【干货】对抗自编码器PyTorch手把手实战系列——PyTorch实现自编码器
即使是非计算机行业, 大家也知道很多有名的神经网络结构, 比如CNN在处理图像上非常厉害, RNN能够建模序列数据. 然而CNN, RNN之类的神经网络结构本身, 并不能用于执行比如图像的内容和风格分离, 生成一个逼真的图片, 用少量的label信息来分类图像, 或者做数据压缩等任务. 因为上述几个任务, 都需要特殊的网络结构和训练算法 .
有没有一个网络结构, 能够把上述任务全搞定呢? 显然是有的, 那就是对抗自编码器Adversarial Autoencoder(AAE) . 在本文中, 我们将构建一个AAE, 来压缩数据, 分离图像的内容和风格, 用少量样本来分类图像, 然后生成它们。
本系列文章, 专知小组一共分成四篇讲解:
自编码器, 以及如何用PyTorch实现自编码器
对抗自编码器, 以及如何用PyTorch实现对抗自编码器
自编码器实例应用: 被玩坏的神经画风迁移(没办法太典型了)
自编码器实例应用: 用极少label分类MNIST
PyTorch实现自编码器
首先我们先回顾一下什么是自编码器 , 然后用PyTorch 进行简单的实现。
1.自编码器
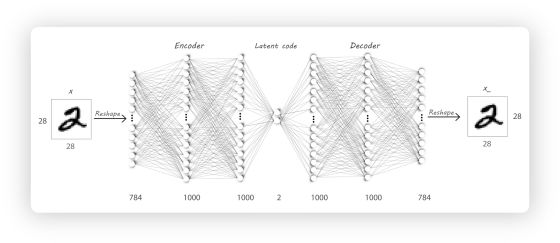
如图所示, 自编码器的输入和输出是一样的, 也就是说, 它不需要监督信息(label), 它主要有两部分构成:
• 编码器(Encoder) : 输入数据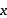
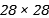
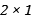
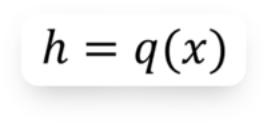
• 解码器(Decoder) : 输入数据为上一步的输出数据h, 它努力把h重构成x, 上图的例子中, Decoder需要把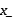
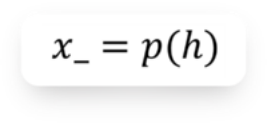
这个模型似乎是一个天然的降维模型. 但是, 除了降维,Autoencoder还能干什么?
图片降噪(Image Denosiong), 输入嘈杂的图像, Autoencoder可以生成清晰无噪声的图像. 当把数据输入自编码器后, 我们可以强制让自编码器的隐层学习更鲁棒的特征, 而不是仅仅识别他们, 这样的自编码器, 在下图左边的图上进行训练, 就可以把中间的噪声数据, 重建成右边的样子。
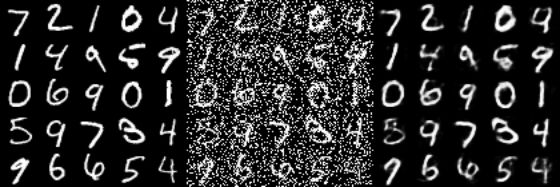
语义哈希, 这可以降低数据的维度, 加速信息检索, 目前有非常的人在研究这一方向.
生成模型, 比如本系列文章要介绍的Adversarial Autoencoder(AAE)
其他大量应用
2.PyTorch实现
我们先从简单的全连接网络开始我们的第一部分.
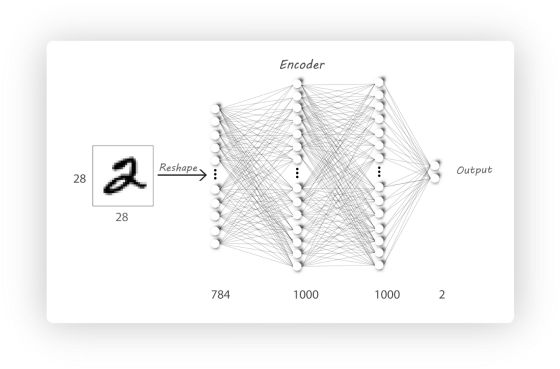
这个Encoder包含
import torch
import torch.nn as nn
encoder = nn.Sequential(
nn.Linear(28*28, 1000)
nn.ReLU()
nn.Linear(1000, 1000)
nn.ReLU()
nn.Linear(1000, 2)
)
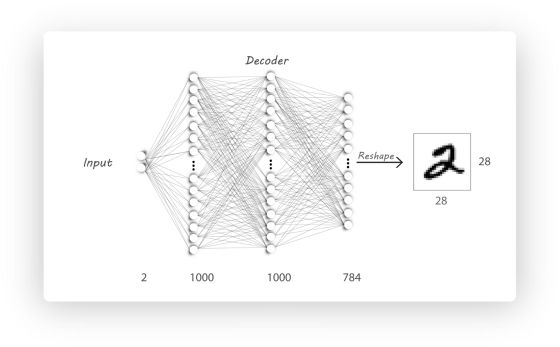
decoder = nn.Sequential(
nn.Linear(2, 1000)
nn.ReLU()
nn.Linear(2, 1000)
nn.ReLU()
nn.Linear(1000, 28*28)
nn.Sigmoid() #压缩到0-1之间
)
所以, 整个模型是:
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 1000)
nn.ReLU()
nn.Linear(1000, 1000)
nn.ReLU()
nn.Linear(1000, 2)
)
self.decoder = nn.Sequential(
nn.Linear(2, 1000)
nn.ReLU()
nn.Linear(2, 1000)
nn.ReLU()
nn.Linear(1000, 28 * 28)
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
模型实现完成后, 我们要准备一下数据:
import torchvision
import torch.utils.data as Data
BATCH_SIZE = 64
DOWNLOAD_MNIST = False # 本地没有数据的话, 设成True可以下载
# 从torchvison里加载MNIST数据, 然后转成Tensor
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True,
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST,
)
# 加载数据, 维度是(batch_size, n_channel, n_width, n_height )
train_loader = Data.DataLoader(dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True)
我们选择MSE损失函数来度量重构出来的图像
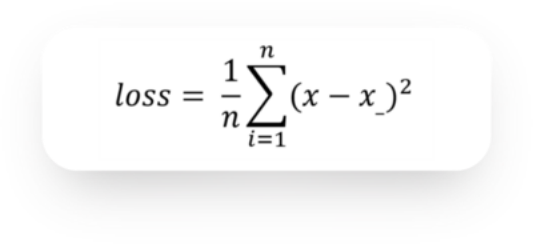
loss_func = nn.MSELoss()
LR = 0.005
# 用Adam来优化参数
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
接下来就可以实现训练步骤了:
EPOCH = 10
autoencoder = AutoEncoder()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
b_x = Variable(x.view(-1, 28*28)) # reshape 成(batch, 28*28)
b_y = Variable(x.view(-1, 28*28))
b_label = Variable(y) # batch label
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # 算误差
optimizer.zero_grad() # 清空累计导数
loss.backward() # 求导
optimizer.step() # 优化一步
if step % 100 == 0:
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0])
可以看一下重建的图像怎么样:

我们可以观察到, 输入的这张3的图片, 一些奇怪的地方呗去掉了(3的左上角).
接下来, 让我们看一下latent code, 它只有2维, 我们可以随便填一个值让Decoder去生成图片, 比如我们认为的令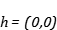

这好像是个6的图片, 当然也可能是0, 不管怎么说, 这不是一个清晰的数字图片. 这是因为Encoder的输出并不能覆盖整个2维空间(它的输出分布有很多空白)。 因此,如果我们输入一些Decoder没见过的值,我们会看到一下奇怪的输出图像。 这可以通过在生成latent code 时, 将Encoder的输出限制为随机分布(比如,均值为0.0和标准偏差为2.0的正态分布)。 Adversarial Autoencoder就是这么做到的,我们将在第2部分中看看它的实现。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



