【NeurIPS2019报告推荐】公平与表示学习—UIUC Sanmi Koyejo教授
【导读】越来越明显的是,广泛采用的机器学习模型可能导致歧视性结果,并可能加剧训练数据之间的差异。随着越来越多的机器学习用于现实世界中的决策任务,必须解决机器学习中的偏见和公平问题。我们的动机是,在各种新兴方法中,表示学习为评估和潜在地减轻不公平现象提供了独特的工具集。本教程介绍了现有的研究,并提出了在表示学习和公平的交集中存在的开放性问题。我们将研究学习公平任务不可知表示的可能性(不可能性),公平性和泛化性能之间的联系,以及利用来自表示形式学习的工具来实现算法上的个人和群体公平性的机会。本教程旨在为广大的机器学习实践者提供帮助,并且必要的背景知识是预测性机器学习的工作知识。
作者介绍
Sanmi Koyejo,伊利诺伊大学香槟分校计算机科学系助理教授。
研究综述: 我们的研究兴趣是开发自适应鲁棒机器学习的原理和实践。最近的一些亮点包括:1)可伸缩的、分布式的和容错的机器学习;2)度量引出;通过人机交互选择更有效的机器学习指标。我们的应用研究主要集中在认知神经成像和生物医学成像方面。最近的一些重点包括①生物图像的生成模型,②时变脑电图的估计和分析。
http://sanmi.cs.illinois.edu/
部分截图






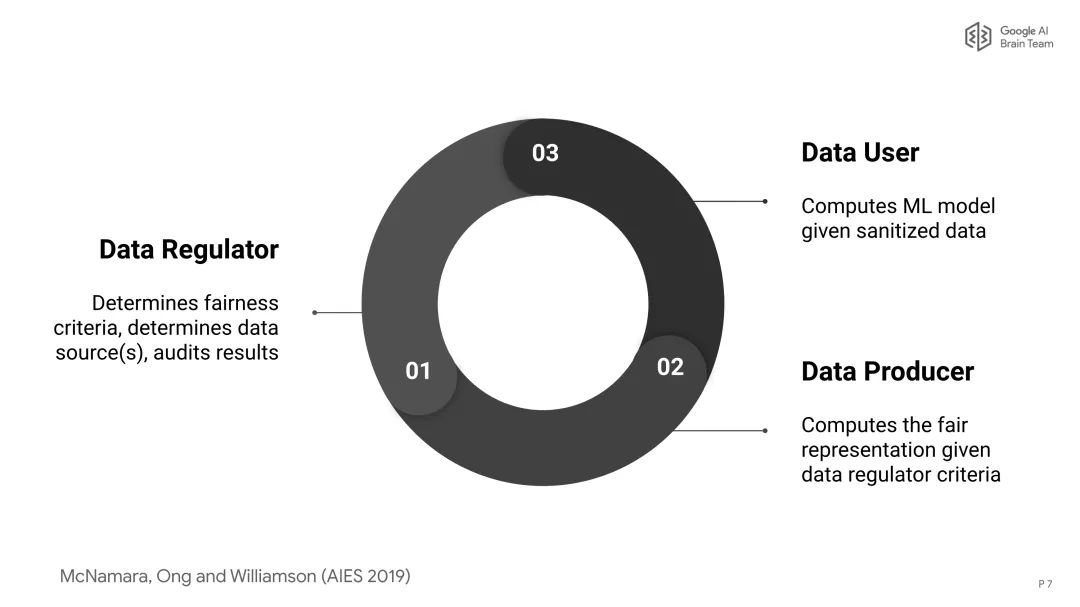
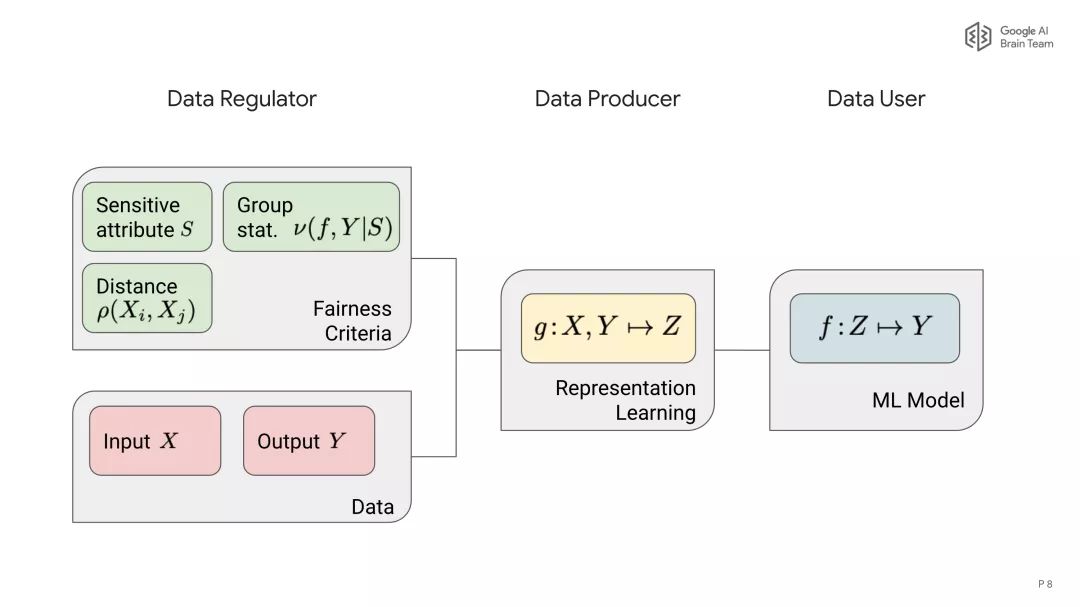




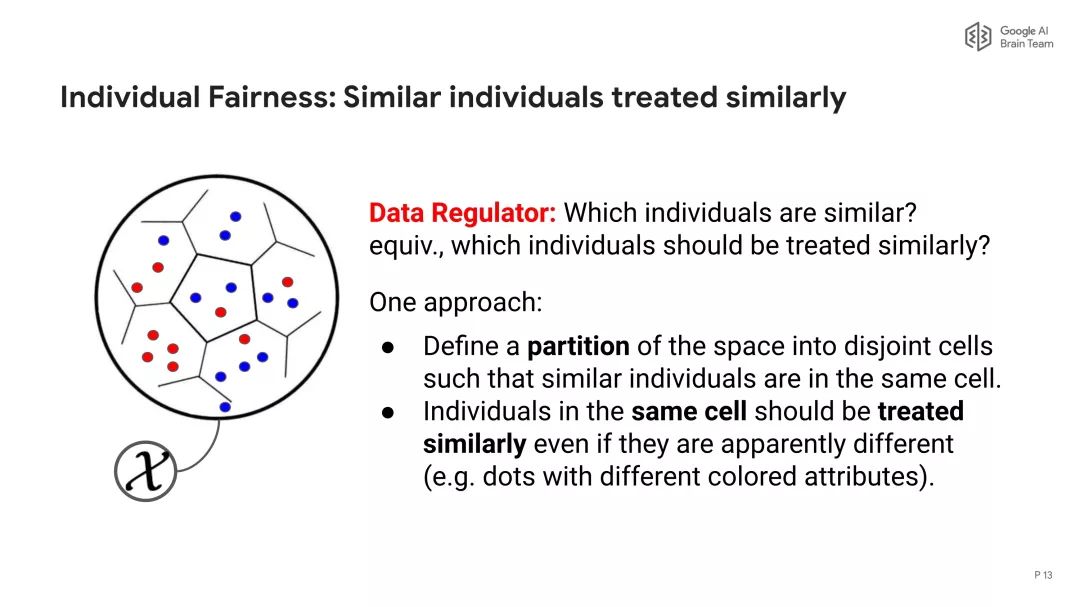
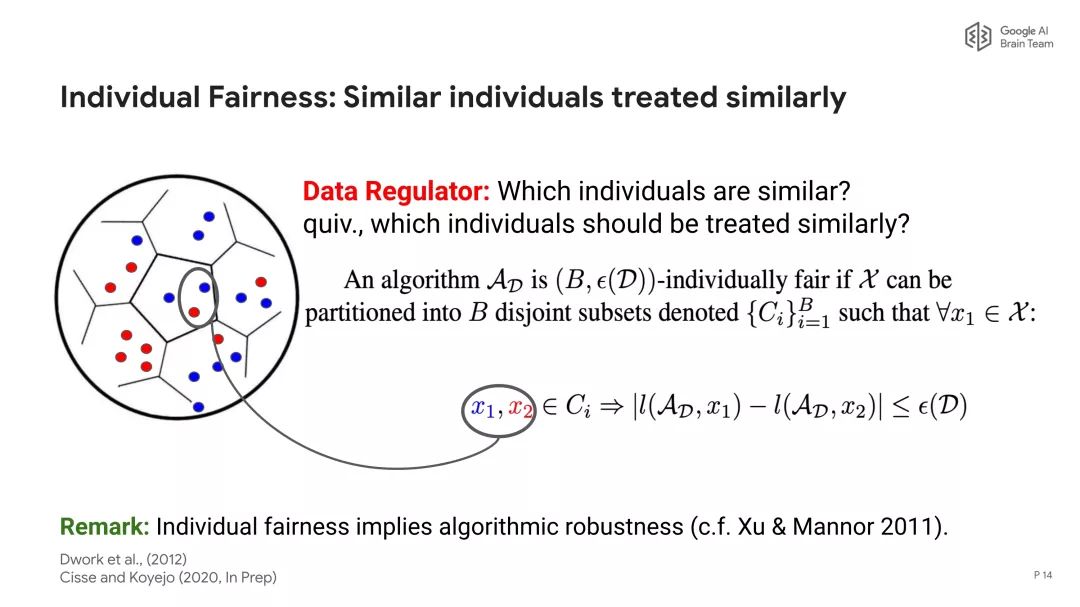

参考地址:
https://slideslive.com/38921491/representation-learning-and-fairness
请关注专知公众号(点击上方蓝色专知关注)
后台回复“NIPS2019FRL” 就可以获取《PPT》的下载链接~
专 · 知


展开全文



