【论文笔记】韩家炜团队AutoPhrase:从大量文本库中 自动挖掘短语
【导读】作为文本分析中的基础任务,短语挖掘旨在从文本语料库中获取质量短语,并 应用在信息获取、信息检索、分类构建和主题模型中。现存的这些方法大多依赖于复杂的语义分析器,在一些新领域的语料库中的效果似乎并不理想,而且还需要大量的人力。因此,在本文中提出一种新的模型AutoPhrase来自动挖掘任意语种的短语。
理想的自动短语挖掘方法应该是独立于不同领域,并且只需要最少的人力或语言分析器。因此提出了AutoPhrase框架,更深层次的避免了人工标注,并提高了性能。
提出了POS-Guided短语分割:提高了词性标记的性能;
本文提出新的自动短语挖掘框架AutoPhrase:独立于领域,只需要很少的人力或语言分析;
提出了一种鲁棒的、仅为正的远程短语质量估计训练方法,以最小化人工工作量。
Robust Positive-Only Distant Training
利用已有的知识库做远程监督训练,如维基百科,其中的高质量短语免费且数量多,远程训练过程中,使用这些词可以避免手工标注。
具体做法:
从通用知识库中的构建正样本
从给定的知识库中的获取负样本
训练大量基本分类器
将分类器的预测聚合起来
POS-Guided短语分割
利用词性信息来增加抽取的准确性。语言处理器应该权衡准确率和领域独立能力
对于领域独立能力,如果没有语言知识,准确率就会受限
对于准确性,依赖复杂的、训练好的语言分析器,就会降低领域独立能力
解决方法:将预先训练好的词性标记加入到文档集,以提高性能。
有效识别质量短语对于处理大规模文本数据来说十分重要。与提取关键短语相反,它远超单个文档的范围。使用文本检索算法通常会过滤一些词并将候选词限制为名词短语。使用预定义的词性规则,可以将名词短语标识为带有POS标签的候选单词。
本篇论文的目的是想实现从文件集中自动挖掘短语来获取质量短语,而不需要消耗人力。对于这个任务,输入为语料库(特定语言和特定领域的文本单词序列)和知识库,输出为一个按质量递减排列的短语列表。
质量短语被定义为一个单词序列成为一个完整语义单词的概率,满足以下条件:
流行度:在给定的文档集中,质量短语出现的频率应该要足够高
一致性:由于偶然,质量短语中的tokens发生的概率要高于预期
信息性:如果一个短语表达了一个特定的话题和概念,那这个短语就是信息化的
完整度:长频繁短语及其子序列均满足上述3个条件。当一个短语在特定的文档上下文中解释为一个完整的语义单元时,就被认为是完整的。
AutoPhrase会根据正负池对质量短语进行两次评估,分别是在短语分割的前和后。也就是说,POS-Guided短语分割需要一组初始的质量短语分数,预先根据原始频率估计分数,然后一旦特征值被纠正,就要重新估计分数。只有满足上述要求的短语才能被认为是质量短语。只有满足上述要求的短语才能被认为是质量短语。

AutoPhrase的第一部分(上图中的左部分)候选短语集合包含所有超过最小阈值的n-grams。这里的阈值指的是通过字符串匹配计算出的n-grams的原始频率。在实际中,设置短语长度的阈值n<=6,计算候选短语的的质量:
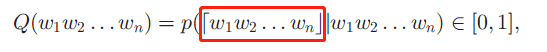
红框中指的是这些单词构成的短语,Q表示的短语质量评估,最初是通过数据中的统计特征学习的,目的是为了对一致性和信息性进行建模。要注意的是短语质量评估是独立于POS标签的,对于unigrams,只需将其词组质量设置为1。
为了强调完整度,短语分割会在每个句子中找到最好的分割方式。

在短语质量再评估的过程中,相关统计特征会基于它们的修改频率再计算,这就表示短语在所识别的分割中成为完整语义单元的次数。之后计算Q。
在这个部分,将会介绍两个新技术。首先,robust positive-only distant training通过利用质量短语来训练模型,其次,介绍POS标签,它可以使模型学习到语言相关信息。
Robust Positive-Only Distant Training
为了评估每一个质量短语的质量分数,需要人力来完成。在本篇文章中,介绍了一种不需要人工就可以完成的方法。
标签池
公共知识库(例如维基百科)中获取的高质量短语将其放在正池中;基于n-gram的候选短语熟练非常多,其中大多数质量比较差,因此,从给定语料库派生的候选短语如果不能匹配到公共知识库中的的任何高质量短语,那么就会用于填充嘈杂的负池。
降噪
如果基于嘈杂的负池训练分类器,就会漏掉一些给定语料库中的高质量短语,因为它们不存在于知识库中。因此,使用一个集成分类器。
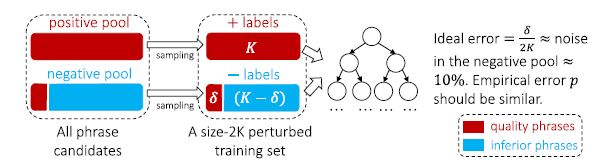
如图,对于每个基分类器,分别从正池和负池中随机抽取K个候选短语,并进行替换(考虑到规范的平衡分类场景),所有的候选短语中的2K大小的子集称之为扰动训练集,是因为图中的部分短语δ的标签是由正到负。为了使集成分类器能够减轻这种噪声的影响,需要使用训练误差最小的分类器,我们生成了一个未经修剪的决策树,以分离所有短语来满足这个需求。实际上,当扰动训练集中没有两个正负短语具有相同的特征值时,该决策树的训练精度始终能达到100%。这种情况下,它的理想误差是δ/2K,大约等于所有候选短语中中转换标签的比例。因此,K对于未修剪的决策树的准确性不敏感,在实验中设置为100。
上图中出现的采样过程,文中使用的是随机森林,将特定短语的短语质量得分计算为预测该短语为质量短语的所有决策树的比例。假如在随机森林中有T个树,可以将整体错误估计为,超过一半的分类器将给定短语候选者误分类的概率。
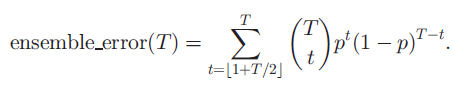
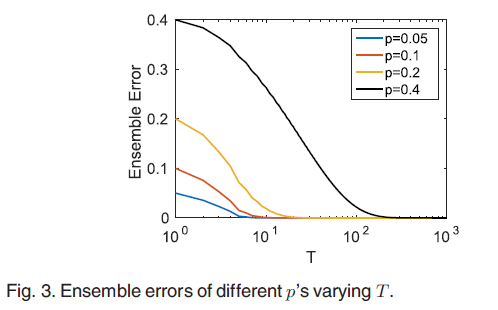
从上图中可以看出随着T的增长,整体误差接近于0。实际操作中,由于模型偏差带来的附加误差,T需要设置的大一些。
POS-Guided Phrasal Segmentation
语料库为处理过的长度为n的POS-tagged的词序列:
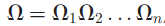
这里的每个因数表示的都是一对,即词和对应的词性。POS的短语分割由边界索引序列B促使该序列划分为m个片段,这里的B={b1,b2,……,bm}满足1=b1<b2<……<b_m+1=n+1。第i个部分指的是:
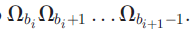
与之前的方法相比,POS-guided短语分割以一种上下文感知的方式来加强完整度。另外,POS标签提供较浅的语义知识,这样可以提神短语识别的精确度,尤其是句子成分的边界。
对于给定的长度为n的POS标签序列:
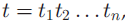
标签子序列用t_[l,r)表示,其标签子序列的质量分数被定为:对应词序列是完整语义单元的条件概率:
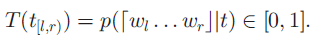
T是为了通过正确识别POS序列来奖励短语,其特殊形式为:
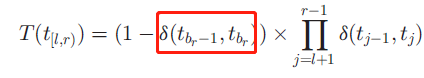
红框中表示的是给定文档短语中的POS词性标签tbr-1精确位于POS词性标签tbr之前的概率。上述这个公式,第一个乘数表示的是在词索引r-1与r之间的短语边界,然而后边的乘数表示的是在t中的所有POS词性标签在同样的短语的概率。
从数学意义上而言:
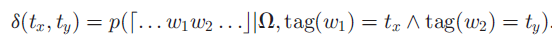
因为它依赖文档如何分割短语,δ被统一初始化,在短语分割的过程中被学习。现在,计算了短语质量Q与POS质量T,然后定义POS-guided的短语分割模型。
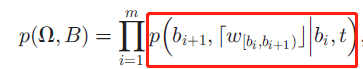
这里红框是单词序列w的第i个质量短语的条件概率。
对于每个分割段,给定POS词性标签和起始索引b_i,生成过程如下:
1)通过POS质量生成末端索引b_i+1
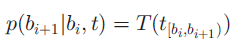
2)给定两端bi和bi+1,根据在长度为两端点的差值的所有分割段上的多项式分布生成单词序列w
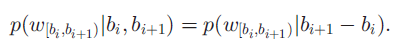
3)最后,根据质量生成指标来判断是否形成质量分割
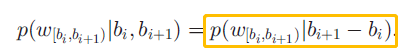
将以上三步合成,定义为:
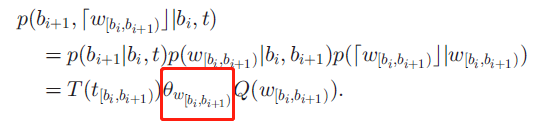
为方便起见用红框表示黄色框的内容。
因此,存在以下三个问题:
1)学习每个词的 θ_u和候选短语u
2)学习每个POS标签对δ(tx,ty)
3)当θu和δ(tx,t_y)固定时推导B
采用最大后验原理,最大限度地模拟联合对数似然:
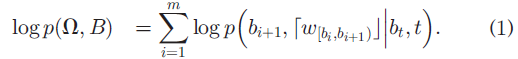
给定θu和δ(tx,t_y),最大化公式(1)来找到最好的分割,论文中采用一种用于POS引导短语分割的搞笑动态编码算法:

当S和u固定时,δ(tx,ty)的解为:
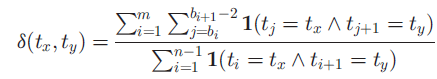
这里的1表示的是身份指标,δ(tx,ty)表示的是在所有给定的(tx,ty)对中未匹配的比率。
同样,当S和u固定时,θ_u的解为:
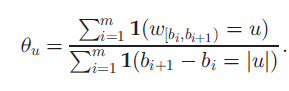
可以看出,θ_u是u成为完整分割段的时间。
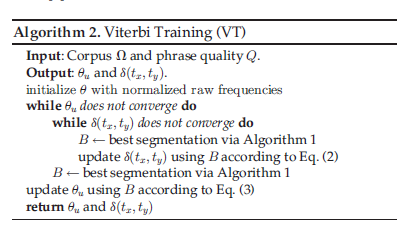
算法2中,选择Viterbi Training来分别优化参数,因为Viterbi Training传播快,并且可以为类似于隐马尔可夫模型的任务提供稀疏和简单的模型。
Complexity Analysis
框架中最耗时的部分如n-gram、特征提取、POS短语分割的时间复杂度,均为O(||),并假设短语中最大单词是一个小常熟,其中||是语料中单词的总数。因此,每个组件可以以无固定的方式通过短语或句子分组进行合并。
此部分,将应用本文提出的模型来挖掘3个领域(论文、商业讨论、维基文章)的质量短语,并使用3种语言(英语、西班牙语、中文)。实验中,对比了其他方法,并验证了远程监控训练的鲁棒性,结合POS标签进行短语分割的方式也得到了证明。
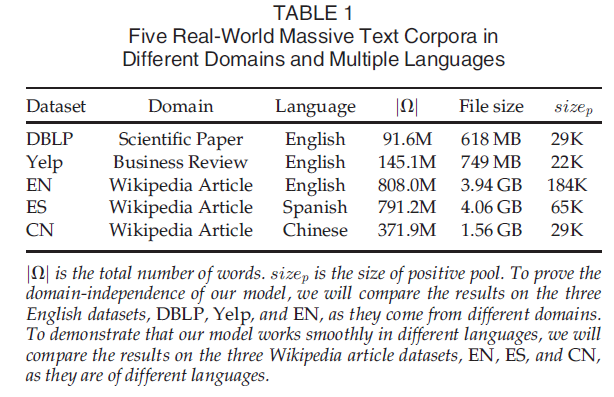
数据集
为了验证本文提出的两种新颖的方法,选取了3种语言5个语料库。在每个数据集上,提取的热门词和生成的短语候选词之间的交集作为正池,因此不同语言的不同数据中,正池的大小会有所不同。
对比的方法
SegPhrase/WrapSegPhrae:SegPhrase用于挖掘英语短语,在短语挖掘,关键短语获取,名词短语分块应用上十分出色。WrapSegPhrase在SegPhrase的基础上拓展到了不同语言上。这两种方法都需要人力来完成标注质量短语。
Parser-Based Phrase Extraction,使用复杂的语义处理器,考虑以下两种排名试探法:
TF-IDF通过给定文档中的词组词频和文档逆频来对提取的短语进行排名;
TextRank:用于关键字提取的无监督基于图的排名模型。
Pre-trained Chinese Segmentation Models,与英语和西班牙语不同,由于汉语中间没有空格,因此对汉语的短语进行了深入研究,最有效和最受欢迎的方法:
AnsjSeg:应用于中文语料,它整合了CRF(Conditional Random Fields)和基于n-gram的HMMs(Hidden Markov Models)。
JiebaPSeg:应用于中文文本分割,基于前缀字典结构构建有向无环图,然后使用动态编程找到最可能的组合,对于未知短语,将基于HMM模型与Viterbi算法一起使用。
注意:所有的Parser-Based Phrase-Extraction和中文分割模型都要基于通用预料进行预训练。
AutoSegPhrase是AutoPhrase 和 Seg-Phrase的结合,它可以有效用于没有POS标签的时候。
实验设置
实战:预处理包括Lucene 和 Stanford NLP的分词器,以及TreeTagger的POS标签,实验中使用Java与C++。
默认参数:设置最小支持阈值σ为30,短语长度为6。其他方法中的参数按着原始论文中设置。
人工注释:依靠人类评估者来判断无法通过任何知识库识别的短语的质量。更具体地说,在每个数据集上,我们从实验中每种方法的预测短语中随机抽取500个这样的短语。这些选定的短语在共享池中,并由3位审阅者独立评估。当遇到不熟悉的短语时,我们允许审阅者使用搜索引擎。根据多数投票的规则,该词组中的短语至少收到两个肯定的注释,即为优质短语。
评估指标:使用准确率与召回率,另外采用area under the curve(AUC)作为一种度量,AUC值得是precision-recall 曲线下的面积。
整体结果
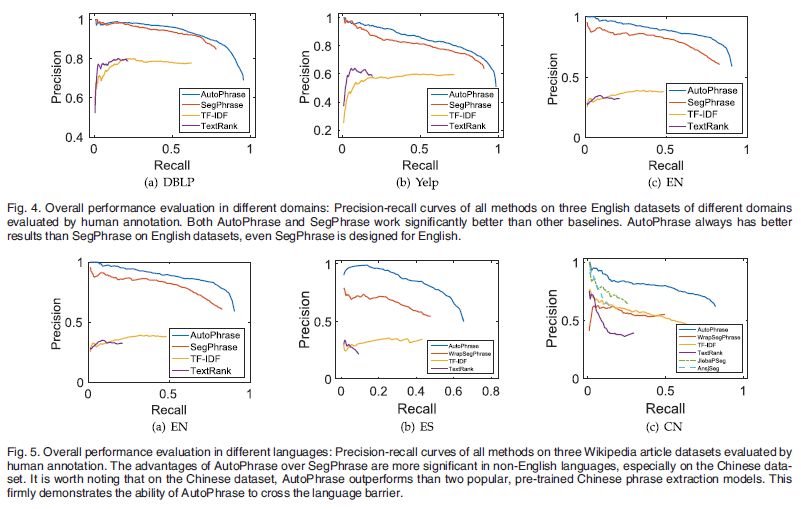
上图中明显看出AutoPhrase效果最好,并能够以最少的人力来支持不同领域并支持多种语言。
Distant Training Exploration
为了比较远程训练和领域专家标记,尝试使用特定的数据集DBLP和Yelp。除了标签选择不同以外,分类器中的所有配置均相同,并提出了四个训练池:
EP:专家给的正池
DP:从通用知识集中挑选的正池的一个集合
EN:专家给的负池
DN:所有未标签的候选短语形成的负池
结合四个训练池,我们重新组合4个变体:EPEN (in SegPhrase), DPDN(in AutoPhrase), EPDN, 和DPEN。
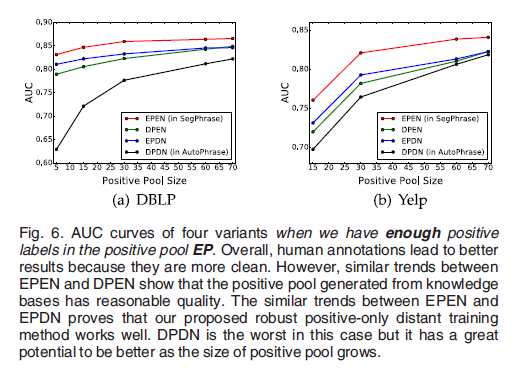
结果对比分析:
EPEN与DPEN:他们有相似的曲线走向,并且EPEN比DPEN的效果好,因此可以得出,尽管DPEN的质量评估工作稍差,但是从知识库中生成的正池具有合理的质量。
EPEN与EPDN:之间存在明显的间隔且走向相似表明嘈杂的负池与专业的负池相比略逊色,但其效果还可以。
当正池大小受限时,DPDN的效果最差,然而,远距离训练会产生更大的正池,当正池足够大时,远程训练是否能够战胜领域专家呢?
从上图看当正池足够大时,远程训练战胜了领域专家。在DBLP上,理想的正池大小为700左右,Yelp上大致为1600。
POS-Guided Phrasal Segmentation
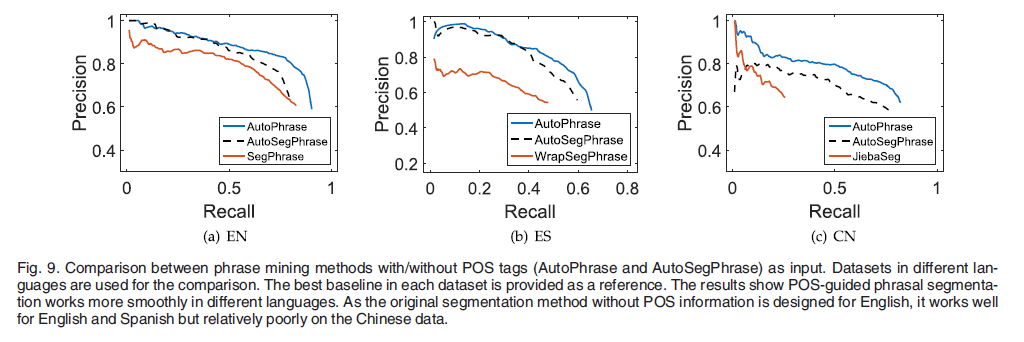
在英语数据集上,AutoPhrase效果比 AutoSegPhrase好,在西班牙语上效果差不多,但是在中文数据集上可以明显地看出AutoPhrase的效果最好。
因此,由于特定语言的额外上下文信息和句法信息,在短语分割过程中合并POS标签的效果更好。
AutoPhrase可以额外获取单个词,召回率可以提高10%至30%,用3个不同的数据集:EN, ES和CN来进行评估。
考虑到质量短语的评估标准,因为单个词短语不能被分解为2个或更多部分,一致性和完整度就不再考虑,因此,修改了评估单个词的质量标准:
流行性:质量短语要多次出现在给定的文本库中
信息性:如果该短语表示特定的主题或概念,则它是提供信息的
独立性:在给定的文档中,高质量的单字短语很可能是完整的语义单元
实验部分,我们采用相似的人工注释,不同的是,我们从每种方法的返回短语中随机抽取了500个Wiki-uncovered短语。因此,就有了新的EN,ES,CN数据集,类内关系超过0.9。
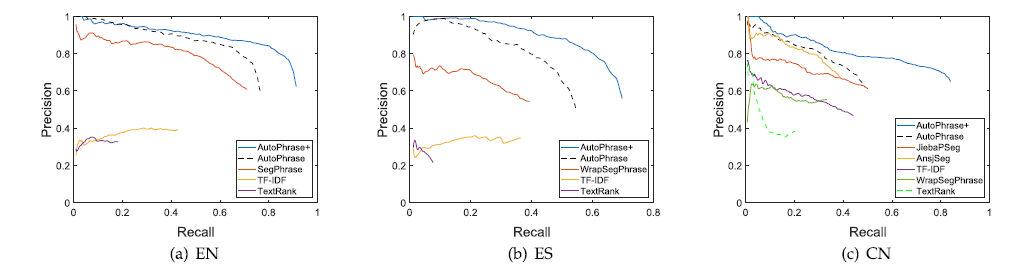
从图中可以看出明显的优势,在中文数据集中可以观察到最显着的recall间隔,因为中文中优质单词短语的比例最高。
本文提出的自动短语挖掘框架,其中运用两种新的刚发:远程训练和POS短语分割,实验表明AutoPhrase优于其他短语分割的方法并且支持多种语言,此外单个词短语10%-30%的召回中效果较好。



展开全文



