业能力层面开发者的模型压缩框架,基于Tensorflow开发,集成了当前主流与AI Lab自研的多个模型压缩与训练算法,并采用超参数优化组件实现了全程自动化托管式的模型压缩。开发者无需了解具体模型压缩算法细节,即可快速地将AI技术部署到移动端产品上,实现用户数据的本地高效处理。
目前该框架在腾讯内部已对多个移动端AI应用模型进行压缩和加速,并取得了令人满意的效果, 对应用整体的上线效果起到了非常重要的作用。
自2016年腾讯首次在GitHub上发布开源项目,目前已累积开源覆盖人工智能、移动开发、小程序等领域近60个项目。
随着移动互联网的普及和AI算法的愈加成熟,移动端AI的需求和应用场景也愈加丰富,如智能美颜,瘦身,手势识别,场景识别,游戏AI,视频检测,车载语音交互,智能家居,实时翻译等。将模型部署在移动端代替服务器端可以实现实时交互,在无网络环境的情况下也可正常运行,并且保护了数据的隐私和安全性,降低运维成本。而在移动端AI模型部署方面,小而快变成了模型推理最渴望的要求之一,因为小的模型可以使得整个应用的存储空间减小;而提高模型的推理速度则可以使得整个模型应用场景的反应速度加快,同时也可以在低配设备上取得很好的效果。因此,模型的推理速度逐渐已经成为了各大AI应用市场竞争力上最重要的评测指标之一。然而往往训练出来的模型推理速度或者尺寸大小不能满足需求,大部分开发者对极致的模型压缩和加速方法又感到困惑。
PocketFlow的出现就是为了解决这个令众多AI应用开发者头痛的问题。
框架开源内容:
PocketFlow框架本次开源内容主要由两部分组件构成,分别是模型压缩/加速算法部分和超参数优化部分,具体结构如下图所示:
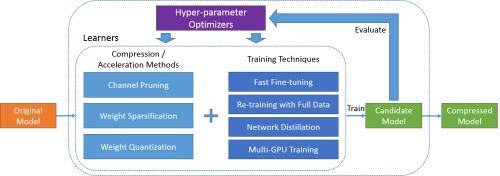
模型压缩/加速算法部分包括多种深度学习模型压缩和加速算法:
通道剪枝(channel pruning): 在CNN网络中,通过对特征图中的通道维度进行剪枝,可以同时降低模型大小和计算复杂度,并且压缩后的模型可以直接基于现有的深度学习框架进行部署。PocketFlow还支持通道剪枝的分组finetune/retrain功能,通过实验我们发现此方法可以使原本压缩后的模型精度有明显的提升。
权重稀疏化(weight sparsification):通过对网络权重引入稀疏性约束,可以大幅度降低网络权重中的非零元素个数;压缩后模型的网络权重可以以稀疏矩阵的形式进行存储和传输,从而实现模型压缩。
权重量化(weight quantization):通过对网络权重引入量化约束,可以降低用于表示每个网络权重所需的比特数;我们同时提供了对于均匀和非均匀两大类量化算法的支持,可以充分利用ARM和FPGA等设备的硬件优化,以提升移动端的计算效率,并为未来的神经网络芯片设计提供软件支持。
网络蒸馏(network distillation):对于上述各种模型压缩组件,通过将未压缩的原始模型的输出作为额外的监督信息,指导压缩后模型的训练,在压缩/加速倍数不变的前提下均可以获得0.5%-2.0%不等的精度提升。
多GPU训练(multi-GPU training):深度学习模型训练过程对计算资源要求较高,单个GPU难以在短时间内完成模型训练,因此我们提供了对于多机多卡分布式训练的全面支持,以加快使用者的开发流程。无论是基于ImageNet数据的Resnet-50图像分类模型还是基于WMT14数据的Transformer机器翻译模型,均可以在一个小时内训练完毕。
超参数优化(hyper-parameter optimization)部分可以通过强化学习或者AutoML,在整体压缩率一定的情况下,搜索出每一层最合适的压缩比例使得整体的精度最高。多数开发者对模型压缩算法往往了解较少,调节压缩算法参数需要长期的学习和实验才能有所经验, 但超参数取值对最终结果往往有着巨大的影。PocketFlow的超参数优化部分正是帮助开发者解决了这一大痛点,并且通过实验我们发现,其优化结果也要好于专业的模型压缩工程师手工调参的结果。其结构如下图:

PocketFlow性能
通过引入超参数优化组件,不仅避免了高门槛、繁琐的人工调参工作,同时也使得PocketFlow在各个压缩算法上全面超过了人工调参的效果。以图像分类任务为例,在CIFAR-10和ImageNet等数据集上,PocketFlow对ResNet和MobileNet等多种CNN网络结构进行有效的模型压缩与加速。
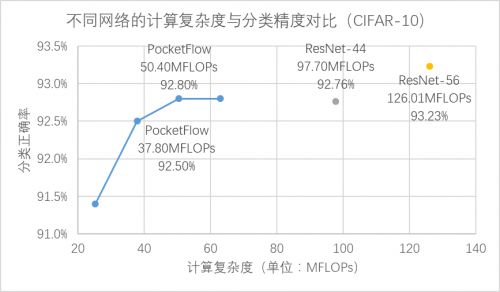
在CIFAR-10数据集上,PocketFlow以ResNet-56作为基准模型进行通道剪枝,并加入了超参数优化和网络蒸馏等训练策略,实现了2.5倍加速下分类精度损失0.4%,3.3倍加速下精度损失0.7%,且显著优于未压缩的ResNet-44模型; 在ImageNet数据集上,PocketFlow可以对原本已经十分精简的MobileNet模型继续进行权重稀疏化,以更小的模型尺寸取得相似的分类精度;与Inception-V1、ResNet-18等模型相比,模型大小仅为后者的约20~40%,但分类精度基本一致(甚至更高)。
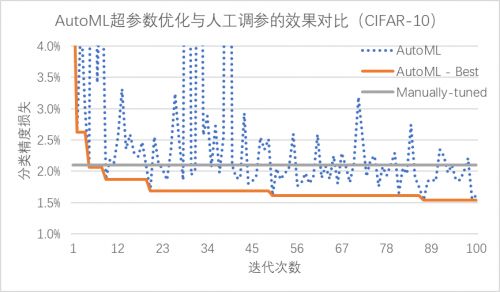
相比于费时费力的人工调参,PocketFlow框架中的AutoML自动超参数优化组件仅需10余次迭代就能达到与人工调参类似的性能,在经过100次迭代后搜索得到的超参数组合可以降低约0.6%的精度损失;通过使用超参数优化组件自动地确定网络中各层权重的量化比特数,PocketFlow在对用于ImageNet图像分类任务的MobileNet-v1模型进行压缩时,取得了一致性的性能提升;用PocketFlow平均量化比特数为8时,准确率不降反升,从量化前的70.89%提升到量化后的71.29%。
PocketFlow落地助力内部移动应用AI落地
在腾讯公司内部,PocketFlow框架正在为多项移动端业务提供模型压缩与加速的技术支持。例如,在手机拍照APP中,人脸关键点定位模型是一个常用的预处理模块,通过对脸部的百余个特征点(如眼角、鼻尖等)进行识别与定位,可以为后续的人脸识别、智能美颜等多个应用提供必要的特征数据。我们基于PocketFlow框架,对人脸关键点定位模型进行压缩,在保持定位精度不变的同时,大幅度地降低了计算开销,在本身已经十分精简的网络上取得了1.3 ~ 2倍不等的加速效果,压缩后的模型已经在实际产品中得到部署。

在人体体态识别项目中,PocketFlow更是在满足上线精度的要求下,使得模型推理速度有3倍以上的加速, 为项目的移动端落地起到了决定性的作用。

-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



