Google机器翻译新论文-更好更高效的演化transformer结构,提升机器翻译到新水平
【导读】近期,Google公布了 AI新论文-新的transformer结构,演化transformer,更好更高效适用于小规模任务。谷歌大脑最新研究提出通过神经架构搜索寻找更好的 进化 Transformer,以实现更好的性能,在四个成熟的语言任务(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十亿词语言模型基准(LM1B))上的表现均优于原版 Transformer。

The Evolved Transformer

论文链接:https://arxiv.org/abs/1901.11117
http://www.zhuanzhi.ai/paper/8819f347ddd92dc8f5bd099f2356b28a
【论文便捷获取】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ETrans” 就可以获取《The Evolved Transformer》的下载链接~
【摘要】
最近的工作突出了Transformer架构处理序列任务的优势。与此同时,神经架构搜索已经发展到可以超越人类设计模型的程度。这项工作的目标是使用搜索来找到更好的Transformer架构。我们首先构建了一个大型搜索空间,其灵感来自前馈顺序模型的最新进展,然后运行进化结构搜索,用Transformer来初始化。为了在计算成本高昂的WMT 2014英德翻译任务中有效地运行此搜索,我们开发了渐进式动态障碍方法,该方法允许我们为更有希望的候选模型动态分配更多资源。实验表明,我们的模型——演化Transformer - 在四个完善的语言任务中表现出对Transformer的持续改进:WMT 2014 English-German, WMT 2014 English-French, WMT 2014 English-Czech and LM1B。在大型模型中,演化Transformer的效率是FLOPS中Transformer的两倍,而不会降低质量。在一个小得多的 - 适合移动设备 - 模型尺寸为~7M参数的情况下,演化Transformer在WMT'14英语 - 德语上的表现优于变压器0.7 BLEU。
方法
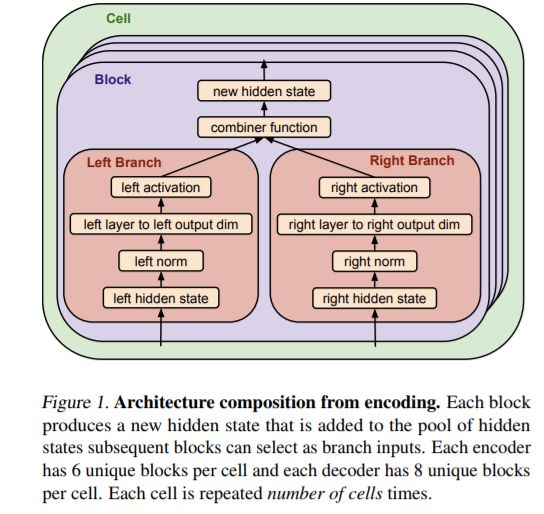
首先定义描述神经网络架构的基因编码;然后,从基因编码空间中随机采样创建一个初始种群来创建个体。基于这些个体在目标任务上描述的神经网络的训练为它们分配适应度(fitness),再在任务的验证集上评估它们的表现。然后,研究者对种群进行重复采样,以产生子种群,从中选择适应度最高的个体作为亲本(parent)。被选中的亲本使自身基因编码发生突变(编码字段随机改变为不同的值)以产生子模型。然后,通过在目标任务上的训练和评估,像对待初始种群一样为这些子模型分配适应度。当适应度评估结束时,再次对种群进行抽样,子种群中适应度最低的个体被移除,也就是从种群中移除。然后,新评估的子模型被添加到种群中,取代被移除的个体。这一过程会重复进行,直到种群中出现具备高度适应度的个体,这在本文中表示性能良好的架构。
结果
在此章节中,我们首先对自己的搜索方法、动态进化障碍以及其他进化搜索方法的表现做了基准测试。我们然后设置了 Evolved Transformer 以及与 Transormer 比对的基准。
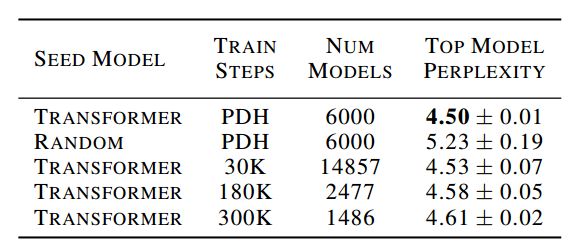
表 1:各种搜索设置的顶级模型验证困惑度。选择出的模型数量平衡了资源消耗。
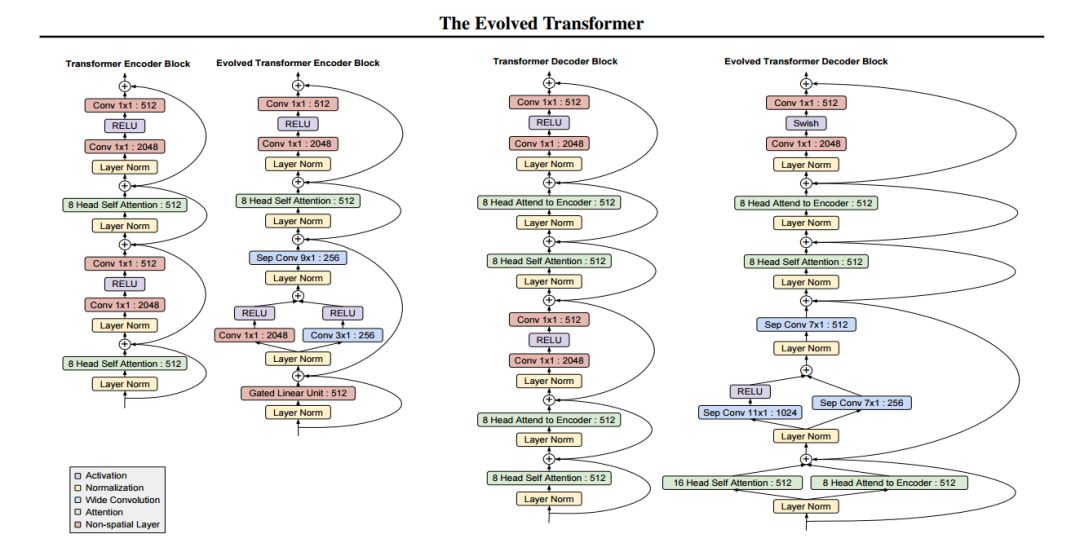
图 3:Transformer 和 Evolved Transformer 的架构单元。架构最值得注意的四个方面是:1. 宽泛的深度可分离卷积;2. 门控线性单元;3. 分支结构;4.swish 激活函数。ET 编码器和解码器分别独立开发宽卷积的分支下段。在两个架构中,后一段都和 Transformer 相同。
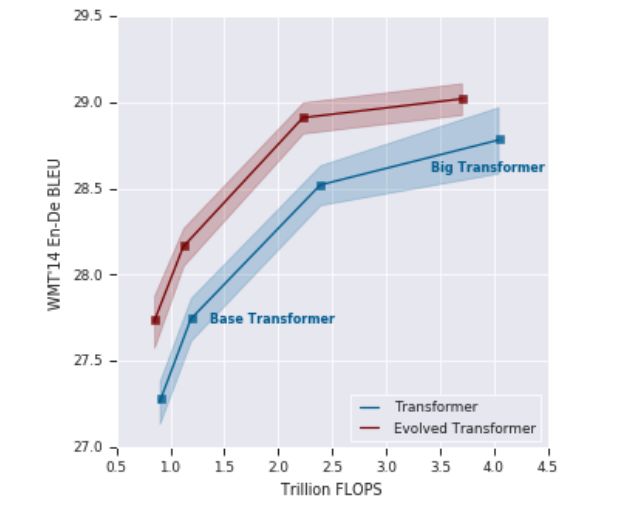
图 4:Evolved Transformer 和 Transformer 在各种 FLOPS 大小上的表现对比。
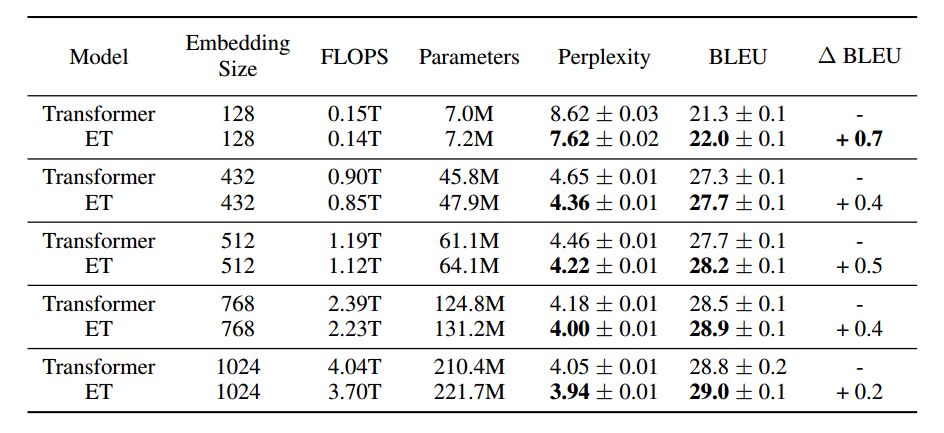
表 2:在 8 块英伟达 P100GPU 上的编码器-解码器 WMT'14 对比。基于可用资源,每个模型训练 10-15 次。困惑度在验证集上进行计算,BLEU 在测试集上计算。
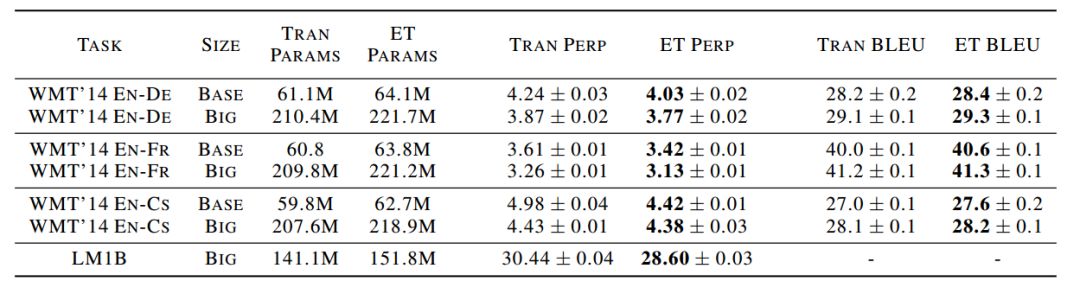
表 3:在 16 块 TPU v.2 上训练的 Transformer 和 ET 的对比。在 Translation 任务上,困惑度是在验证集上计算的,BLEU 是在测试集上计算的。对 LM1B 任务,困惑度是在测试集上计算的。ET 在所有任务上展现出了至少一个标准偏差的一致性改进。在基础大小上,它超越了所有的搜索,在英法和英捷任务上的 BLEU 值提高了 0.6。
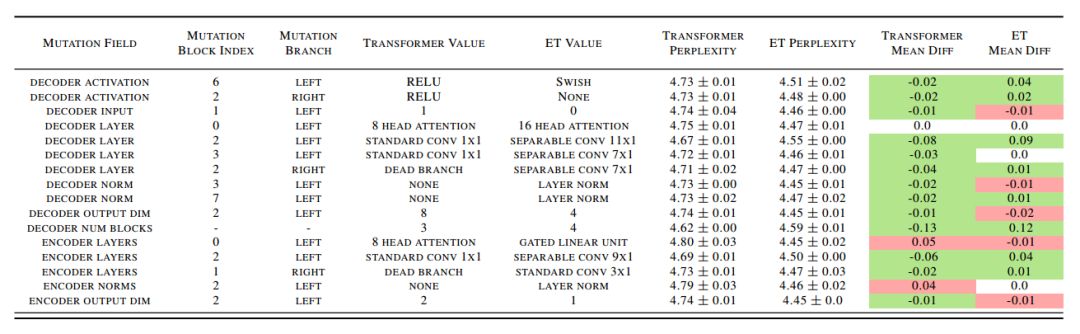
表 4:突变消除。前 5 列描述了每种突变。在 WMT『14En-De 验证集上强化的 Transormer 和 ET 困惑度在第 6 和第 7 列中,第 7、8 列展示了无增强基础模型困惑度均值和增强模型困惑度均值之间的不同。红色单元表示相对应的突变损害整体表现的证据。绿色单元表示突变有益于整体表现的相对应证据。
参考资料:
论文链接:https://arxiv.org/abs/1901.11117
机器之心-https://mp.weixin.qq.com/s/C0p1U0-x6aRipvYJItn8-g
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



