【专知-PyTorch手把手深度学习教程04】GAN快速理解与PyTorch实现: 图文+代码
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问www.zhuanzhi.ai, 手机端访问www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。值国庆佳节,专知特别推出独家特刊-来自中科院自动化所专知小组博士生huaiwen和Jin创作的-PyTorch教程学习系列, 今日带来第四篇-< 快速理解系列(三): 图文+代码, 让你快速理解GAN >
< 快速理解系列(三): 图文+代码, 让你快速理解GAN >
< 快速理解系列(四): 图文+代码, 让你快速理解Dropout >
< NLP系列(一) 用Pytorch 实现 Word Embedding >
< NLP系列(二) 基于字符级RNN的姓名分类 >
< NLP系列(三) 基于字符级RNN的姓名生成 >
生成对抗网络 GAN
生成模型通过训练大量数据, 学习自身模型, 最后通过自身模型产生逼近真实分布的模拟分布. 用这个宝贵的”分布”生成新的数据. 因此, 判别模型的目标是得到关于 y 的分布 P(y|X), 而生成模型的侧重是得到关于X分布 P(y, X) 或 P(x|y)P(y). 即, 判别模型的目标是给定一张图片, 请告诉我这是”长颈鹿”还是”斑马”, 而, 生成模型的目标是告诉你词语: “长颈鹿”, 请生成一张画有”长颈鹿”的图片吧~ 下面这张图片来自slideshare 可以说明问题:

来自: http://www.slideshare.net/shaochuan/spatially-coherent-latent-topic-model-for-concurrent-object
所以, 生成模型可以从大量数据中生成你从未见过的, 但是符合条件的样本.
难怪, 我们可以调教神经网络, 让他的画风和梵高一样. 最后输入一张图片, 它会输出模拟梵高画风的这张图片的油画.
言归正传, 为啥对抗网络在生成模型中受到追捧 ? 生成对抗网络最近为啥这么火 , 到底好在哪里?
那就必须谈到生成对抗网络和一般生成模型的区别了.
一般的生成模型, 必须先初始化一个“假设分布”,即后验分布, 通过各种抽样方法抽样这个后验分布,就能知道这个分布与真实分布之间究竟有多大差异。这里的差异就要通过构造损失函数(loss function)来估算。知道了这个差异后,就能不断调优一开始的“假设分布”,不断逼近真实分布。限制玻尔兹曼机(RBM)就是这种生成模型的一种.
正如”对抗样本与生成式对抗网络“一文所说的: 传统神经网络需要一个人类科学家精心打造的损失函数。但是,对于生成模型这样复杂的过程来说,构建一个好的损失函数绝非易事。这就是对抗网络的闪光之处。对抗网络可以学习自己的损失函数——自己那套复杂的对错规则——无须精心设计和建构一个损失函数:
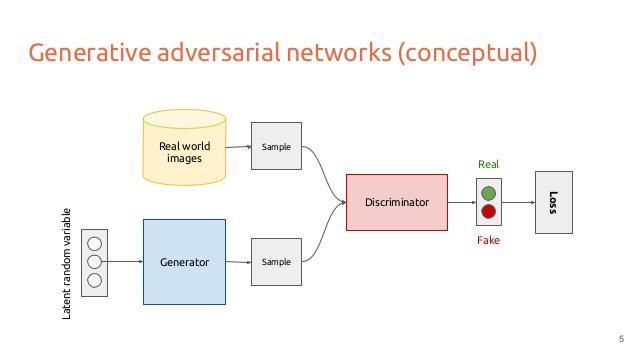
来自:http://www.slideshare.net/xavigiro/deep-learning-for-computer-vision-generative-models-and-adversarial-training-upc-2016
生成对抗网络同时训练两个模型, 叫做生成器(Generator 图中蓝色框)和判断器(Discriminator 图中红色框). 生成器竭尽全力模仿真实分布生成数据; 判断器竭尽全力区分出真实样本和生成器生成的模仿样本. 直到判断器无法区分出真实样本和模仿样本为止.
通过这种方式, 损失函数被蕴含在判断器中了. 我们不再需要思考损失函数应该如何设定, 只要关注判断器输出损失就可以了.
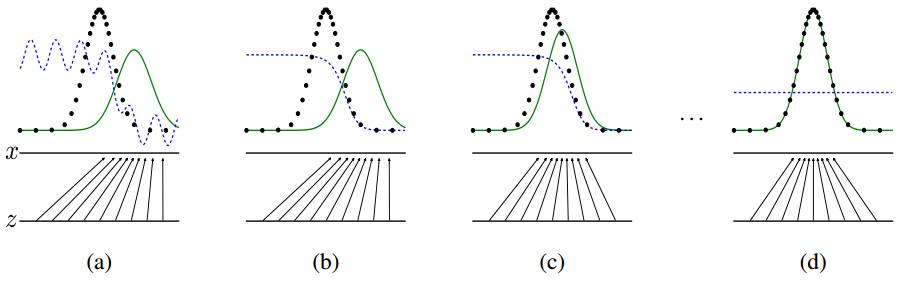
论文”Generative Adversarial Nets”中的训练过程, 生成器和判别器的各自表现
上图是生成对抗网络的训练过程, 可以看到生成器和判别器的各自表现. 其中, 黑色虚线的分布是真实分布, 绿色线的是生成器的分布, 蓝色虚线是判别器的判定分布. 两条水平线代表了两个分布的样本空间的映射.
(a)图中真实分布和生成器的分布比较接近, 但是判定器很容易区分出二者生成的样本. (b)图中判定器又经过训练加强判断, 注意判定分布. (c)图是生成器调整分布, 更好地欺骗判定器. (d)图是不断优化, 直到生成器非常逼近真实分布, 而且判定器无法区分.
下图是Ian J. Goodfellow等人论文中在MNIST和TFD数据上训练出的对抗模型生成的样本:

最右边一列是真实数据集中最接近的邻居样本, 证明生成模型的有效性. 生成右边导数第二列和真实样本非常接近, 但是确是对抗网络随机生成的图片. 可见, 对抗网络对于随机生成一些图片干扰很在行, 这些干扰并不影响人造样本和真实样本的相似性.
下面我们看看如何用Pytorch实现GAN生成MNIST:
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
from torch.autograd import Variable
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5))])
mnist = datasets.MNIST(root='./mnist/',
train=True,
transform=transform,
download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist,
batch_size=100,
shuffle=True)
# 判别器
D = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid())
# 生成器
G = nn.Sequential(
nn.Linear(64, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 784),
nn.Tanh())
if torch.cuda.is_available():
D.cuda()
G.cuda()
loss_func = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
for epoch in range(200):
for i, (images, _) in enumerate(data_loader):
batch_size = images.size(0)
# reshape 成 (batch_size, 28*28)
images = get_variable(images.view(batch_size, -1))
real_labels = get_variable(torch.ones(batch_size)) # 真实数据 label 为1
fake_labels = get_variable(torch.zeros(batch_size)) # 假数据 label 为0
# ============= Train the discriminator =============#
# 判别真实数据,计算损失
outputs = D(images)
d_loss_real = loss_func(outputs, real_labels)
real_score = outputs
# 生成假数据
z = get_variable(torch.randn(batch_size, 64))
fake_images = G(z)
# 判别生成的数据,计算损失
outputs = D(fake_images)
d_loss_fake = loss_func(outputs, fake_labels)
fake_score = outputs
# 优化判别器
d_loss = d_loss_real + d_loss_fake
D.zero_grad()
d_loss.backward()
d_optimizer.step()
# =============== Train the generator ===============#
# 生成假数据
z = get_variable(torch.randn(batch_size, 64))
fake_images = G(z)
# 用判别器计算损失
outputs = D(fake_images)
g_loss = loss_func(outputs, real_labels)
# 优化生成器
D.zero_grad()
G.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 300 == 0:
print('Epoch [%d/%d], Step[%d/%d], d_loss: %.4f, '
'g_loss: %.4f, 真实数据平均得分: %.2f, 假数据平均得分: %.2f'
% (epoch, 200, i + 1, 600, d_loss.data[0], g_loss.data[0],
real_score.data.mean(), fake_score.data.mean()))
# 保存一下真实数据
if (epoch + 1) == 1:
images = images.view(images.size(0), 1, 28, 28)
save_image(denorm(images.data), './mnist/real_images.png')
# 保存生成数据
fake_images = fake_images.view(fake_images.size(0), 1, 28, 28)
save_image(denorm(fake_images.data), './mnist/fake_images-%d.png' % (epoch + 1))
# 保存模型参数
torch.save(G.state_dict(), './generator.pkl')
torch.save(D.state_dict(), './discriminator.pkl')Reference:
#9-生成对抗网络101-终极入门-通俗解析
http://nooverfit.com/wp/9-生成对抗网络101-终极入门-通俗解析
作者: david 9
明天继续推出:专知PyTorch深度学习教程系列-< 快速理解系列(四): 图文+代码, 让你快速理解Dropout >,敬请关注。
完整系列搜索查看,请PC登录
www.zhuanzhi.ai, 搜索“PyTorch”即可得。
对PyTorch教程感兴趣的同学,欢迎进入我们的专知PyTorch主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入:

了解使用专知-获取更多AI知识!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“ 阅读原文 ”,使用 专知!
展开全文



