瑟瑟发抖……神经网络可能在欺骗你!
【导读】你对神经网络的信任度有多高?它总能学习到你想让他学习的东西吗?你真的敢坐在一辆自动驾驶的汽车上吗?我曾经也对神经网络充满了“崇拜”和信任,直到我亲眼看见它学出了我看不懂的东西……
作者 | Fabrizio Frigeni
编译 | 专知
翻译 | Mandy, Hujun, Xiaowen
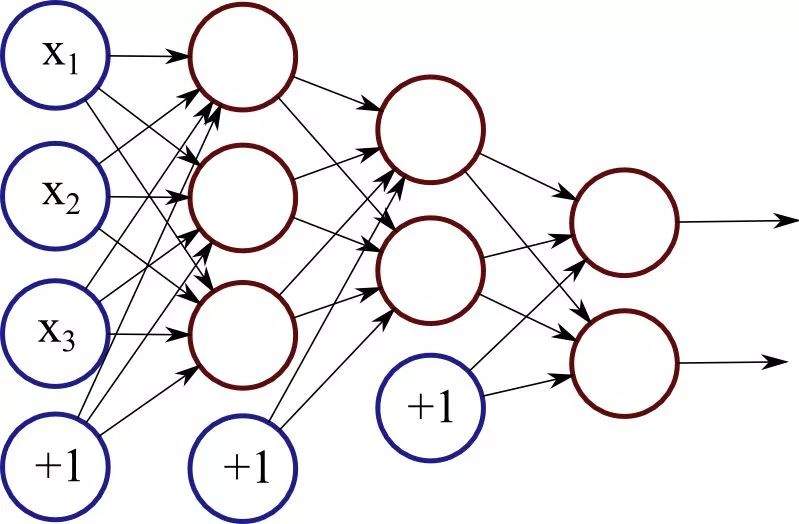
How to fool a neural network
我们真的应该让神经网络来驾驶汽车吗?
我以一个非常简单的问题开始了这项研究:神经网络能学会如何写数字吗?
想象一下,网络是一个对写作一无所知的学生。你提供一个白色的空白纸张作为输入,并期望网络生成某种输出。它很可能在开始时只是显示一些随机的涂鸦,然后你调整它的参数,这样输出就会越来越像你选择的数字。
解决这个问题的一个简单方法是通过监督学习。这和我们的孩子在学校里学习写字的方式是一样的:给他们看几个“3”的示例,他们很快就会完成一些相似于所提供例子的图画。神经网络也可以很容易地进行训练:通过扩充数据集,向他们展示一些“3”(可能比“一些”再多一点),他们很快就能复制你的例子。
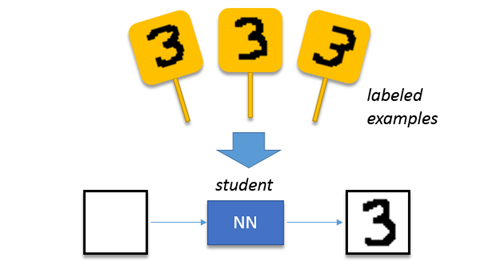
图:监督学习
然而,这样做没有乐趣,也没有智慧。这次我想尝试一种不同的方法。
让我们用第二个网络(老师),让它看看第一个网络(学生)生成的图画,并判断它们的质量。老师产生的反馈是一个数值奖励,基于这些图画与目标数字的相似程度。然后调整参数,以提高输出质量,从而得到老师更高的奖励。
更具体地说,这里老师是一个简单的、训练于MNIST数据集的卷积网络,其产生的奖励是是对应于所选数字[0...9]的类别的得分[0...1]。
该分数被强化学习算法用作奖励来更新学生的权重,即更新学生的策略。
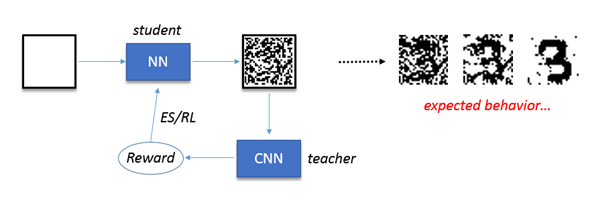
图:强化学习
注意,我使用了进化策略而不是合适的RL(强化学习)来更新权重。这是我之前写的一篇描述ES(进化策略)【1】的美观和简洁的文章。
你可能会问,如果监督学习实现起来更简单,收敛得更快,为什么要使用强化学习?
有两个原因:(1)尝试新事物总是很有趣,(2)因为监督学习本质上迫使学生模仿老师,而强化学习则激发学生的创造力,提出新的想法来解决问题。目标是从老师那里得到一个好的奖励,但老师并没有说如何获得它。其实,老师甚至都不知道如何解决这个问题!
强化学习方法提出新的原创策略的可能性一直让我着迷; 再一次,它的结果被证明是不可思议的。继续读下去,看看发生了什么...
源代码
评论者(老师)网络是一个预先训练好的CNN。我们使用Keras来加载它的模型并将其用于预测:
import numpy as np
from keras.models import Sequential, load_model
critic = load_model('CNN.h5')
演员(学生)网络是一个非常简单的全连接架构,只有一个隐藏层。毕竟,我们只需要在一张白纸上画点点;我们不需要一个深层的网络。
#actor's network
IL = 784 #input layer nodes
HL = 100 #hidden layer nodes
OL = 784 #output layer nodes
b1 = np.random.randn(HL)
w2 = np.random.randn(OL,HL) / np.sqrt(HL)
NumParams1 = len(b1.flatten())
NumParams2 = len(w2.flatten())
输入是一个28x28像素的白色图像,输出是一个大小相同的图像,带有黑色或白色的二值化像素。
#white image
img = np.zeros((28,28)).reshape(784)
#forward propagation
def predict(s,b1,w2):
h = b1 #should be np.dot(w1,s)+b1 but the input state is always zero (white image)
h[h<0]=0 #relu
out = np.dot(w2,h) #hidden layer to output
out[out<0]=0 #white pixels
out[out>0]=1 #black pixels
return out
然后我们启动ES算法。我们使用50个并行策略,并根据从评论者那里收集到的奖励来提高演员的权重。每个类的CNN的输出值是一个sigmoid,所以不需要归一化。
# ES parameters
NumEpisodes = 100
NumPolicies = 50
sigma = 0.1
learning_rate = 0.1
# digit we are trying to learn to write
DIGIT = 3
Reward = np.zeros(NumPolicies)
EpisodeReward = np.zeros(NumEpisodes)
# start learning
for episode in range(NumEpisodes):
# generate random variations around original policy
eps = np.random.randn(NumPolicies, NumParams1 + NumParams2) # normal distribution
# evaluate each policy over one episode
for policy in range(NumPolicies):
b1_try = b1 + sigma * eps[policy, :NumParams1].reshape(b1.shape)
w2_try = w2 + sigma * eps[policy, NumParams1:].reshape(w2.shape)
Reward[policy] = 0
# write on white paper
out = predict(img, b1_try, w2_try)
# collect reward from CNN looking at writing
out = out.reshape(1, 28, 28, 1)
out = out.astype('float32')
# output score from CNN for selected class
Reward[policy] += critic.predict(out, verbose=0)[0, DIGIT]
# calculate incremental rewards
EpisodeReward[episode] = np.mean(Reward)
F = (Reward - EpisodeReward[episode])
# update weights of original policy according to rewards of all variations
weights_update = learning_rate / (NumPolicies * sigma) * np.dot(eps.T, F)
b1 += weights_update[:NumParams1].reshape(b1.shape)
w2 += weights_update[NumParams1:].reshape(w2.shape)
if episode % 10 == 0:
print('Episode {0}, reward = {1}'.format(episode, EpisodeReward[episode]))
我们可以使用这段代码来显示输出图像:
import matplotlib.pyplot as plt
out = predict(img,b1,w2)
out = out.reshape((28,28))
plt.imshow(out, cmap='Greys', clim=(0,1))
plt.show()
结果
在我们开始实际训练之前,让我们先看看演员通过随机初始化的参数以及输入的白色图像所生成的内容:
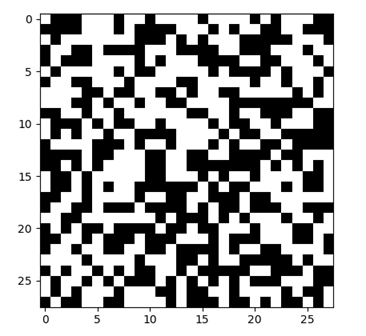
图:初始随机输出
这是一个完全随机的图像。到现在为止都没有什么问题。
现在,让我们开始训练并观察评论者的奖励如何随着时间而改变......
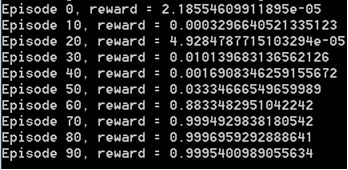
图:奖励随着时间的推移而上升,这是一个好兆头!
它开始的时候很低,因为随机输出看起来真的不像“3”,然后慢慢地增加,直到接近完美的1!
[注意,如果您试图复制这些结果,您需要一些耐心和一些超参数测试,因为ES不会每次都很快收敛。]
增加奖励意味着老师发现学生画的图像越来越好,越来越像我们选择的目标数字(这里是3)。值为1的奖励意味着学生已经学会了如何写完美的“3”!这是非常令人兴奋!
让我们看看这个“3”看起来如何。
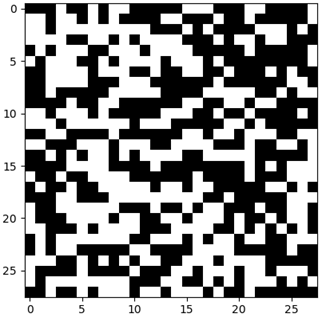
当我看到这个时,我非常失望......
你可以努力尝试,但老实说,这看起来不像一个完美的“3”,它实际上一点也不像“3”。
除了彻底的失望之外,我的第一反应是检查代码中的错误。然后一个疑问产生了:如果评论者网络真的认为那是一个“3”呢?
好吧,你猜怎么着?真的是这样。事实证明,将上面的图片加入到我简单的CNN中,为类“3”返回了一个完美的分数。网络对此非常确定。
我用不同的数字试了几次。奖励值通常是接近1:
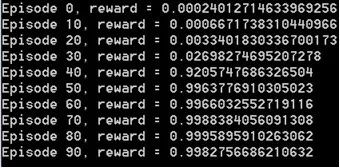
但在我看来,输出的图像从来都不像数字:
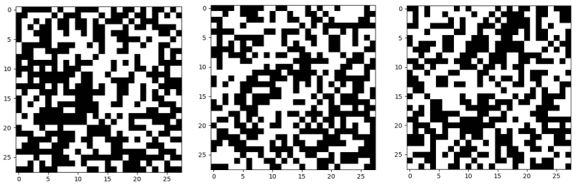
它们看起来更像是眼科医生的色盲测试。我知道我是色盲,但有时我还是觉得医生在欺骗我。一定还有一些我用眼睛无法察觉的超维度。
那么,这意味着什么? 有两件事情:
1.我的CNN毫无用处,因为它看到了不存在的东西。
2.我们有一个很好的方法来生成对抗的例子来欺骗神经网络。
第一点是悲伤的。你可以表示反对,因为可以增加网络的容量,改善训练来克服问题。我表示怀疑。这个问题显然是可以扩展的。这本质上是网络的一种视觉错觉。
第二点很可怕。如今,许多应用程序都依赖于神经网络,你希望它们足够健壮,能够处理输入信号的微小变化。但是,如果我的CNN看到上面的例子,并且非常确信能看到其中的数字,那么我就必须质疑整个背景概念。想象一下,自动驾驶汽车或人脸识别等应用程序也很容易被骗……
总结
我最初的问题是“神经网络能学会如何写数字吗?”
我不能直接回答这个问题。这个学生写了很多垃圾例子,但被老师认为是很好的。它被困在了局部最小值(尽管是极好的最小值),而且显然它们数量庞大,而且很容易到达。
我想,如果有足够的训练时间,有可能产生逼真的数字。然而,潜在的条件是我们有一个好的老师,他能够区分真实数字和其他人工制品。这种老师真的存在吗?老实说,从现在开始,我不会像以前那样信任神经网络了。
当然,本例中使用的CNN非常浅显,但是这个概念是可扩展和泛化的。记住,这些结果是众所周知的,不应该让任何人感到惊讶;但我仍然觉得很有趣(也许有点吓人),欺骗这些网络是多么容易。无论是谁来制造自动驾驶汽车,都不容易保证系统的鲁棒性,以对抗攻击。
1.https://medium.com/swlh/evolution-strategies-844e2694e632
原文链接:
https://medium.com/@ffrige/how-to-fool-a-neural-network-8ce248dc439c
更多专业AI教程资料请加入专知人工智能知识星球群获取,扫描下面二维码即可!
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



