吴恩达高徒语音专家Awni Hannun:序列模型Attention Model中的问题与挑战
【导读】注意力模型(Attention Model)被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。 本文以序列模型训练为例,深入浅出地介绍了注意力机制在应用中的两个重要问题:一是解决训练和生成时输入数据分布不一致;二是训练效率,并给出了相应的解决方法。作者是Awni Hannun,斯坦福大学在读博士,师从吴恩达,曾经休学两年跟随导师吴恩达在百度硅谷实验室工作,是百度Deep Speech语音识别项目主要参与者。专知内容组整理编辑。
Awni Hannun 个人主页:http://stanford.edu/~awni/
Training Sequence Models with Attention
根据注意力训练序列模型
▌简介
本文介绍一些关于训练序列到序列模型(sequence-to-sequence models)的实用技巧,如果你对训练其他类型的深度神经网络有一定的经验,那么本文的介绍的实用技巧几乎也都能适用。这篇文章介绍的是一些你可能不知道的小技巧,即使你有其他模型训练的经验,也可能使你受益匪浅。

上图是使用注意力的序列到序列模型的结构。左边是编码器网络,右边是解码器网络,用以预测输出序列。编码器的隐藏状态在每一个时间步骤上都会参与到解码器中。
学习条件
首先我们要知道的是,模型是否能有效工作。因为,有时这并不能非常明显的看出来。使用序列到序列模型时候,我们通常是对输出的条件概率进行优化:
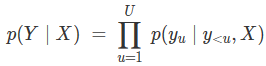
其中,输入序列是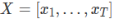
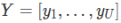
序列到序列模型(sequence-to-sequence model)的一个缺陷之处在于,它永远不会学习对输入序列X的条件概率。换句话说,这种模型不能学习如何以一种有用的方式来处理编码输入。其实,如果模型可以这样处理的话,相当于是在优化下式:
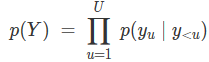
这实际上只是利用输出序列的一种语言模型。在这种情况下,即使模型在输入的X上没有学习到条件,也可以进行合理的学习。所以,如果这个模型真的有效,那这种有效也并不是明显的。
注意力可视化:
上述分析给我们带来了一个提示。可以将注意力可视化,来判断这个模型是否已经学会了从输入来学习条件。通常情况下,如果注意力是合理的,就可以很明显的看出来了。

上图是对同一个语音识别任务的两个不同模型注意力的例子。上图:表示在输入和输出之间有一个合理的“对齐”。下图:表示尽管训练损失随时间在慢慢减少(损失没有偏差),但模型没能学会如何参与到输入中。
推理的差距
序列到序列模型(Sequence-to-sequence models)是通过教师强制(teacher forcing)训练的。它不使用预测的输出作为下一步的输入,而是使用ground truth输出。如果没有教师强制(teacher forcing)这些模型,它们的收敛速度要慢得多。
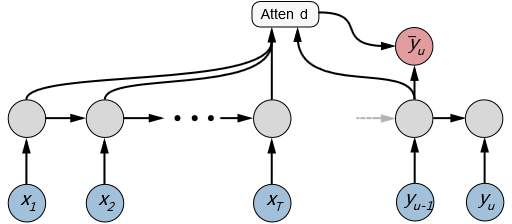
上图表示使用教师强制(teacher forcing)训练模型。输入到解码器的是ground-truth输出,而不是上次迭代的预测输出。
教师强制(teacher forcing)在训练模型和使用它进行推断之间产生不匹配问题。在训练中,我们并不是在推理过程中,而是知道先前的事实(ground-truth)。正因为如此,在使用教师强迫(teacher forcing)的评估错误率与根据真实数据推理的错误率之间存在很大的差距。
定期采样Scheduled Sampling :
在训练和推断之间构建桥梁的一种有用的技术是定期采样。这种思路是简单的——通过选择之前预测的输出,而不是使用概率p的ground truth输出。针对这个问题的概率进行调整。概率p的一般范围在10%和40%之间。
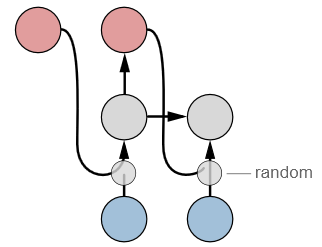
上图表示,预采样随机从预测的输出或ground-truth输出进行选择,作为下一步的输入。
简单地说,教师强制(teacher forcing)在训练时间和测试时间之间的性能的差距,仍然是一个活跃的研究领域。预采样才实验中非常有效,然而它也有一些不好的地方,目前也提出了替代的方法。
根据推断率进行调整:
当正确推断出输出结果的时候,坑你在教师强制训练损失(teacher forcing)和错误率之间会存在很大的差距。这两个指标之间的相关性可能并不完善。因此,我建议根据推断输出错误率来进行模型的选择和超参数的调优。如果你保存的是在训练过程中表现最好的模型,那么就用这个错误率作为性能评价指标。
例如,在语音识别中,直接使用预测输出来计算单词(或字符)错误率。在机器翻译、文本摘要和其他有许多能正确输出句子的任务中,使用BLEU 或 ROUGE 分数。
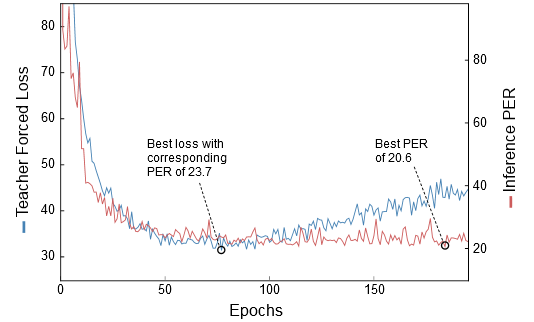
上图表示,蓝色曲线是教师强制的交叉熵损失。红线是推断的输出的字符错误率(phoneme error rate, PER)。最好的PER比最好的教师强制交叉熵损失的PER还要好得多。但是,在这些曲线上变化很大,所以对这个例子真实效果有待考证。即使如此,由于这两条曲线确实看起来完全不同,这说明在某一点之后度量指标之间的相关性不是很好。
当两个指标中存在更多的差异时,这个技巧可能变得很重要。然而,这可能带来很多不同。例如,在上面的语音识别任务中,我们看到,使用推断错误率来代替教师强制损失的模型,获得了13%的相对的改进。如果你想重现一个baseline,这可能是其中一个关键的区别。
▌Training Sequence Models with Attention
Efficiency(效率)
使用这些模型的一个缺点是它们可能相当缓慢。注意力机制的计算量取决于输入和输出序列长度的乘积,例如,O(TU)。 如果输入序列长度加倍,输出序列长度也加倍,则计算量将增加四倍。
按长度存储Bucket:当优化一个批处理(minibatch)大小大于1的模型的时候,确保将实例按长度存储。对于每个批次,我们希望所有的输入都是相同的长度,输出也都是相同的长度。这通常是不可能的,但是我们至少可以尝试最小化任意给定的批次中最大长度的错配。
一个非常有效地启发式方法是根据输入长度来生成buckets。例如,长度为1到5的所有输入都进入第一个bucket。长度为6到10的输入进入第二个bucket,以此类推。然后对于每个bucket中的数据,按照输出长度之后跟着输入长度这样的顺序进行排序。
当然,训练集越大,你就越有可能拥有输入和输出大致相同的批处理(minibatch)。
步幅(Striding)和下采样(Subsampling):当模型的输入和输出序列很长时,它们会逐渐停止。 对于长输入序列,一个好的做法是通过二次采样来减少编码的序列长度。这在语音识别中很常见,例如,输入可以有数千个时间步长。在基于文字的机器翻译中,你不会看到这么多,因为输入序列没有那么长。然而,基于字符的模型子采样更为常见。子采样可以通过带步长的卷积和(或)池化操作来实现,或者简单地通过串联连续的隐藏状态来实现。
通常,对输入进行次采样不会降低模型的准确性。尽管在准确度上有轻微的影响,但加速了训练时间,这一点是值得的。当RNN和注意力计算是瓶颈(它们通常是)时,讲输入的子采样因子变为4,可以使模型的训练速度提高4倍。
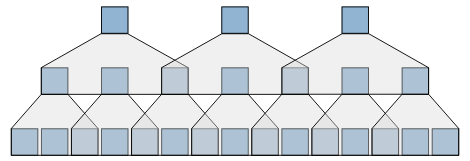
图:编码器中的金字塔结构。这里每一层的步幅或次采样因子是2。输入序列中的时间步数减少了4倍(取决于你将序列填充到每个层的方式)。
That’s All
正如你所看到的,让这些模型正常工作需要正确的工具。以上说到的这些技巧建议并不是全面的,我的目标是精确率(precision)超过召回率(recall)。即便如此,他们也不能一概而论。但是,作为在训练和改进基线序列-序列模型时尝试的一些第一个想法,我强烈推荐所有这些方法。
Acknowledgements
Thanks to Ziang Xie for useful feedback and suggestions.
参考文献:
1. See Bengio et al., 2015
https://arxiv.org/abs/1506.03099
2. See Huszar, 2015 for an explanation why scheduled sampling is improper and a suggested alternative.
https://arxiv.org/abs/1511.05101
3. Lamb et al., 2016 introduce Professor Forcing, an alternative to scheduled sampling.
https://arxiv.org/abs/1610.09038
4. Here’s the code for more details or if you want to reproduce this experiment.
https://github.com/awni/speech/tree/master/examples/timit
5. See Chan et al., 2015 for an example of this in speech recognition.
https://arxiv.org/abs/1508.01211
6. See Xie et al., 2016 for an example of a character-based model for language correction which subsamples in the encoder.
https://arxiv.org/abs/1603.09727
原文链接:
https://awni.github.io/train-sequence-models/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



