【专知中秋呈献-PyTorch手把手深度学习教程03】LSTM快速理解与PyTorch实现: 图文+代码
点击上方“专知”关注获取更多AI知识!
首先祝各位专知好友,中秋佳节快乐!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。值国庆佳节,专知特别推出独家特刊-来自中科院自动化所专知小组博士生huaiwen和Jin创作的-PyTorch教程学习系列, 今日带来第三篇-< 快速理解系列(二): 图文+代码, 让你快速理解LSTM>
< 快速理解系列(二): 图文+代码, 让你快速理解LSTM>
< 快速理解系列(三): 图文+代码, 让你快速理解GAN >
< 快速理解系列(四): 图文+代码, 让你快速理解Dropout >
< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(二) 基于字符级RNN的姓名分类 >
< NLP系列(三) 基于字符级RNN的姓名生成 >
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
LSTM 已经在科技领域有了多种应用。基于 LSTM 的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。
网上有很多关于LSTM的介绍,为了大家更好的理解,特此分享翻译的一篇很好的外文。首先声明,由于本人水平有限,如有错误欢迎指出。
1、Recurrent Neural Networks
人类并不是每时每刻都从一片空白的大脑开始他们的思考。在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义。我们不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。我们的思想拥有持久性。
传统的神经网络并不能做到这点,看起来也像是一种巨大的弊端。例如,假设你希望对电影中的每个时间点的时间类型进行分类。传统的神经网络应该很难来处理这个问题——使用电影中先前的事件推断后续的事件
RNN 解决了这个问题。RNN 是包含循环的网络,允许信息的持久化

在上面的示例中,神经网络模块A正在读取一个输入X,并输出一个h,循环可以使得信息可以从网络的当前状态传递到下一个状态。
这些循环使得 RNN 看起来非常神秘。然而,如果你仔细想想,这样也不比一个正常的神经网络难于理解。RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开:
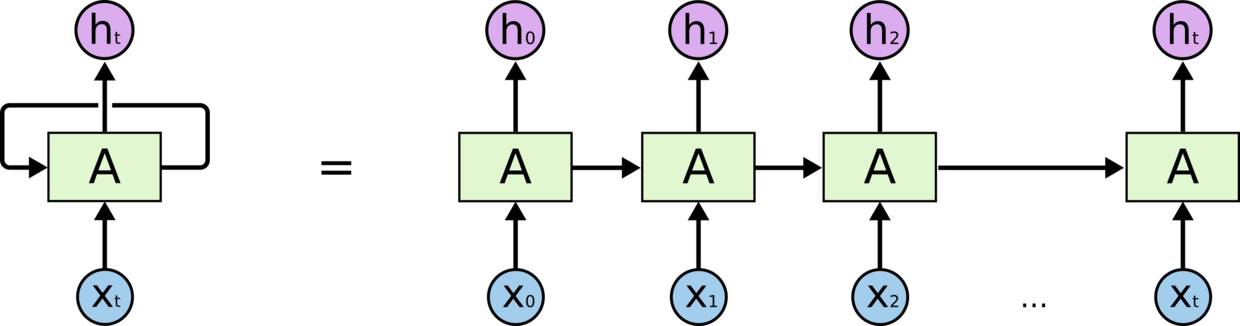
链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
并且 RNN 也已经被人们应用了!在过去几年中,应用 RNN 在语音识别,语言建模,翻译,图片描述等问题上已经取得一定成功,并且这个列表还在增长。关于RNNs在这些方面取得的惊人成功,大家可以看 Andrej Karpathy 的博客:The Unreasonable Effectiveness of Recurrent Neural Networks
而这些成功应用的关键之处就是 LSTM 的使用,这是一种特别的 RNN,比标准的 RNN 在很多的任务上都表现得更好。几乎所有的令人振奋的关于 RNN 的结果都是通过 LSTM 达到的。这篇博文也会就 LSTM 进行展开。
2、长期依赖(Long-Term Dependencies)问题
RNN的出现主要是它们能够把之前的信息联系到现在的任务中去,例如使用过去的视频段来推测对当前段的理解。如果RNN可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时,我们只需要查看最近的信息来执行当前的任务。例如,考虑一种语言模型,尝试基于以前的单词来预测下一个单词。如果我们试图预测“the clouds are in the sky”的最后一个词,我们就不需要任何进一步的语境,下一个字将是key很明显。在这种情况下,相关信息与预测词的位置间隔很小,则RNN可以学习使用过去的信息。
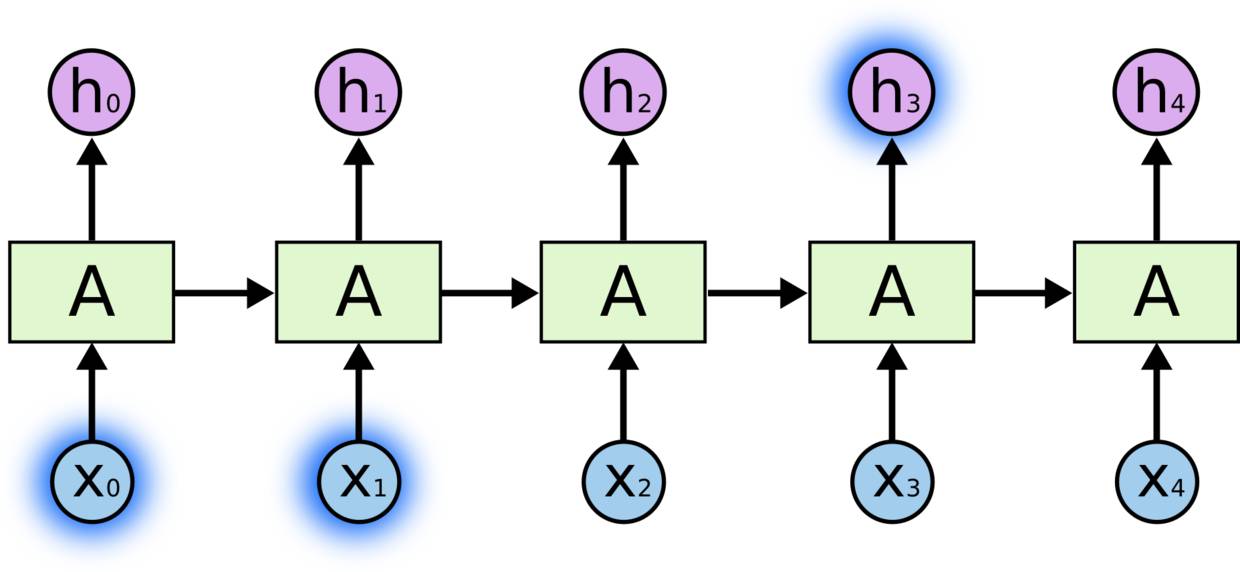
但也有需要更多上下文的情况。考虑尝试预测文本中的最后一个单词“I grew up in France… I speak fluent French”。最近的信息表明,下一个单词可能是一种语言的名称,但是如果我们想缩小哪种语言,我们需要法国的背景,从进一步回来。相关信息之间的差距和需要变得非常大的点是完全有可能的。
不幸的是,随着差距的扩大,RNN无法学会连接信息。
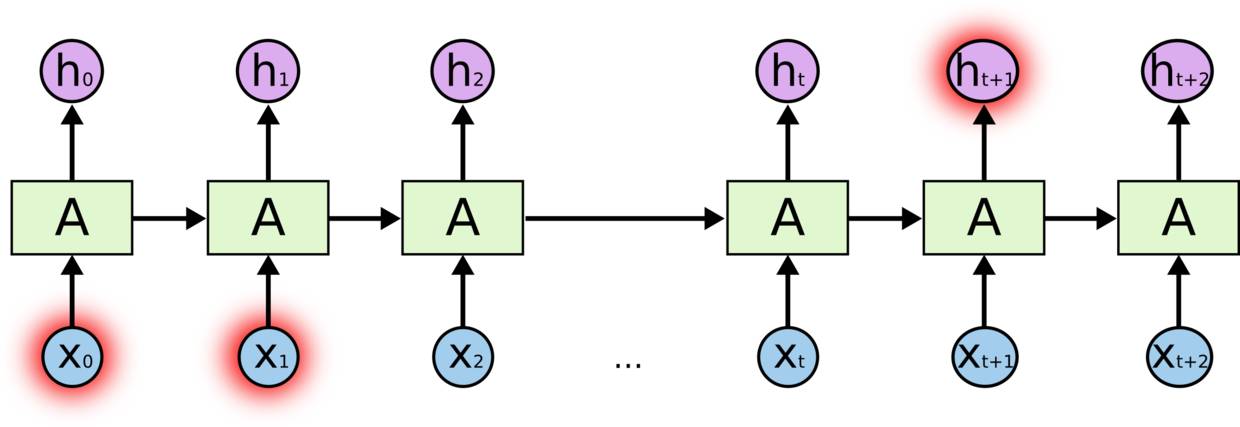
理论上,RNN绝对有能力处理这样的“长期依赖”。人们可以仔细挑选参数来解决这种形式的问题。可悲的是,在实践中,RNN似乎无法学习。 Hochreiter(1991)[German]和Bengio, et al. (1994),等人深入探讨了这个问题,他们发现了一些导致学习困难的根本原因。幸运的是,LSTM并没有这个问题。
3、LSTM
Long Short Term 网络(通常称为“LSTM”)是一种特殊的RNN,能够学习长期的依赖关系。他们由Hochreiter&Schmidhuber(1997)介绍,并被许多人完善和推广。他们在各种各样的问题上工作得非常好,现在被广泛使用。
LSTM被明确设计为避免长期依赖问题。记住长时间的信息实际上是他们的默认行为,而不是他们难以学习的东西!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh层。
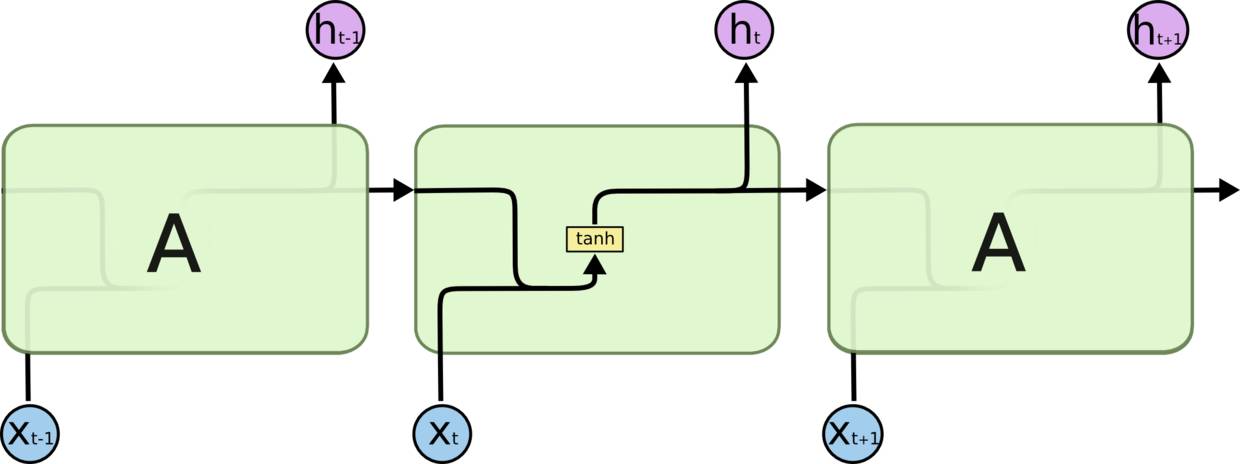
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
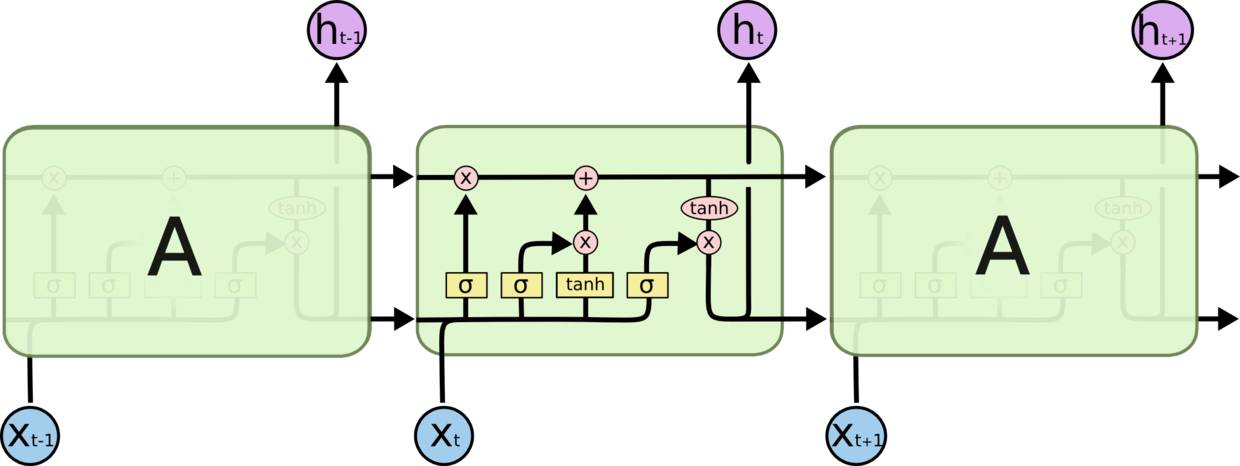
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。

image
在上图中,每一条黑线都携带从一个节点的输出到其他节点的输入的整个向量。粉色圆圈表示pointwise运算,如向量加法,而黄色框是学习到的神经网络层。行合并表示连接,线合并表示向量的连接,分开的线表示内容被复制。
4、LSTM 的核心思想
LSTM的关键是细胞状态,水平线穿过图的顶部。
cell状态类似于输送带。它直接在整个链上运行,只有一些少量的线性相互作用。信息在上面流传保持不变会很容易。
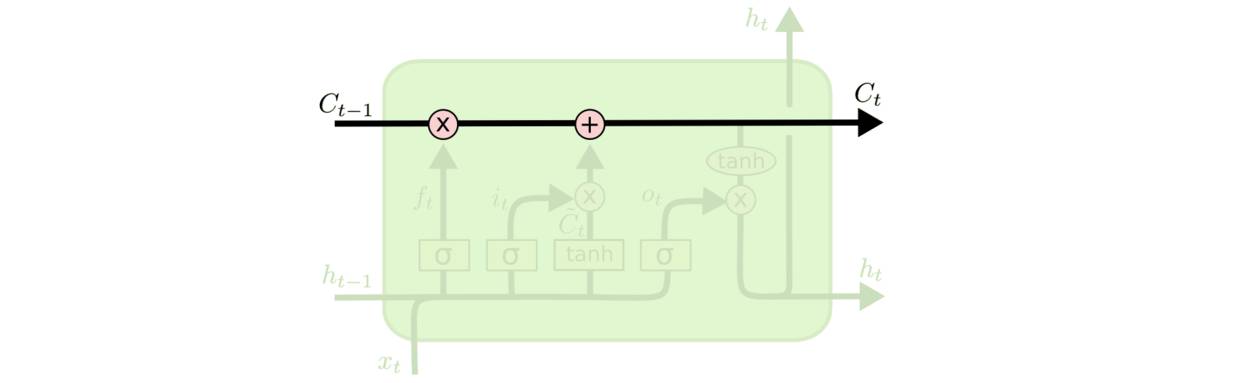
image
LSTM具有删除或添加信息到cell状态的能力,这被称为“门”的结构去调节。
门是一种让信息选择式通过的方法。他们包含一个sigmoid神经网络层和一个 pointwise 乘法操作。
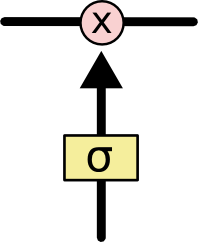
sigmoid层输出(是一个向量)的每个元素都是一个在 0 和 1 之间的实数,表示让对应信息通过的权重(或者占比)。比如, 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”。
LSTM 拥有三个门,来保护和控制细胞状态。
5、逐步理解 LSTM
1、遗忘门(forget gate)
在我们 LSTM 中的第一步是决定我们会从cell状态中丢弃什么信息。这个决定通过一个称为forget gate layer完成。该门会读取 h_{t-1} 和 x_t,输出一个在 0 到 1 之间的数值(向量长度和 cell 的状态Ct−1 一样)。表示让Ct−1 的各部分信息通过的比重。 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
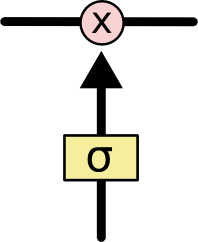
2、输入门(input gate)
下一步是决定我们要让多少新的信息加入到cell状态中取。这里包含两部分。首先,一个称为 “输入门层”的sigmoid层决定什么值我们将要更新。接下来,一个 tanh 层生成一个向量,也就是备选的用来更新的内容Ct。在下一步中,我们将结合这两个来对cell进行状态的更新。
在我们的语言模型的例子中,我们想把新的主语性别添加到cell状态中,以替换旧的信息。
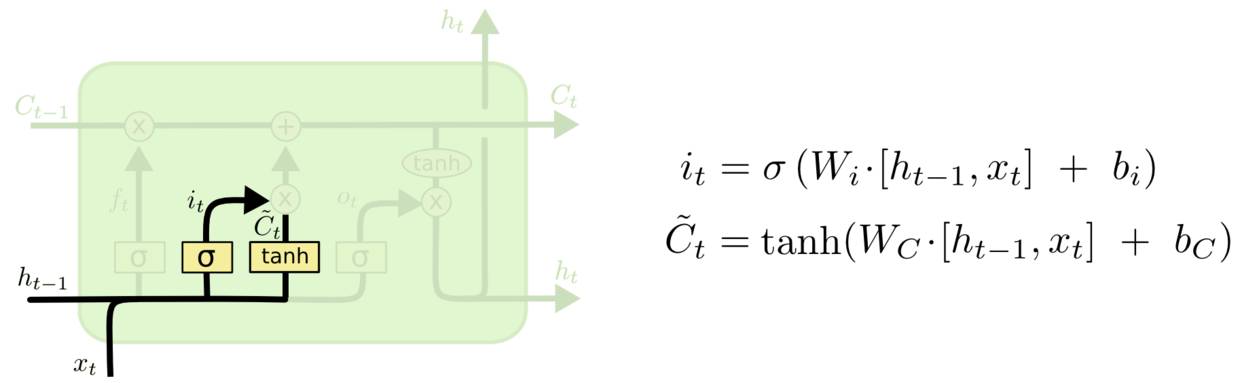
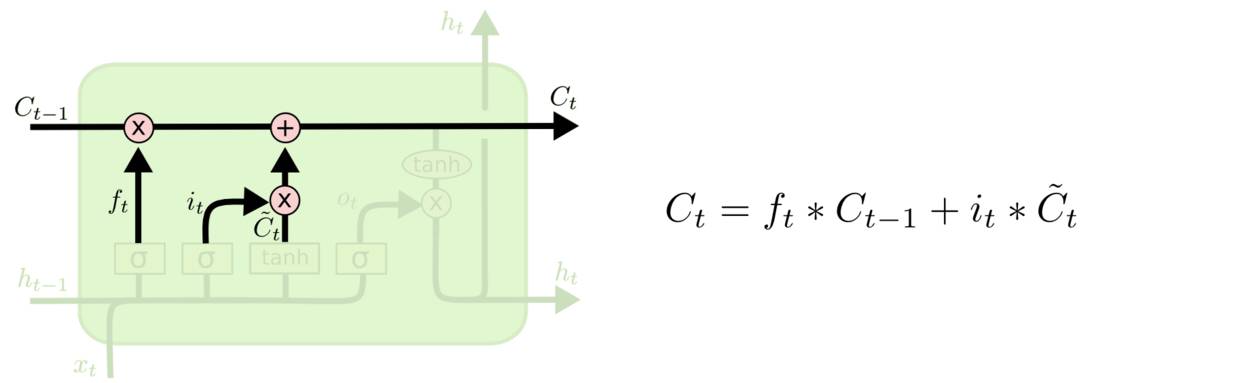
然后我们就可以更新 cell 状态了, 即把Ct−1更新为Ct。 首先我们把旧的状态 Ct−1和ft相乘, 把一些不想保留的信息忘掉。然后加上it∗Ct。这部分信息就是我们要添加的新内容。
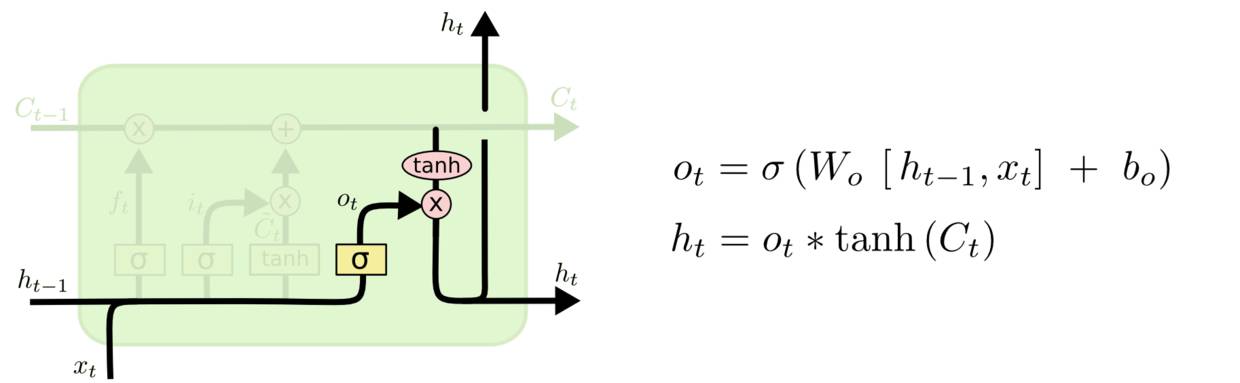
3、输出门(output gate)
最后,我们需要决定我们要输出什么。此输出将基于我们的cell状态,但需要经过一个过滤的处理。首先,我们运行一个sigmoid层,它决定了我们要输出的cell状态的哪些部分。然后,我们将cell状态通过tanh层(将值归到-1和1之间),并将其乘以Sigmoid的输出,以便我们只输出我们决定的部分。
在语言模型的例子中,因为他就看到了一个代词,可能需要输出与一个动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
对于语言模型示例,由于它只是看到一个代词,它可能需要输出与动词相关的信息来确定下一步发生什么。例如,它可能会输出代词是单数还是复数,以便我们知道动词应该是什么形式的。
6、LSTM 的变体
到目前为止我所描述的是一个很正常的LSTM。但并不是所有的LSTM都与上述相同。事实上,似乎几乎每一篇涉及LSTM的论文都使用了一个略有不同的版本。差异很小,但值得一提的是它们。
一个受欢迎的LSTM变体是Gers & Schmidhuber (2000)提出来的,他们在里面加入了“peephole connections”。这意味着让门层也会接受cell状态的输入。
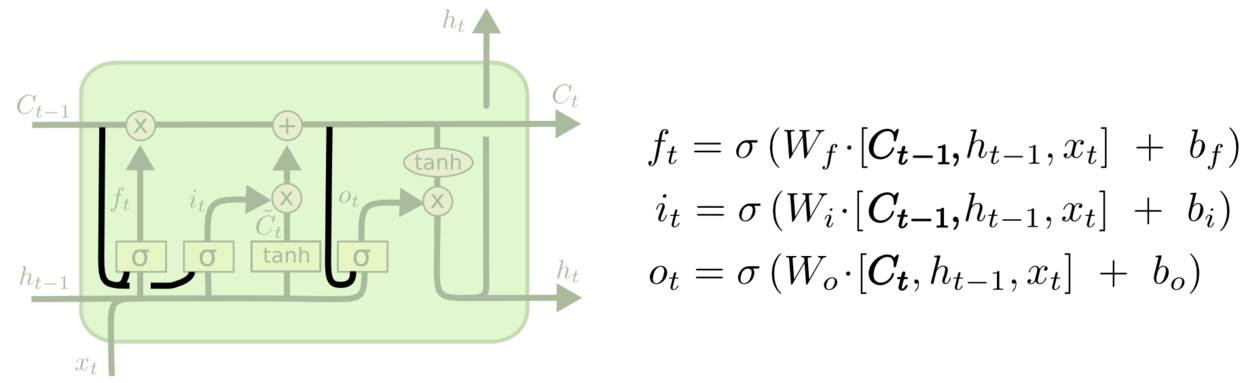
上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
另一种变体是使用耦合的忘记和输入门。而不是单独决定要忘记什么信息和添加新信息,我们一起做出这些决定。我们仅仅会当我们将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态 。
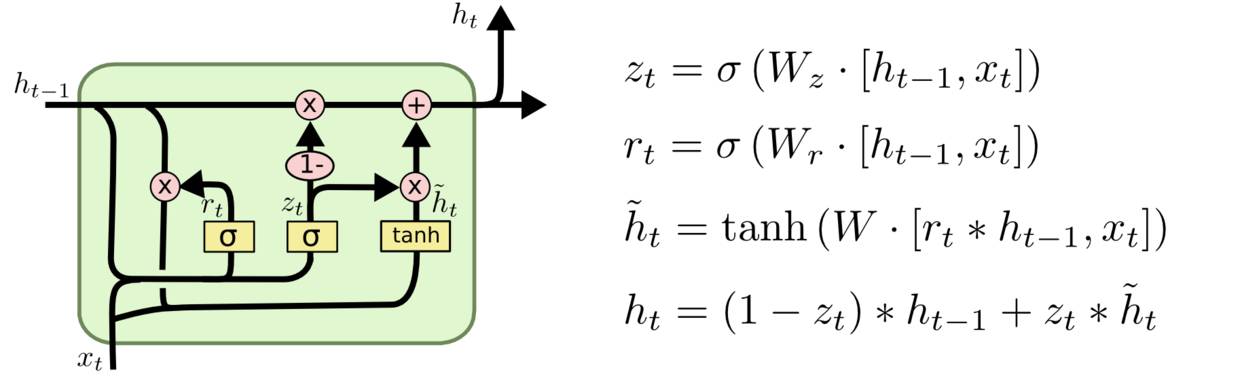
LSTM的一个稍微更显着的变化是由Cho,et al(2014)介绍的门控循环单元——GRU。 它将忘记和输入门组合成一个单一的“更新门”,它还合并了cell状态和隐藏状态,并进行了一些其他更改。所得到的模型比标准LSTM模型更简单,并且越来越受欢迎。
这些只是最显着的LSTM变体中的一些。还有很多其他的,如Yao, et al. (2015)提出的Depth Gated RNNs。。还有一些完全不同的处理长期依赖的方法,例如 Koutnik, et al. (2014)提出的Clockwork RNNs。
哪些变体最好?其中的差异真的重要吗?
Greff, et al. (2015) 给出了流行变体的比较,结论是他们基本上是一样的。Jozefowicz, et al. (2015)则在超过 1 万种 RNN 架构上进行了测试,发现一些架构在某些任务上也取得了比 LSTM 更好的结果。
7、结论
刚开始,我提到人们通过RNN实现了显着的成果。基本上所有这些都可以使用 LSTM 完成。对于大多数任务确实展示了更好的性能!
看着一组方程式,LSTM看起来很吓人。希望在这篇文章中一步步走过他们,使他们变得更加平易近人。
LSTM是我们用RNN获得的重要成功。很自然的想法:还会有更大的突破吗?研究人员的共同观点是:“是的!有一个下一步,那就是Attention!“这个想法是让RNN的每个步骤从一些较大的信息集合中挑选信息。例如,如果您使用RNN创建描述图像的标题,则可能会选择图像的一部分来查看其输出的每个字。事实上,Xu, et al.(2015)做到这一点.如果你想要深入探索Attention,这可能是一个有趣的起点!已经有一些使用
Attention令人兴奋的结果,似乎更多的还值得我们去探索...
Attention不是RNN研究中唯一令人兴奋的线索。例如Kalchbrenner, et al(2015)提出的Grid LSTM似乎很有前途。使用生成模型的RNN,诸如Gregor, et al. (2015)Chung, et al. (2015) 和 Bayer & Osendorfer (2015)提出的模型 也似乎很有趣。最近几年对于RNN来说已经是一个激动人心的时刻了,而后来的研究成果将会更加丰富。
8、PyTorch实现
循环神经网络 RNN 和 Bi-RNN
实现MNIST的分类
import torch
from torch import nn
from torch.autograd import Variable
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
torch.manual_seed(1)
# 超参
num_epochs = 1
batch_size = 64
TIME_STEP = 28 # rnn time step, 即图片的高
INPUT_SIZE = 28 # rnn input size, 即图片的宽
HIDDEN_SIZE = 64
NUM_LAYERS = 2
NUM_CLASSES = 10
BIDIRECTIONAL = True # 是否开启双向
learning_rate = 0.01
train_data = dsets.MNIST(
root='./mnist/',
train=True,
transform=transforms.ToTensor(),
download=True
)
# 看一下数据
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_data = dsets.MNIST(
root='./mnist/',
train=False,
transform=transforms.ToTensor()
)
# test_x shape (-1, 28, 28) value in range(0,1)
test_x = Variable(test_data.test_data, volatile=True).type(torch.FloatTensor) / 255.
test_y = test_data.test_labels
if torch.cuda.is_available():
test_x = test_x.cuda()
test_y = test_y.cuda()
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes, bidirectional):
super(RNN, self).__init__()
self.rnn = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size, # 隐层单元数
num_layers=num_layers, # 层数
batch_first=True, # 第一个维度设为 batch, 即:(batch, time_step, input_size)
bidirectional=bidirectional # 是否用双向
)
self.out = nn.Linear(hidden_size * 2, num_classes) if bidirectional else nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x: (batch, time_step, input_size)
# r_out: (batch, time_step, output_size)
# h_n: (n_layers, batch, hidden_size)
# h_c: (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None即隐层状态用0初始化
# 我们只需要最后一步的输出, 即(batch, -1, output_size)
out = self.out(r_out[:, -1, :])
return out
rnn = RNN(
input_size=INPUT_SIZE,
hidden_size=HIDDEN_SIZE,
num_layers=NUM_LAYERS,
num_classes=NUM_CLASSES,
bidirectional=BIDIRECTIONAL
)
print(rnn)
if torch.cuda.is_available():
rnn = rnn.cuda()
optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate)
loss_func = nn.CrossEntropyLoss()
for num_epochs in range(num_epochs):
for step, (x, y) in enumerate(train_loader):
b_x = Variable(x.view(-1, 28, 28)) # reshape x to (batch, time_step, input_size)
b_y = Variable(y)
if torch.cuda.is_available():
b_x = b_x.cuda()
b_y = b_y.cuda()
output = rnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = rnn(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, dim=1)[1].data.squeeze()
accuracy = sum(pred_y == test_y) / float(test_y.size(0))
print('num_epochs: ', num_epochs, '| train loss: %.4f' % loss.data[0], '| test accuracy: %.2f' % accuracy)
# 看一下10个结果
test_output = rnn(test_x[:10].view(-1, 28, 28))
pred_y = torch.max(test_output, 1)[1].data.cpu().numpy().squeeze()
print(pred_y, '预测值')
print(test_y[:10].cpu().numpy().squeeze(), '真实值')reference:
http://lawlite.me/2017/05/10/PyTorch/#1、卷积神经网络-CNN
http://www.cnblogs.com/nsnow/p/4562308.html
http://cs231n.github.io/convolutional-networks/
https://zhuanlan.zhihu.com/p/22038289
http://pytorch-cn.readthedocs.io/zh/latest/
https://github.com/pytorch/pytorch
https://morvanzhou.github.io/tutorials/machine-learning/torch/
明天继续推出:专知PyTorch深度学习教程系列-< 快速理解系列(三): 图文+代码, 让你快速理解GAN >,敬请关注。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“PyTorch”即可得。
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

了解使用专知-获取更多AI知识!
祝你中秋愉快,欢迎转发分享!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“ 阅读原文 ”,使用 专知!
展开全文



