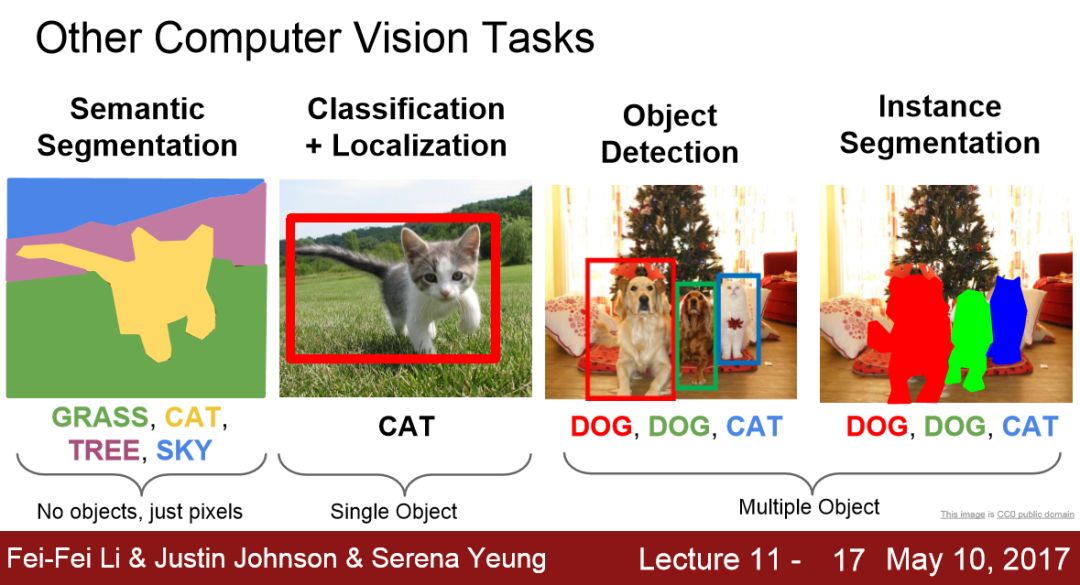
计算机视觉的不同任务
【导读】 在计算机视觉领域,有许多不同的任务:图像分类、目标定位、目标检测、语义分割、实例分割、图像字幕等。
作者 | Luozm
整理 | Xiaowen
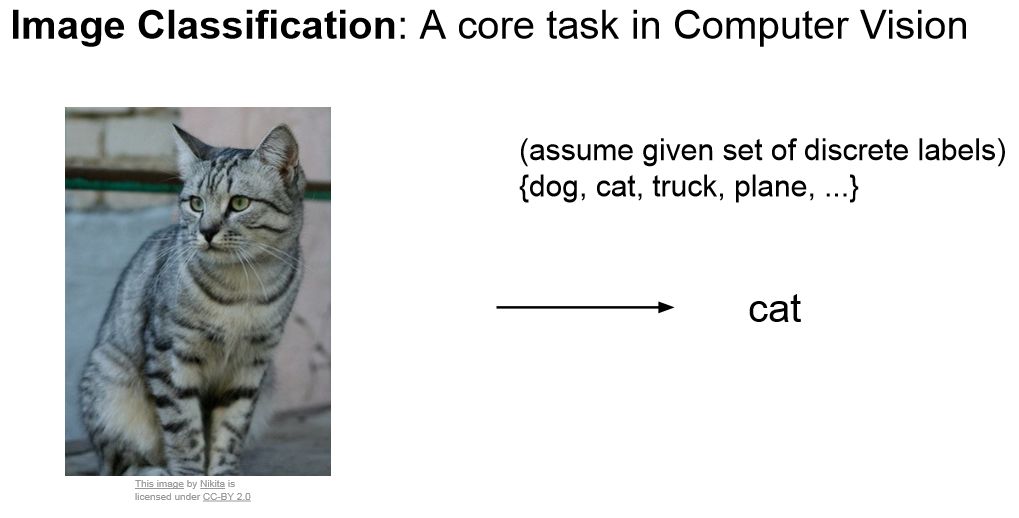
1 图像分类 Image Classification
Image Classification problem is the task of assigning an input image one label from a fixed set of categories. This is one of the core problems in CV that, despite its simplicity, has a large variety of practical applications. Moreover, as we will see later, many other seemingly distinct CV tasks (such as object detection, segmentation) can be reduced to image classification.
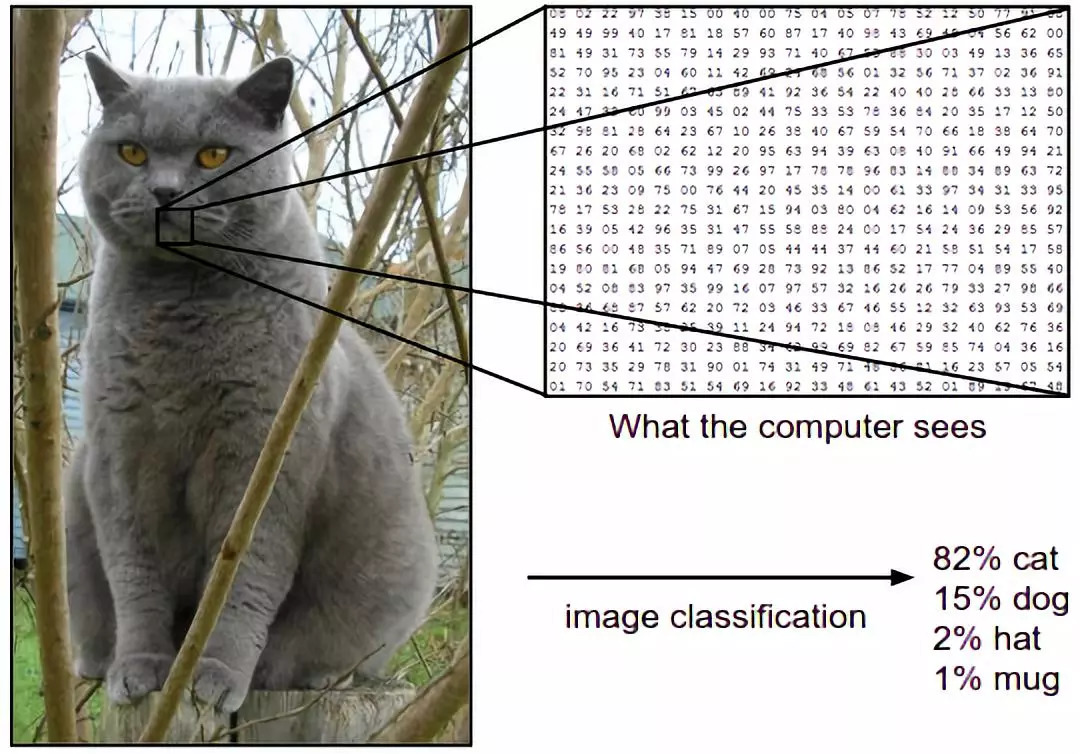
For example, in the image below an image classification model takes a single image and assigns probabilities to 4 labels, {cat, dog, hat, mug}. As shown in the image, keep in mind that to a computer an image is represented as one large 3-dimensional array of numbers. In this example, the cat image is 248 pixels wide, 400 pixels tall, and has three color channels Red,Green,Blue (or RGB for short). Therefore, the image consists of 248 x 400 x 3 numbers, or a total of 297,600 numbers. Each number is an integer that ranges from 0 (black) to 255 (white). Our task is to turn this quarter of a million numbers into a single label, such as “cat”.
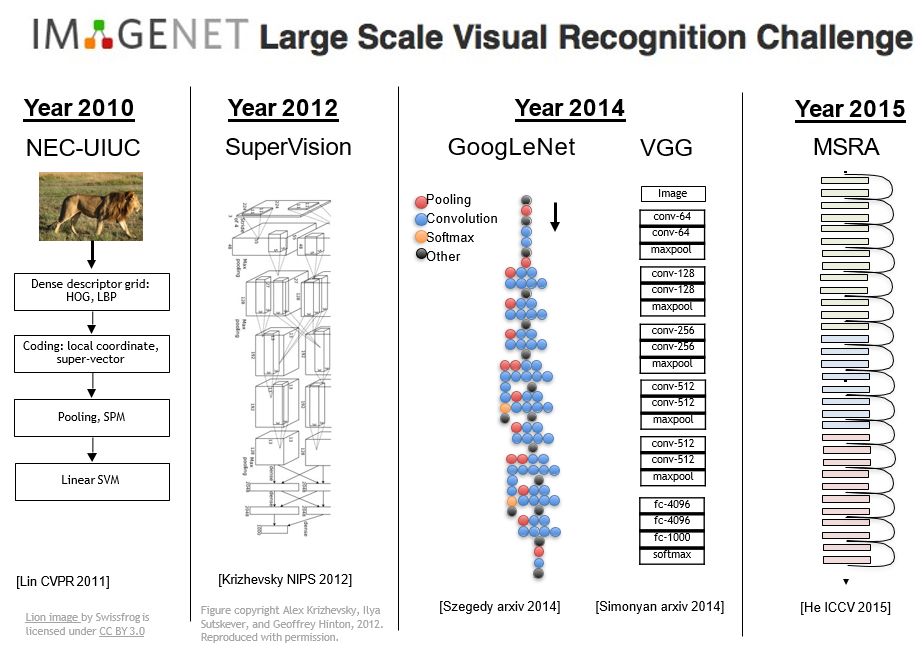
1.1 Classification in ImageNet
The definition of Image Classification in ImageNet is:
For each image, algorithms will produce a list of at most 5 object categories in the descending order of confidence. The quality of a labeling will be evaluated based on the label that best matches the ground truth label for the image. The idea is to allow an algorithm to identify multiple objects in an image and not be penalized if one of the objects identified was in fact present, but not included in the ground truth. For each image, an algorithm will produce 5 labels . The ground truth labels for the image are with n classes of objects labeled. The error of the algorithm for that image would be
where if and 1 otherwise. The overall error score for an algorithm is the average error over all test images. Note that for this version of the competition, , that is, one ground truth label per image.
1.2 Typical solutions & models
The image classification pipeline: We’ve seen that the task in Image Classification is to take an array of pixels that represents a single image and assign a label to it. Our complete pipeline can be formalized as follows:
Input: Our input consists of a set of N images, each labeled with one of K different classes. We refer to this data as the training set.
Learning: Our task is to use the training set to learn what every one of the classes looks like. We refer to this step as training a classifier, or learning a model.
Evaluation: In the end, we evaluate the quality of the classifier by asking it to predict labels for a new set of images that it has never seen before. We will then compare the true labels of these images to the ones predicted by the classifier. Intuitively, we’re hoping that a lot of the predictions match up with the true answers (which we call the ground truth).
Models: There are many models to solve Image classification problem.
2 目标定位 Object Localization
In fact, this is the most confusing task when I first look at ImageNet challenges.
This is a sort of intermediate task in between other two ILSRVC tasks, image classification and object detection. In image classification you have to assign a single label to an image corresponding to the “main” object (eventually, the image can contain multiple objects). The classification + localization requires also to localize a single instance of this object, even if the image contains multiple instances of it. This task is also called “single-instance localization”.2
While It’s pretty easy for people to identify subtle differences in photos, computers still have a ways to go. Visually similar items are tough for computers to count. For instance, consider this photo of a family of foxes camouflaged in the wild - where do the foxes end and where does the grass begins?

2.1 LOC in ImageNet
The definition of localization in ImageNet is:
In this task, an algorithm will produce 5 class labels and 5 bounding boxes , one for each class label. The ground truth labels for the image are with n classes labels. For each ground truth class label , the ground truth bounding boxes are where is the number of instances of the object in the current image. The error of the algorithm for that image would be
where if and has over 50% overlap, and otherwise. In other words, the error will be the same as defined in classification task if the localization is correct(i.e. the predicted bounding box overlaps over 50% with the ground truth bounding box, or in the case of multiple instances of the same class, with any of the ground truth bounding boxes), otherwise the error is 1(maximum).

2.2 Typical solutions & models
See more detailed solutions on CS231n(16Winter): lecture 83.
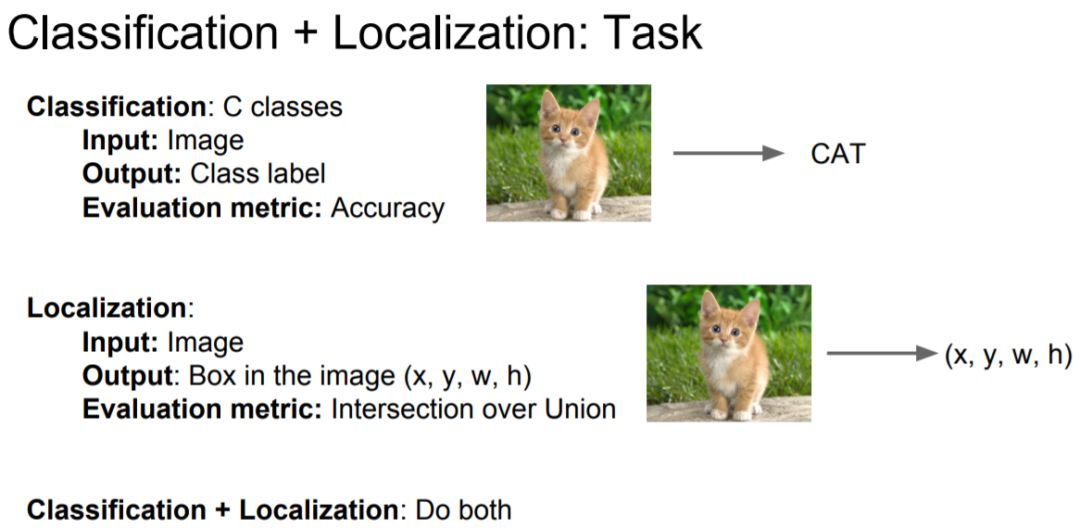
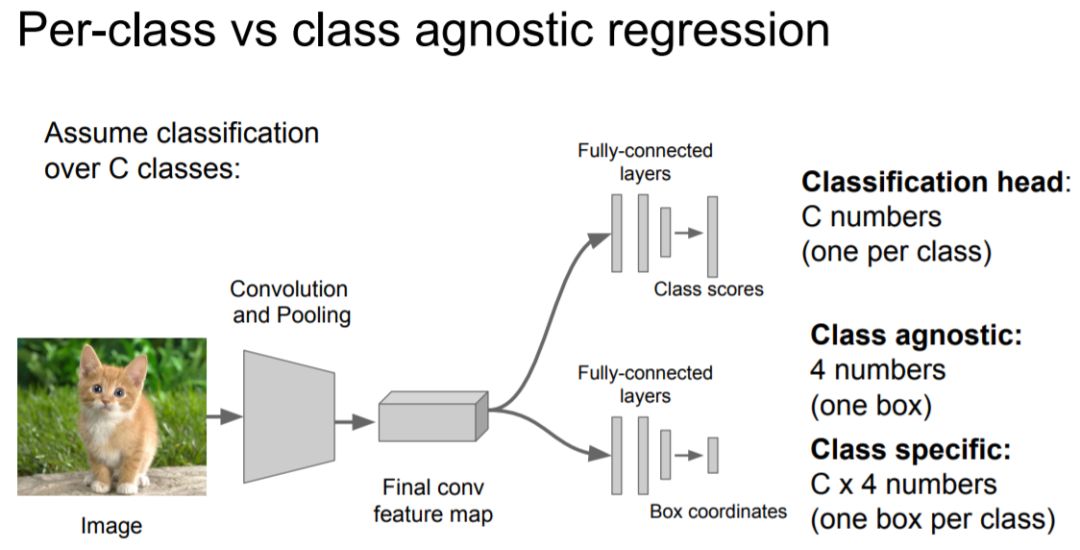
Treat LOC like regression problem: Other questions:
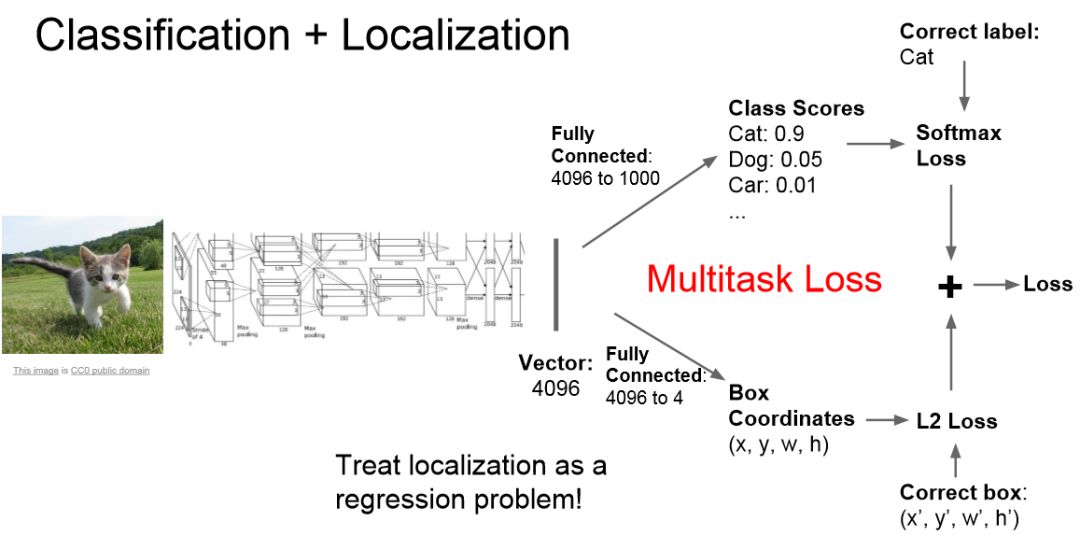
Train a classification model (AlexNet, VGG, GoogLeNet);
Attach new fully-connected “regression head” to the network;
Train the regression head only with SGD and L2 loss;
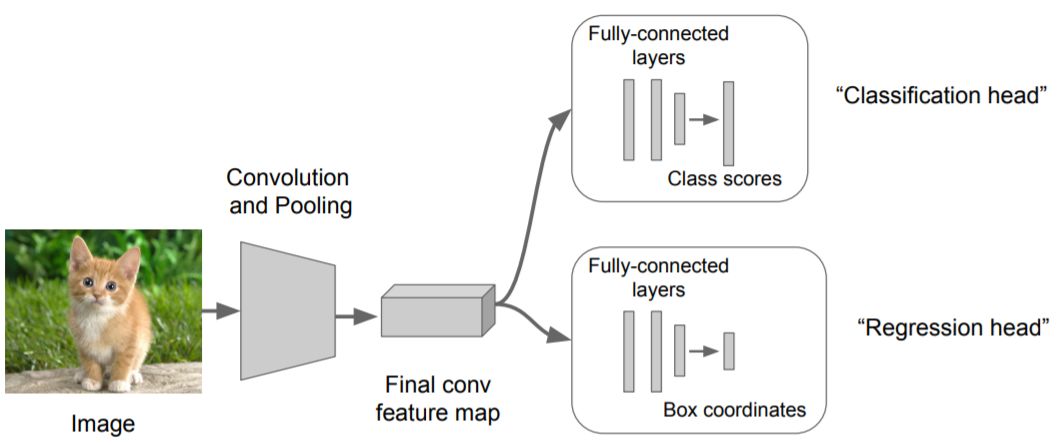
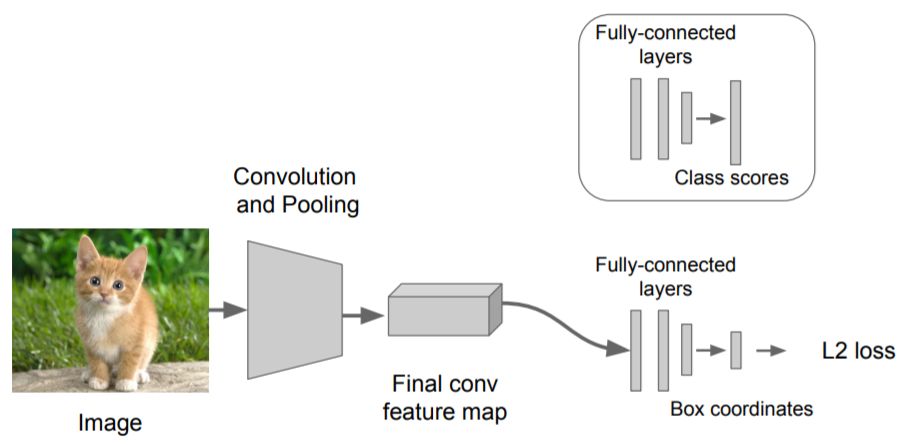
4. At test time use both heads.
Other questions:
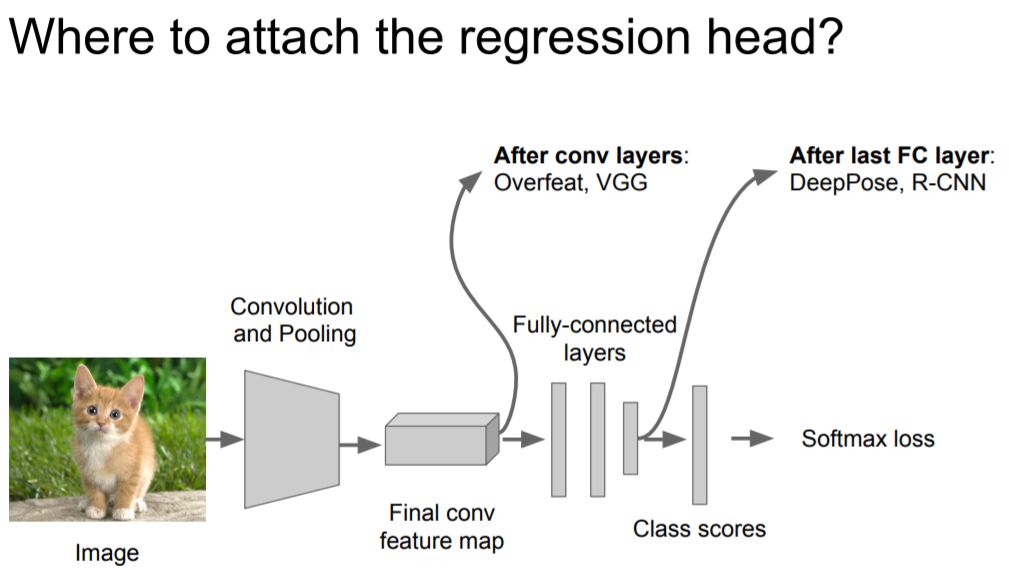
Using sliding Window:
Run classification + regression network at multiple locations on a high-resolution image;
Convert fully-connected layers into convolutional layers for efficient computation;
Combine classifier and regressor predictions across all scales for final prediction.
Efficient sliding window by converting fully-connected layers into convolutions.
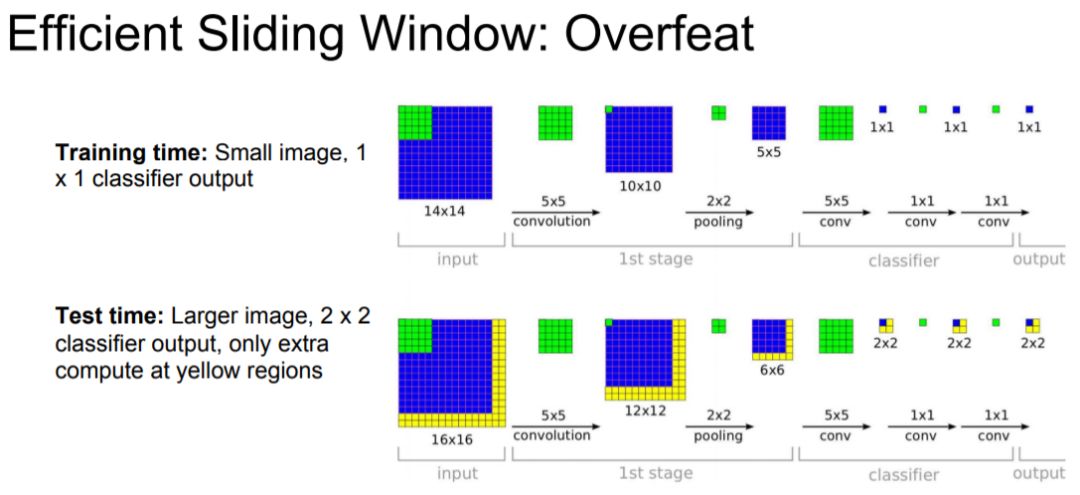
3 目标检测 Object Detection
Object detection is the process of finding instances of real-world objects such as faces, bicycles, and buildings in images or videos. Object detection algorithms typically use extracted features and learning algorithms to recognize instances of an object category. It is commonly used in applications such as image retrieval, security, surveillance, and automated vehicle parking systems.4

3.1 Detection in ImageNet
The definition of detection in ImageNet is:
For each image, algorithms will produce a set of annotations of class labels , confidence scores and bounding boxes . This set is expected to contain each instance of each of the 200 object categories. Objects which were not annotated will be penalized, as will be duplicate detections (two annotations for the same object instance). The winner of the detection challenge will be the team which achieves first place accuracy on the most object categories.
3.2 Typical solutions & models
See more on CS231n(17Spring): lecture 115 and Object Localization and Detection6.
4 分割 Segmentation
There are two kinds of segmentation tasks in CV: Semantic Segmentation & Instance Segmentation. The difference between them is on Instance Segmentation 比 Semantic Segmentation 难很多吗?.
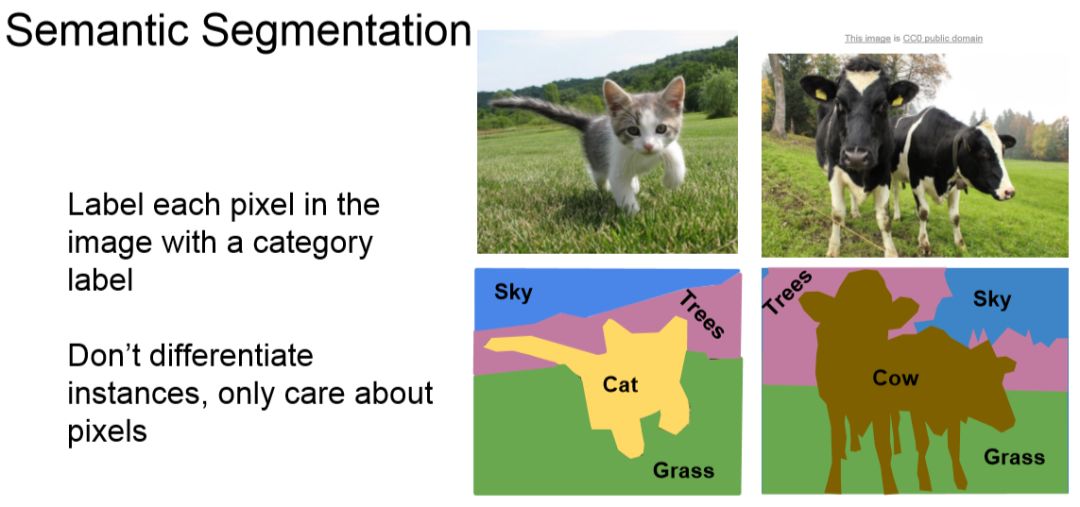
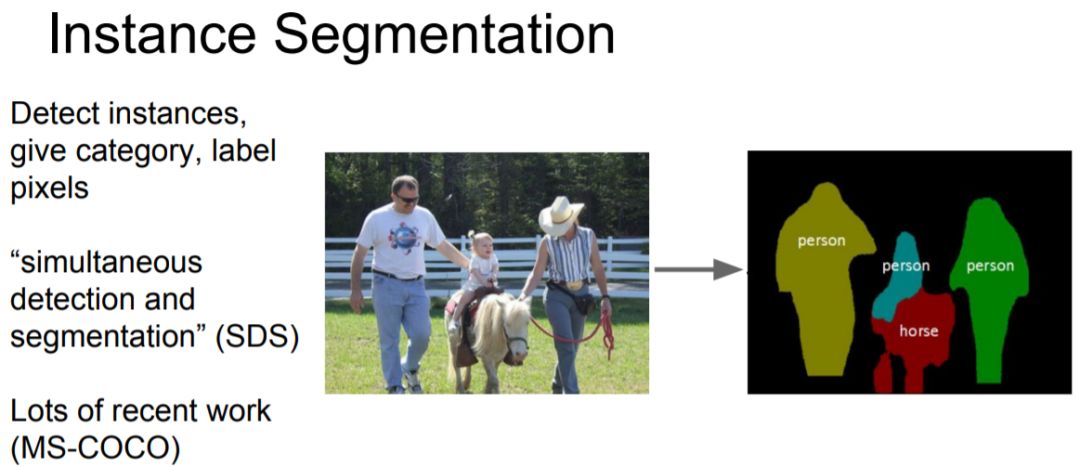
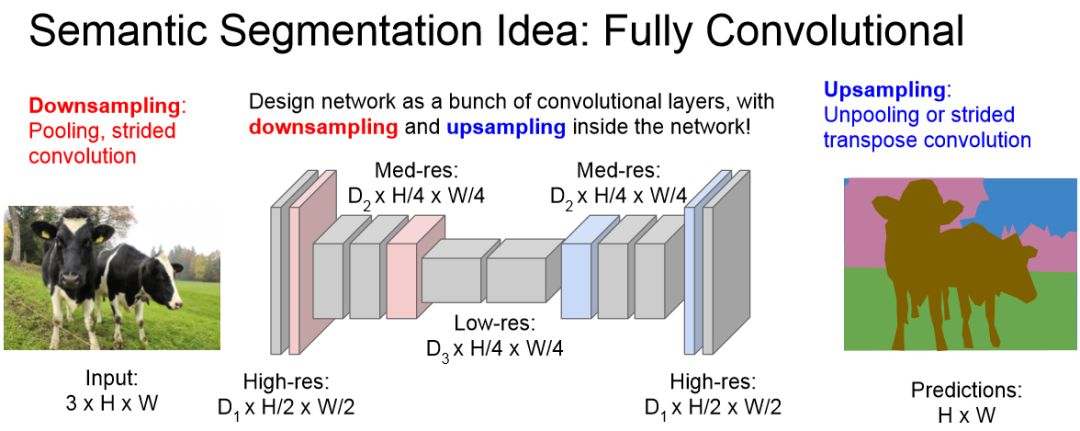
4.1 Typical solutions & models
See more details on Image Segmentation7, Semantic Segmentation8, and really-awesome-semantic-segmentation9.
References
CS231n: Convolutional Neural Networks for Visual Recognition
Quora: What is the difference between object detection and localization
CS231n(16Winter): lecture 8
MathWorks: Object detection in computer vision
CS231n(17Spring): lecture 11
Object Localization and Detection
Image Segmentation
Semantic Segmentation
really awesome semantic segmentation
原文:Luozm's Blog: https://luozm.github.io/cv-tasks
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



