【新加坡国立大学张戎】深度学习与强化学习(附slide下载)
点击上方“专知”关注获取专业AI知识!

来源:
https://cloud.tencent.com/developer/article/1006637
随着 DeepMind 公司的崛起,深度学习和强化学习已经成为了人工智能领域的热门研究方向。除了众所周知的 AlphaGo 之外,DeepMind 之前已经使用深度学习与强化学习的算法构造了能够自动玩 Atari 游戏的 AI,并且在即时战略游戏 StarCraft II 的游戏 AI 构建上做出了自己的贡献。虽然目前还没有成功地使用 AI 来战胜 StarCraft II 的顶尖职业玩家,但是 AI 却能够带给大家无穷的想象力和期待。
本篇 PPT 将会从强化学习的一些简单概念开始,逐步介绍值函数与动作值函数,以及 Q-Learning 算法。然后介绍深度学习中卷积神经网络的大致结构框架。最后将会介绍卷积神经网络是如何和强化学习有效地结合在一起,来实现一些简单的游戏 AI。
之前也写过一份PPT《当强化学习遇见泛函分析》,两份 PPT 有一些重复的地方,读者选择一些看即可。之前文章从强化学习的定义出发,一步一步地给读者介绍强化学习的简单概念和基本性质,并且会介绍经典的 Q-Learning 算法。文章的最后一节会介绍泛函分析的一些基本概念,并且使用泛函分析的经典定理 Banach Fixed Point Theorem 来证明强化学习中 Value Iteration 等算法的收敛性。
末尾附slide下载。


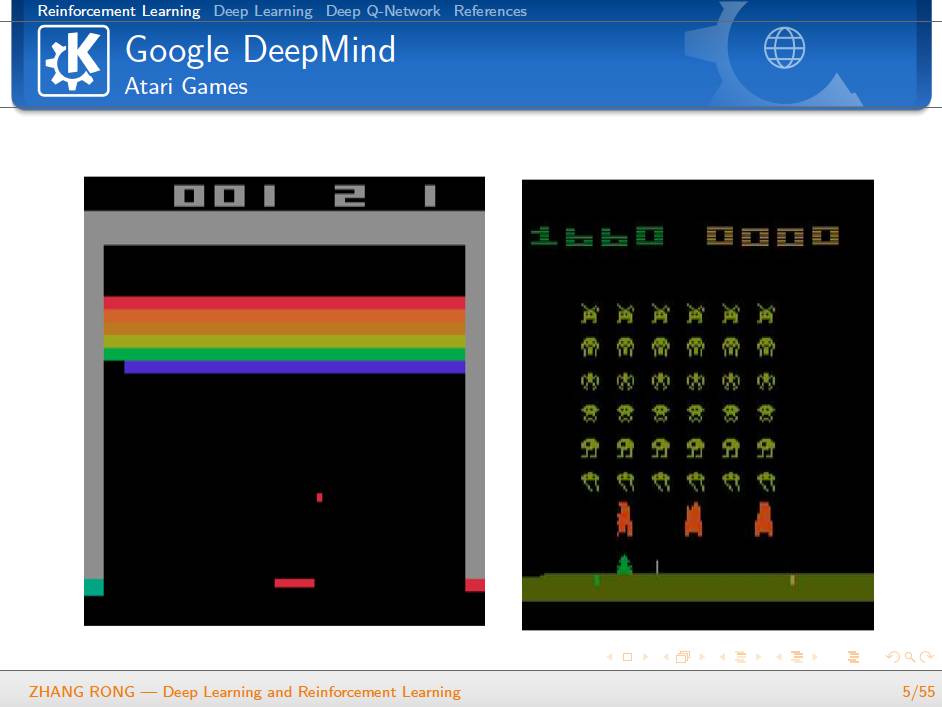
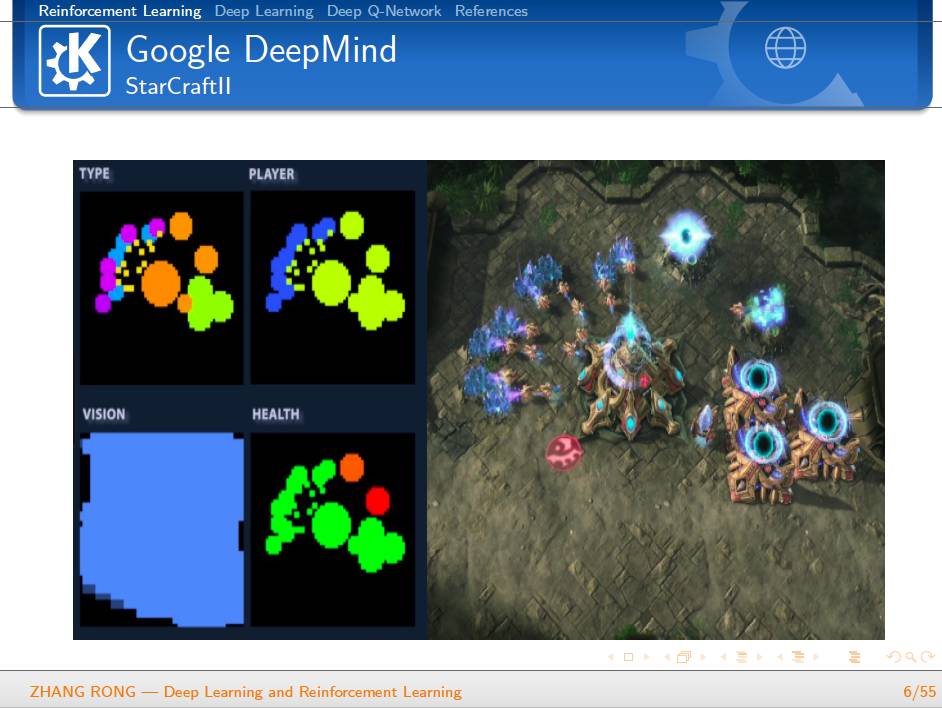
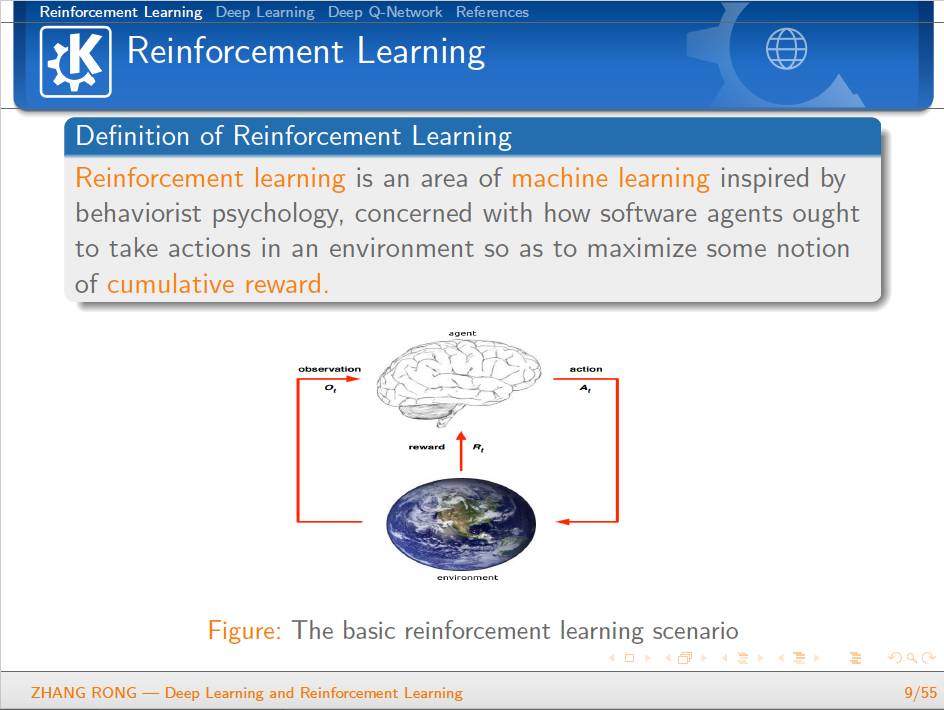
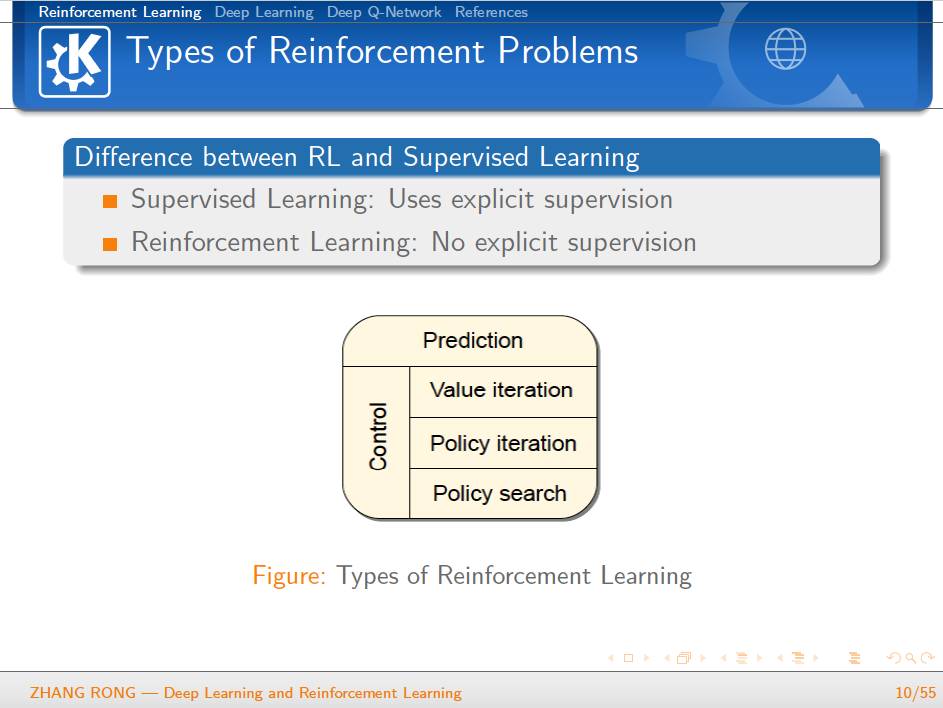
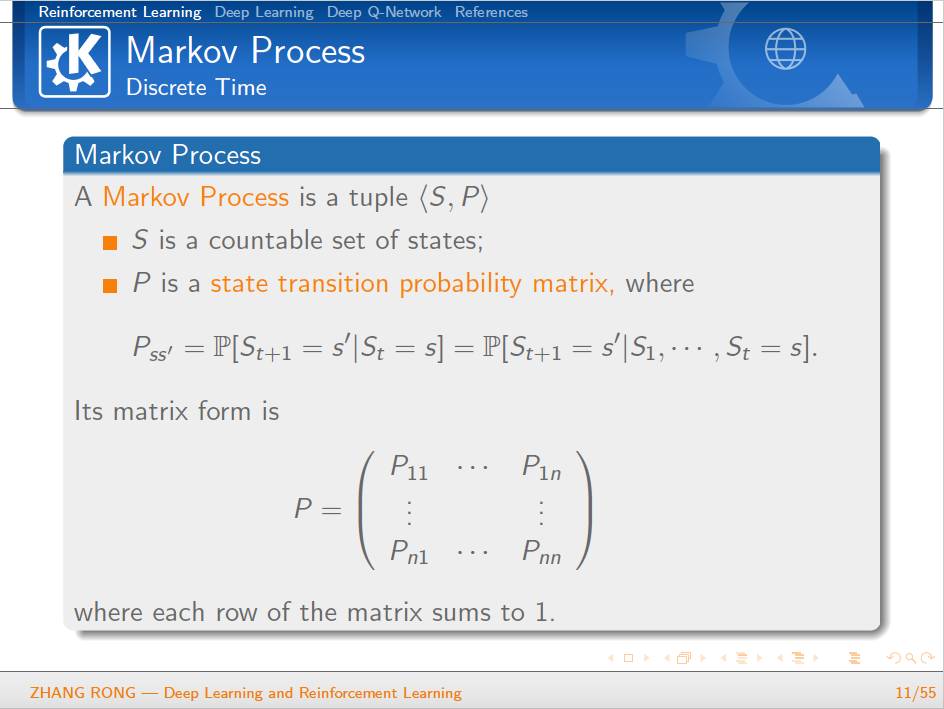
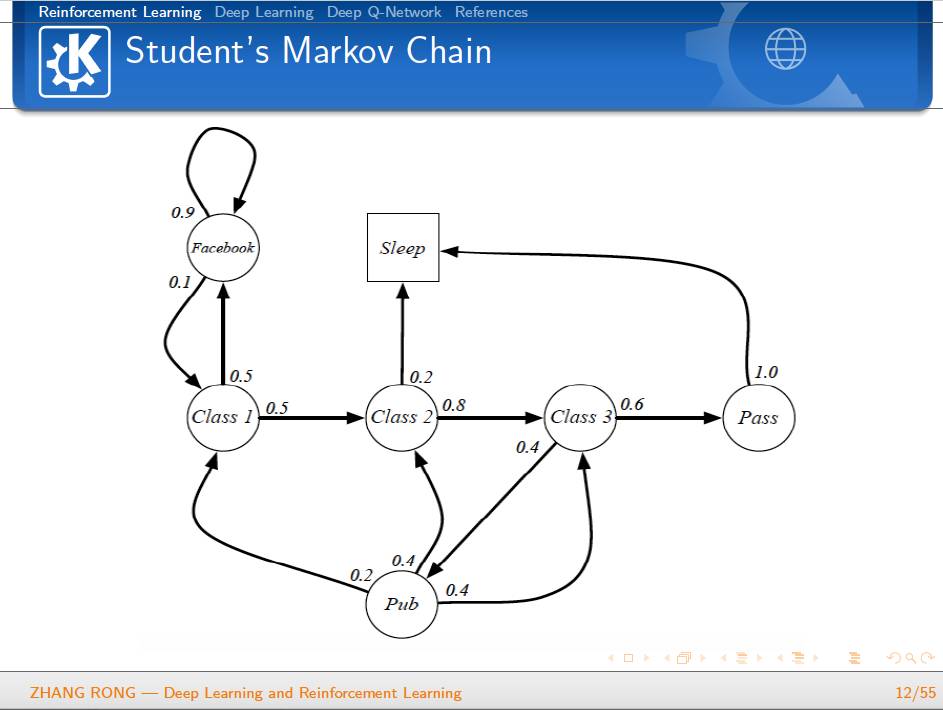
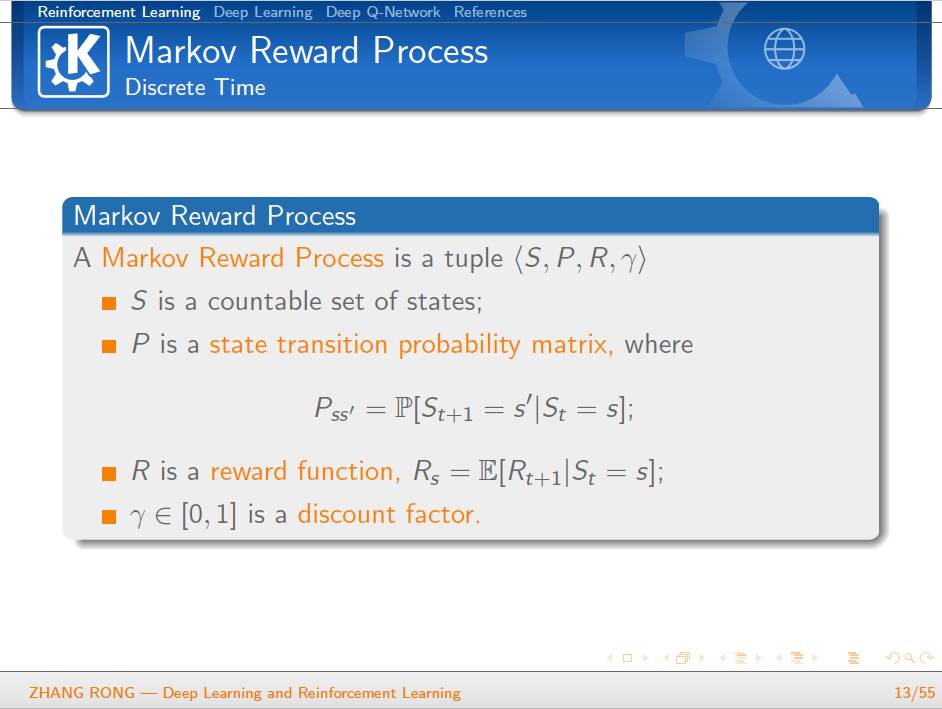
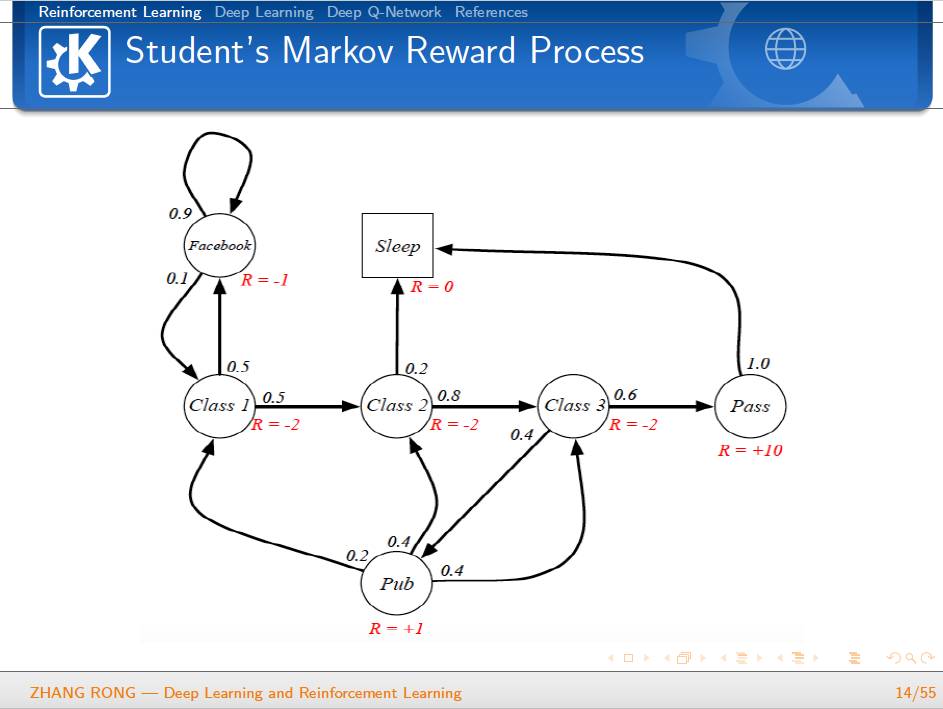
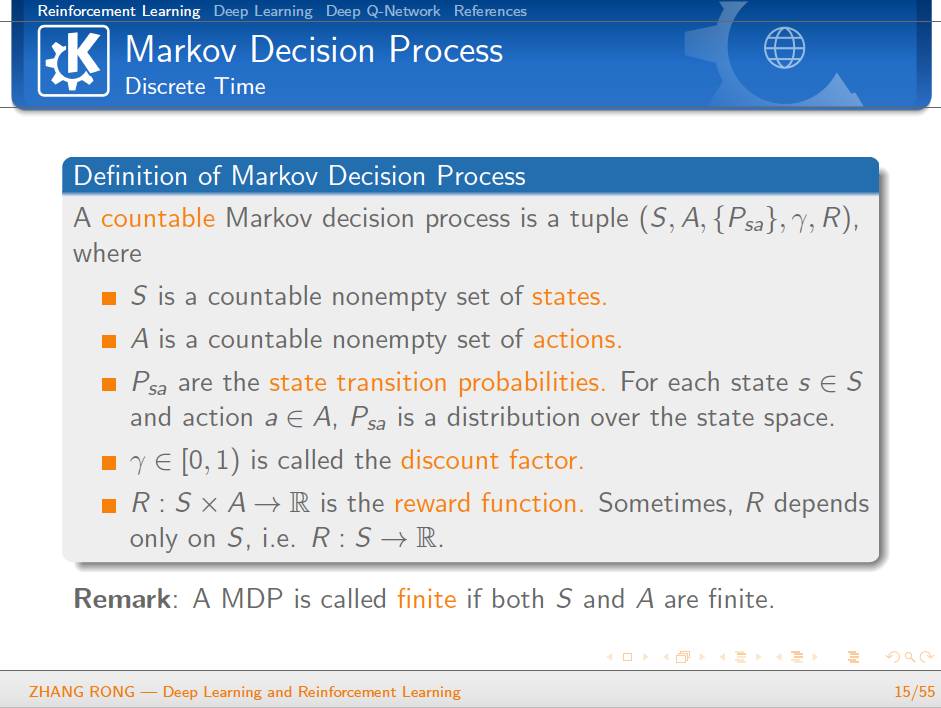
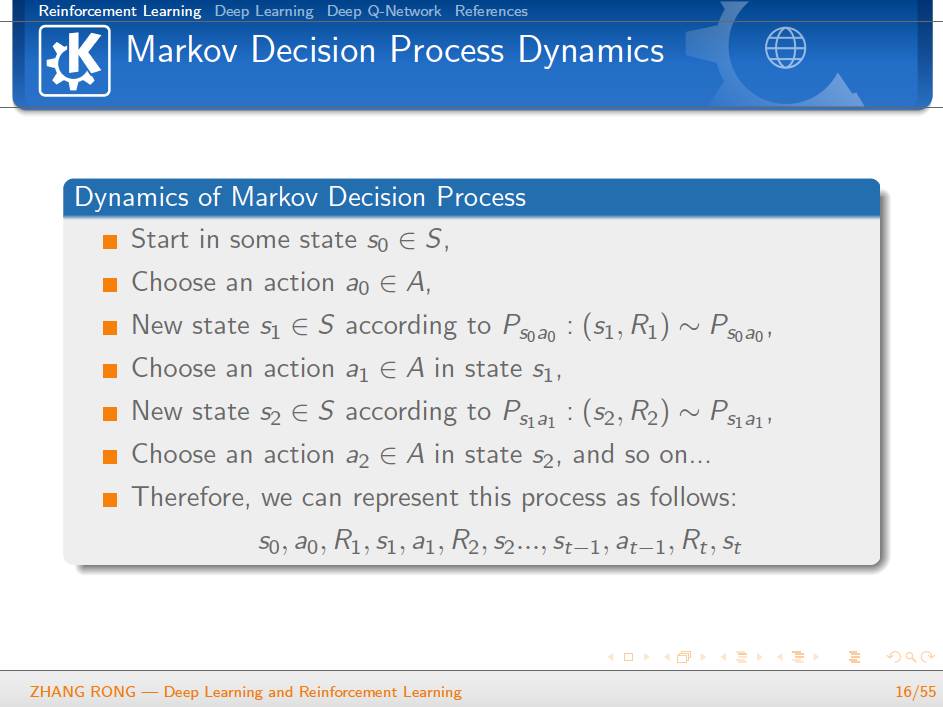
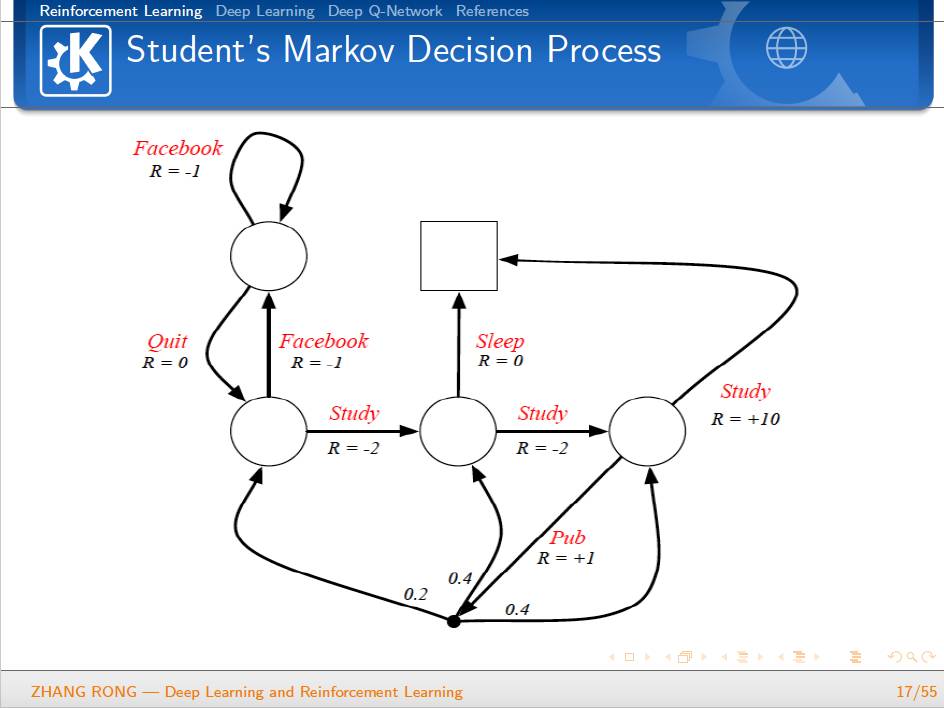




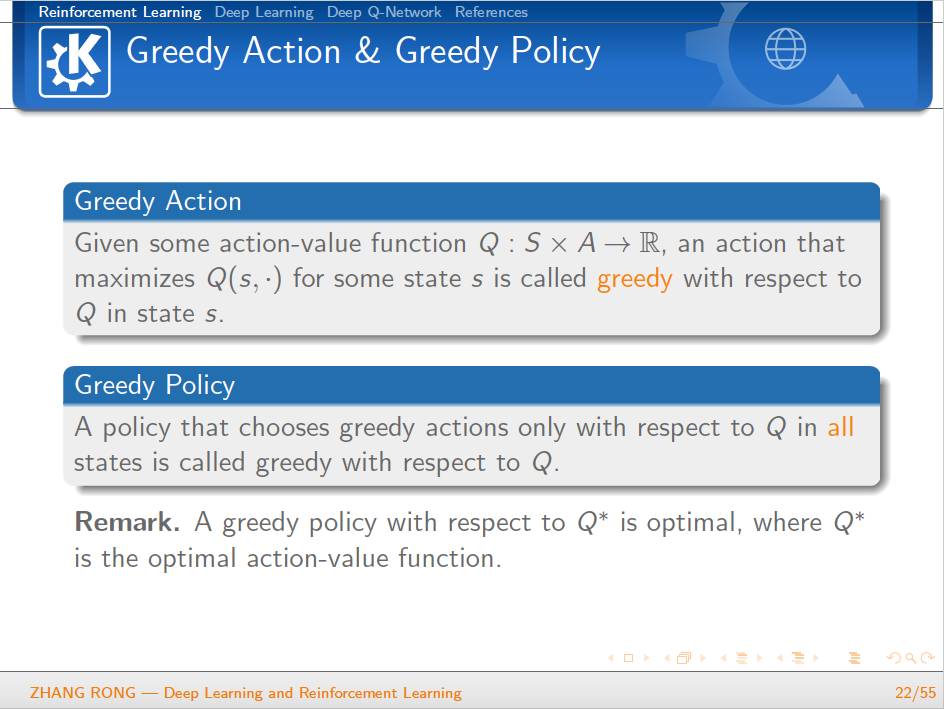







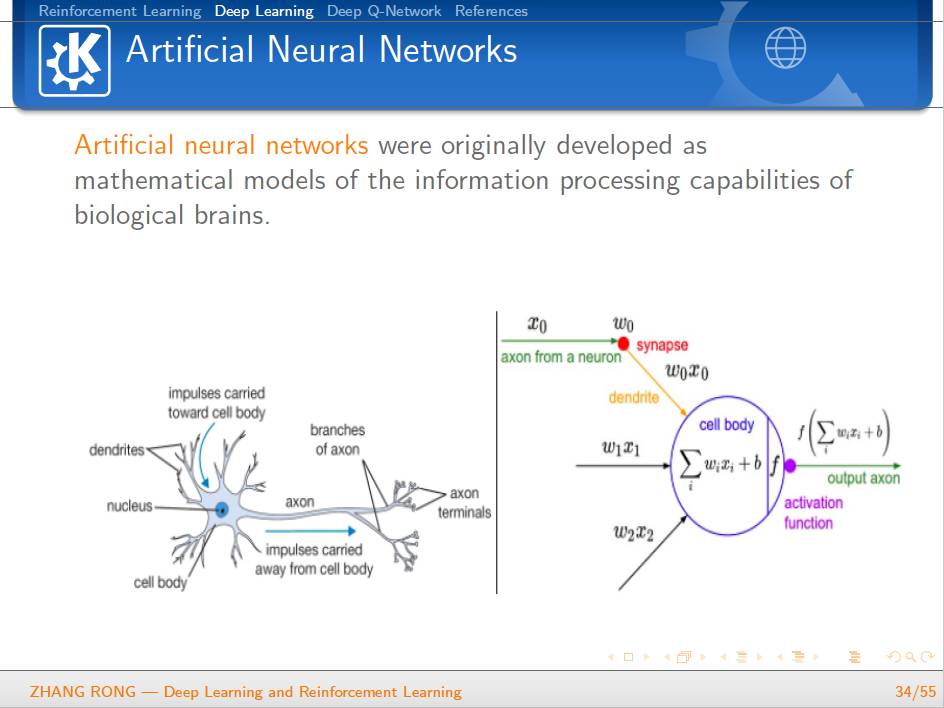
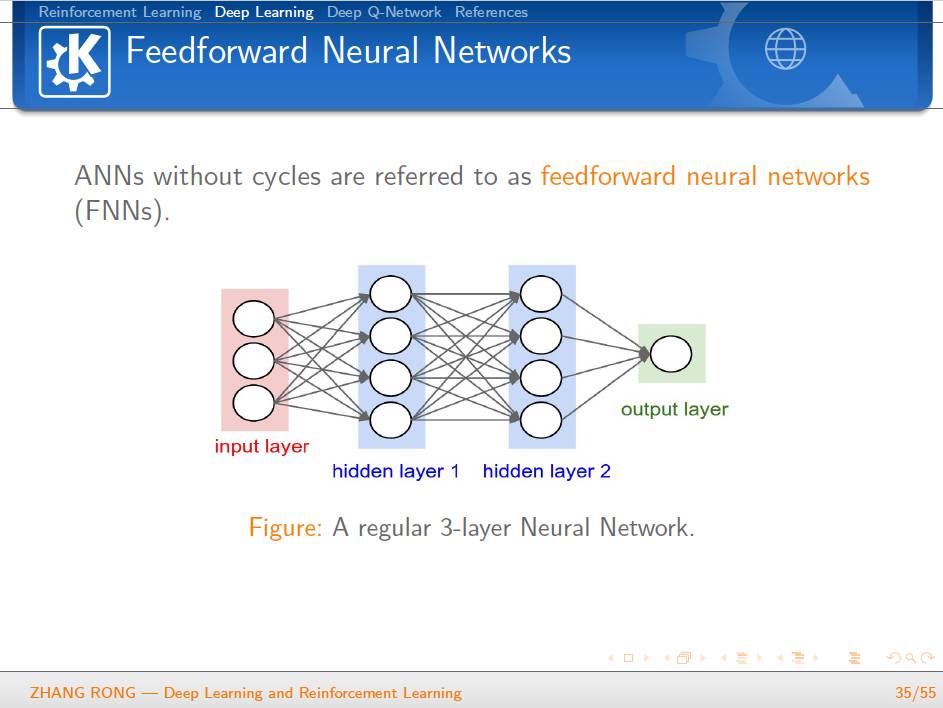


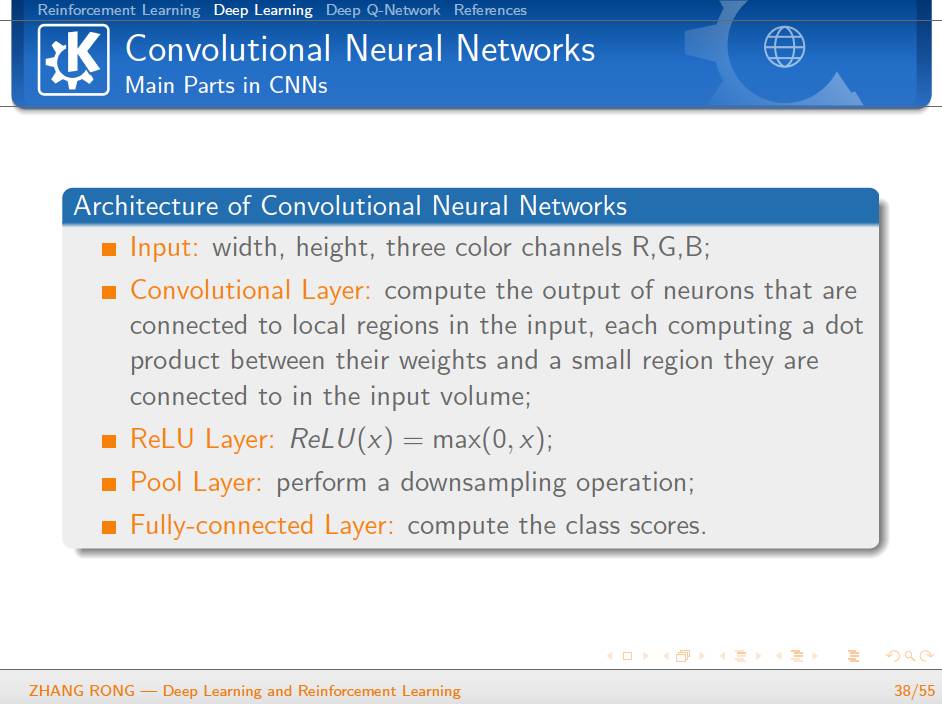
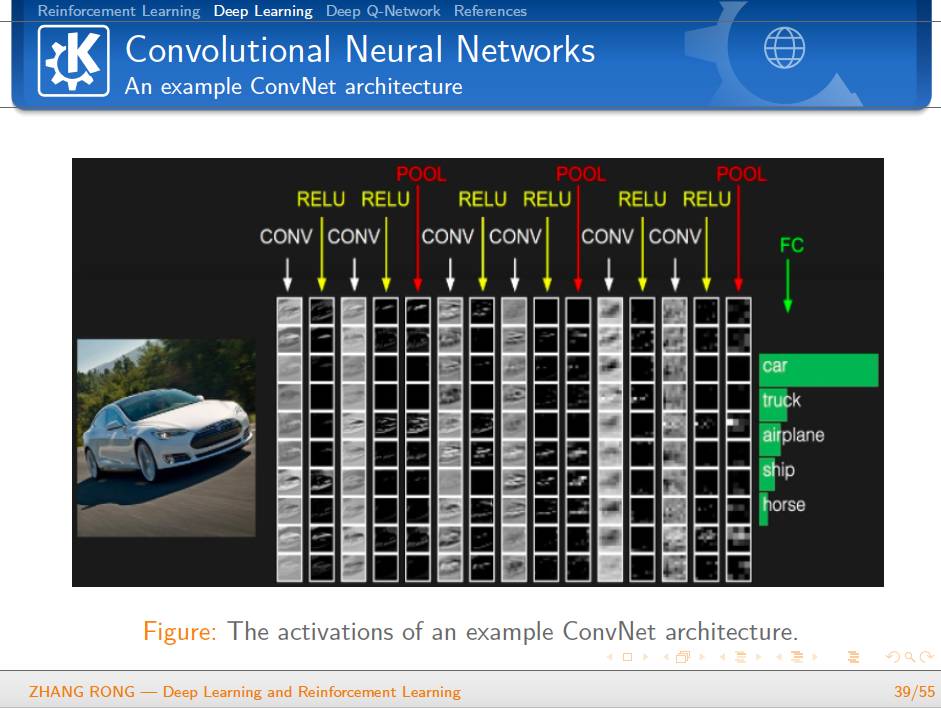



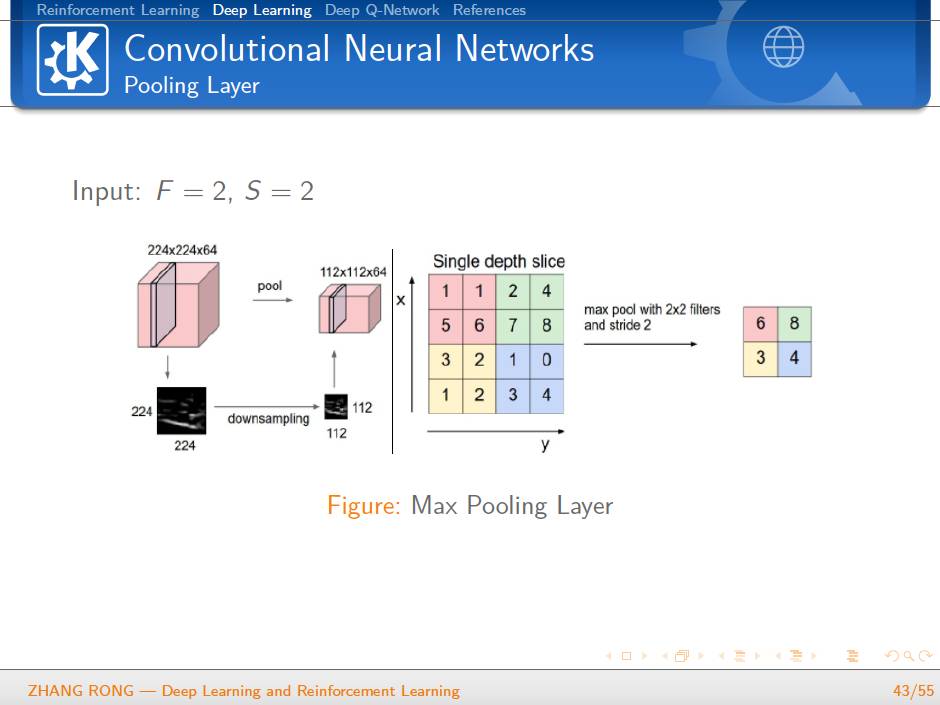

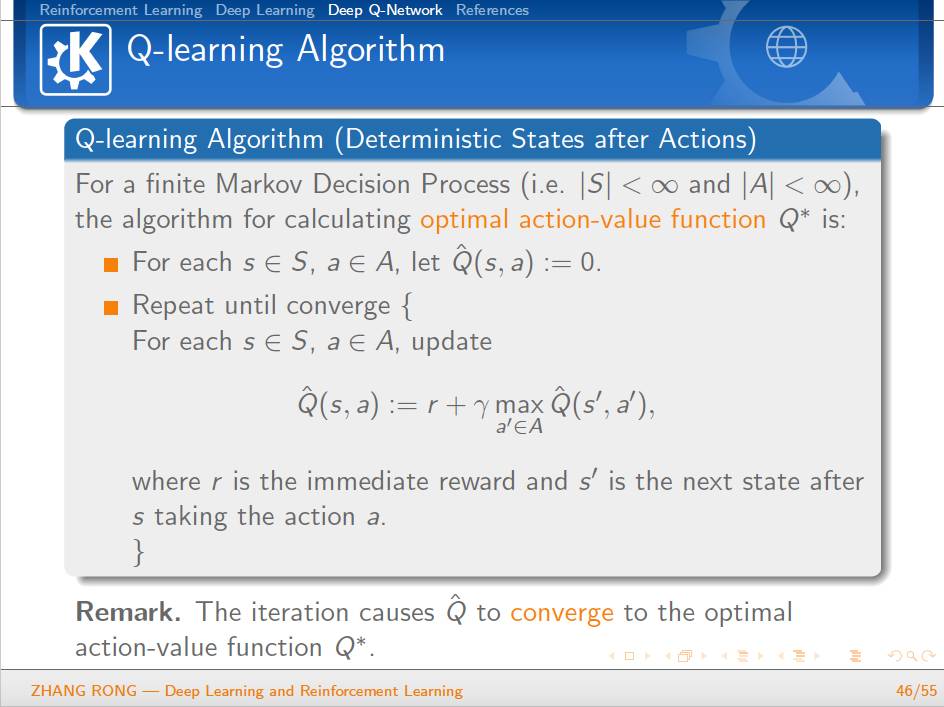

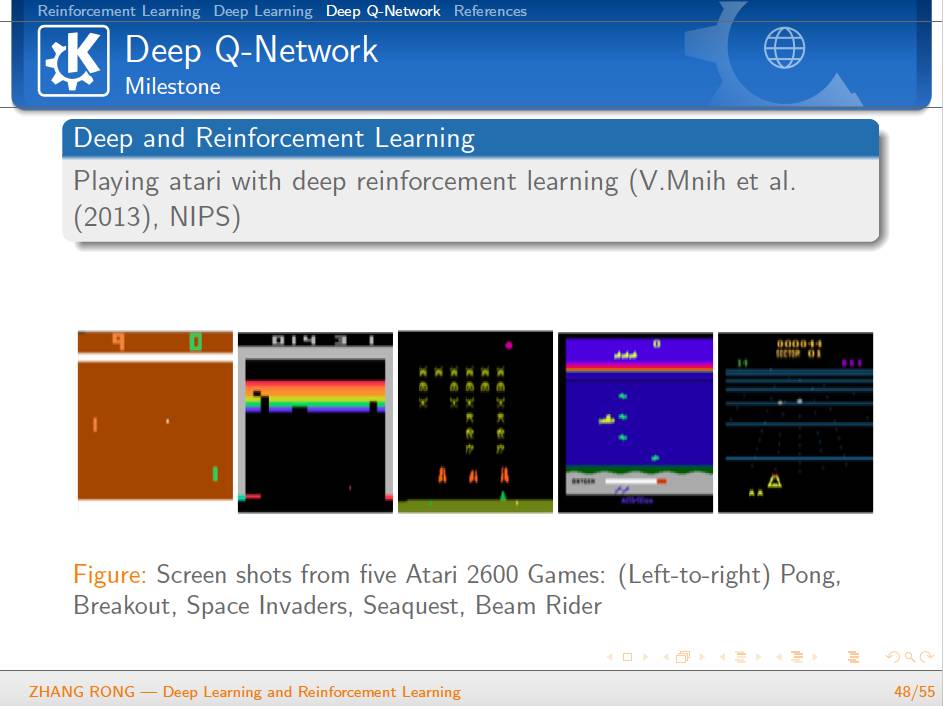
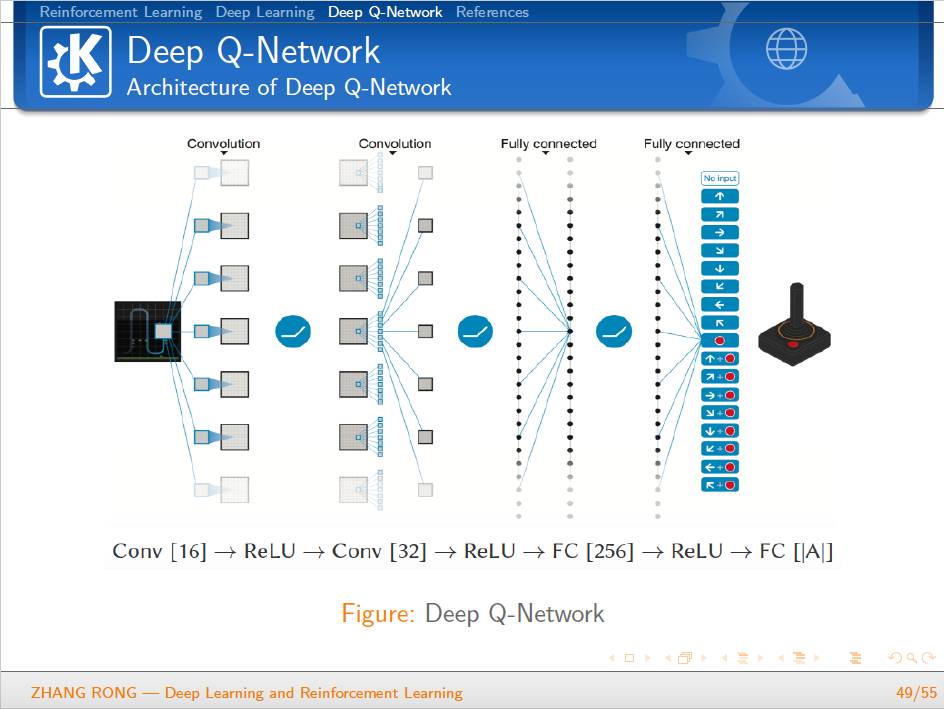

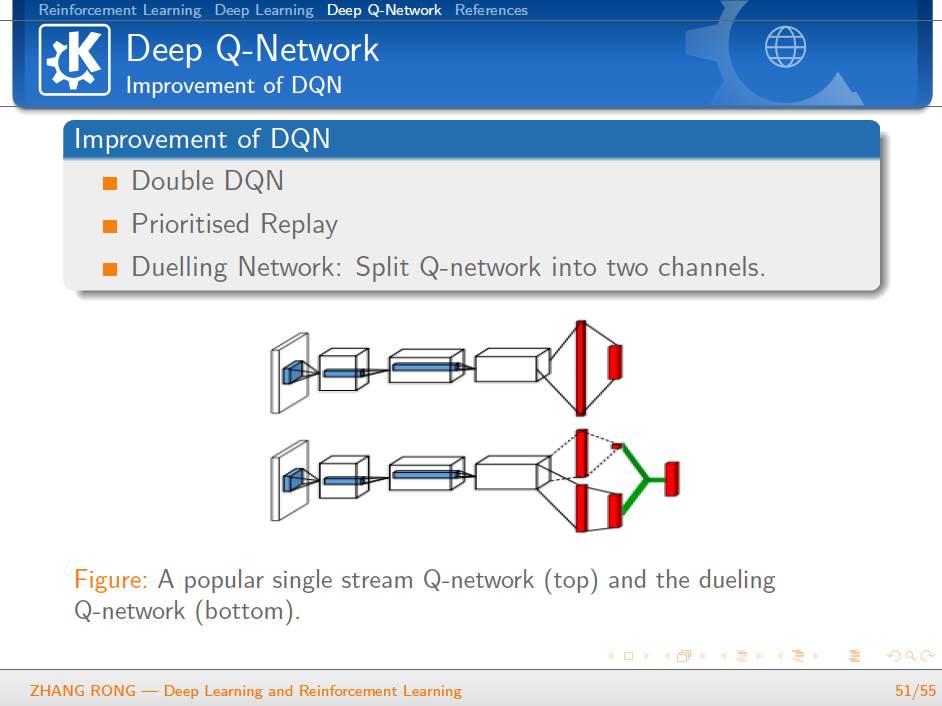
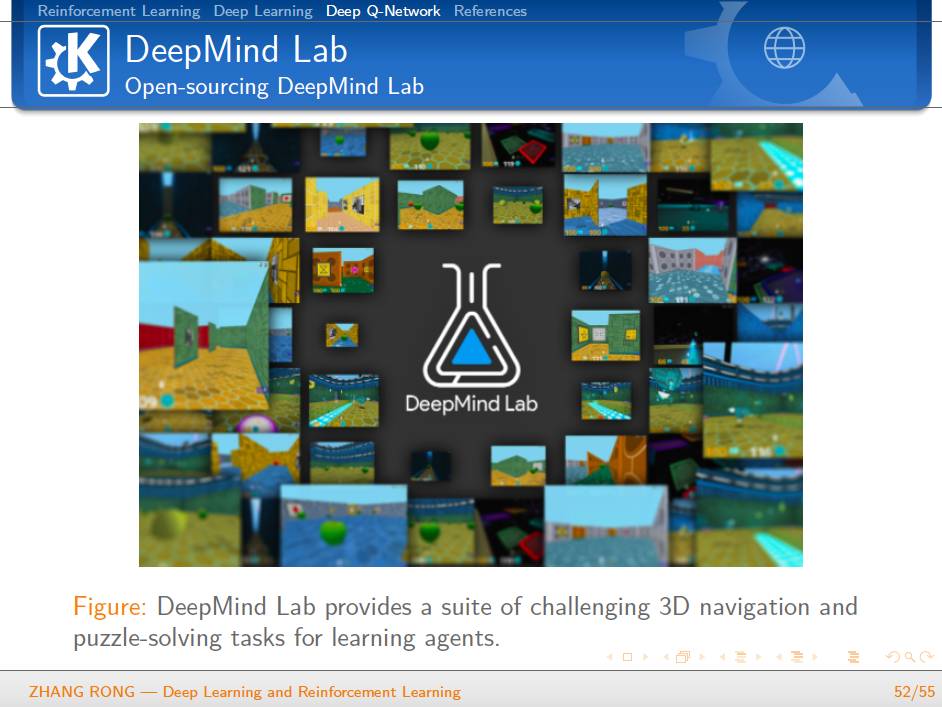
▌特别提示-深度学习与强化学习slide下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“TDLRL” 就可以获取报告pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请下方扫一扫专知小助手微信(Rancho_Fang),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~


点击“阅读原文”,使用专知!
展开全文



