数据库顶级国际会议VLDB2019最佳论文公布,区块链/HadoopDB榜上有名
【导读】VLDB 2019(Very Large Data Bases)是三大国际顶尖数据库会议之一(其余二者为SIGMOD和ICDE),根据大会官方公布,今年VLDB共接收了128篇Research Paper、22篇IndustryPaper和48个Demo。VLDB2019于2019.8.26-2019.8.30在洛杉矶召开。大会选出一系列最佳论文奖项,包括最佳论文奖由新加坡国立大学提出LineageChain系统的论文获得,2009年发表的“HadoopDB“获得十年最佳论文奖,Honorable mention荣誉提名奖由Rice University的研究团队获得。

VLDB 2019
本年度的 VLDB 会议已是第 45 届会议,于8月26日至30日在美国西海岸的著名城市洛杉矶举办。大会议程包括3个主题演讲(Keynote)、28个学术论文报告分会(Research Session)、4个工业界论文报告分会(Industry Session)、2个工业界邀请演讲(Invited Industry Talks)、2个系统展示论坛(Demo Session)、7个教程(Tutorial),以及博士生论坛(PhD Workshop)和多个子研讨会(Workshop)等。共历时5天,其中首尾两天是各个Workshop,正会3天。今年一共有 128 篇 Research Paper,22 篇 Industry Paper,以及 48 篇 Demo Paper 入选。与去年相比,收录的 Research Paper 和 Demo Paper 数量保持基本稳定,而 Industry Paper 有了显著的提升,从去年的12篇增加到今年的22篇。从投稿数量与录用率来看,Research Paper投稿677篇,录用率18.9%,Industry Paper为72/30.6%,Demo Paper为127/37.8%。与去年相比,Research Paper的投稿数量略有下降,录用率则基本持平。
关系型数据库(RDBMS)的研究仍然是主流,占总论文数量的约1/4;其次是关于图数据和图数据库系统的研究,相关论文涉及了大规模数据图上的子图匹配、社团发现、带约束的最短路径查询等经典算法问题,以及分布式环境下的图分割等问题。除了关系数据模型的统治地位不可撼动之外,近年来图数据模型也逐渐被应用于实际业务中。而无论是关系型数据、图数据或是其他数据类型,查询执行和查询优化始终是性能优化的核心问题。随着移动互联网、物联网近年来的快速发展,不断催生了依赖于时空信息且实时性强的应用,因而时空数据和流数据的相关论文在本届会议上也占据了一席之地。此外,机器学习与数据库逐渐联系紧密,也有一些论文尝试使用机器学习算法来优化查询算法。

最佳论文奖

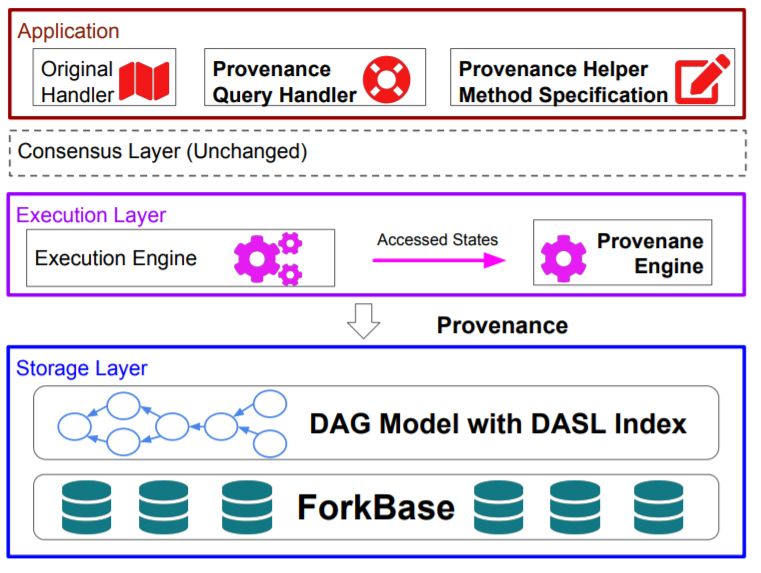
本届VLDB 2019的最佳论文奖为细粒度的、安全高效的基于区块链数据溯源系统“Fine-Grained, Secure and Efficient Data Provenance on Blockchain Systems”。
区块链实现了一个可以防篡改的账本,可以用来记录交易信息(transactions)进而改变一些存储的全局状态。整个系统记录所有的状态演化的历史信息。对于这些历史信息的管理,通常被称作数据的溯源(data provenance or lineage)。在传统的数据库领域,这一方向已经被广泛研究。但在区块链中对历史数据进行检索,目前的方法只能依赖于分析所有的交易信息。这样的方法适用于大规模的离线分析,而对于在线交易信息的处理是不合适的,比如账户A给B转账,要求近期账户B的每日余额位于某一阈值以上,才可转账,现有系统需要重放近期B账户每天的交易,才能作出转账的决策。。
这篇论文实现了LineageChain系统,支持细粒度的、安全高效的区块链数据溯源功能。LineageChain通过简单的API将溯源信息传给给智能合约,从而实现了一类新的区块链应用程序,其执行逻辑依赖于运行时的产生的溯源信息。在智能合约执行的过程当中,LinageChain会获取到溯源信息,然后高效地存储在Merkle Tree当中。LineageChain提供了基于跳表索引的结构来支持更加高效率的数据溯源的检索。整个系统基于Hyperledger来实现。存储系统基于ForkBase实现。论文对LineageChain的性能做出了分析,证实其的高效、安全、需要更少的存储代价等诸多优势。
最佳荣誉提名奖

今年的Honorable mention由Rice University的研究团队获得,论文“Declarative Recursive Computation on anRDBMS, or, Why You Should Use a Database For Distributed Machine Learning”提出一种在关系数据库之上搭建机器学习平台的方案。
Test of Time Award


参考文献:
https://vldb.org/2019/
https://cloud.tencent.com/developer/article/1496115
https://mp.weixin.qq.com/s/EpKJqWR5WqLmly7KpAiObg
-END-
专 · 知

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



