基于信息理论的机器学习-中科院自动化所胡包钢研究员教程分享04(附pdf下载)
【导读】专知于11月24日推出胡老师的基于信息理论的机器学习报告系列教程,大家反响热烈,胡老师PPT内容非常翔实精彩,是学习机器学习信息理论不可多得的好教程,今天是胡老师为教程的第四部分也是报告的最后一部分(为第五章和第六章内容)进行详细地注释说明,请大家查看!
▌概述
本次tutorial的目的是,1.介绍信息学习理论与模式识别的基本概念与原理;2.揭示最新的理论研究进展;3.从机器学习与人工智能的研究中启发思索。由于时间有限,本次只是大概介绍一下本次tutorial的内容,后续会详细介绍每一部分。
本次tutorial的目的是,1.介绍信息学习理论与模式识别的基本概念与原理;2.揭示最新的理论研究进展;3.从机器学习与人工智能的研究中启发思索。由于时间有限,本次只是大概介绍一下本次tutorial的内容,后续会详细介绍每一部分。
胡老师的报告内容分为三个部分:
引言(Introduction)
信息理论基础(Basics of Information Theory)
二值信道的理论进展(Theoretical Progress in Binary Channel)
分类评价中的信息度量(Information Measures in Classification Evaluation)
贝叶斯分类器和互信息分类器(Bayesian Classifiers and Mutual-information Classifiers)
总结和讨论(Summary and Discussions)
想了解基于信息理论的机器学习报告系列教程,请阅读专知以前推出的报道:
1. 基于信息理论的机器学习——中科院自动化所胡包钢老师教程分享01(附pdf下载)
2. 基于信息理论的机器学习——中科院自动化所胡包钢老师教程分享02(附pdf下载)
3. 基于信息理论的机器学习——中科院自动化所胡包钢老师教程分享03(附pdf下载)
胡包钢研究员个人主页:
http://www.escience.cn/people/hubaogang/index.html
胡包钢老师简介:
胡包钢老师是机器学习与模式识别领域的知名学者,1993年在加拿大McMaster大学获哲学博士学位。1997年9月回国前在加拿大MemorialUniversity of Newfoundland, C-CORE研究中心担任高级研究工程师。目前为中国科学院自动化研究所研究员。2000-2005年任中法信息、自动化、应用数学联合实验室(LIAMA)中方主任。
▌PPT
第五章:贝叶斯分类器与互信息分类器

在《模式分类》这个经典教课书中,Duda等人认为周绍康(C.K. Chow)是将贝叶斯决策方法应用于模式识别研究中的先驱学者之一。华人学者周绍康分别于1957年与1970年的两篇文章奠定了贝叶斯分类器基础方法以及其中误差率与拒识率之间的理论关系。
在此要顺便指出Chow–Liu Tree (Chow-Liu 树) 中的第一作者就是周绍康先生。他们1968年发表的方法成为贝叶斯网研究中的重要基础知识。华人在已有科学基础知识中的引用比例与其在世界中人口比例严重不符。这也成为激励我们创新知识的动力。
要知道贝叶斯分类器存在实际应用中的问题。这就是假设所有变量分布信息已知,因此可以获得完全正确解。实际应用中这是不可能的先决条件。然而贝叶斯分类器提供了原理性的分类推断基础以及分类误差的理论下界对于指导应用是不可或缺的基础知识。

本章推导贝叶斯二值拒识分类器新的计算公式。其中本人采取了类似于Chow1970年文章与 Duda一书中的假设策略(Hu, 2015)。A1. 二值分类。A2. 全部变量分布信息已知。当目标变量T中包含两个类标时,预测变量中的y3 对应拒识类标。所谓贝叶斯分类器就是寻找y*。该y*是总误差Risk(y)中最小的预测。其中代价矩阵变为2乘3,共6个元素(也可以理解为是自由参数)。
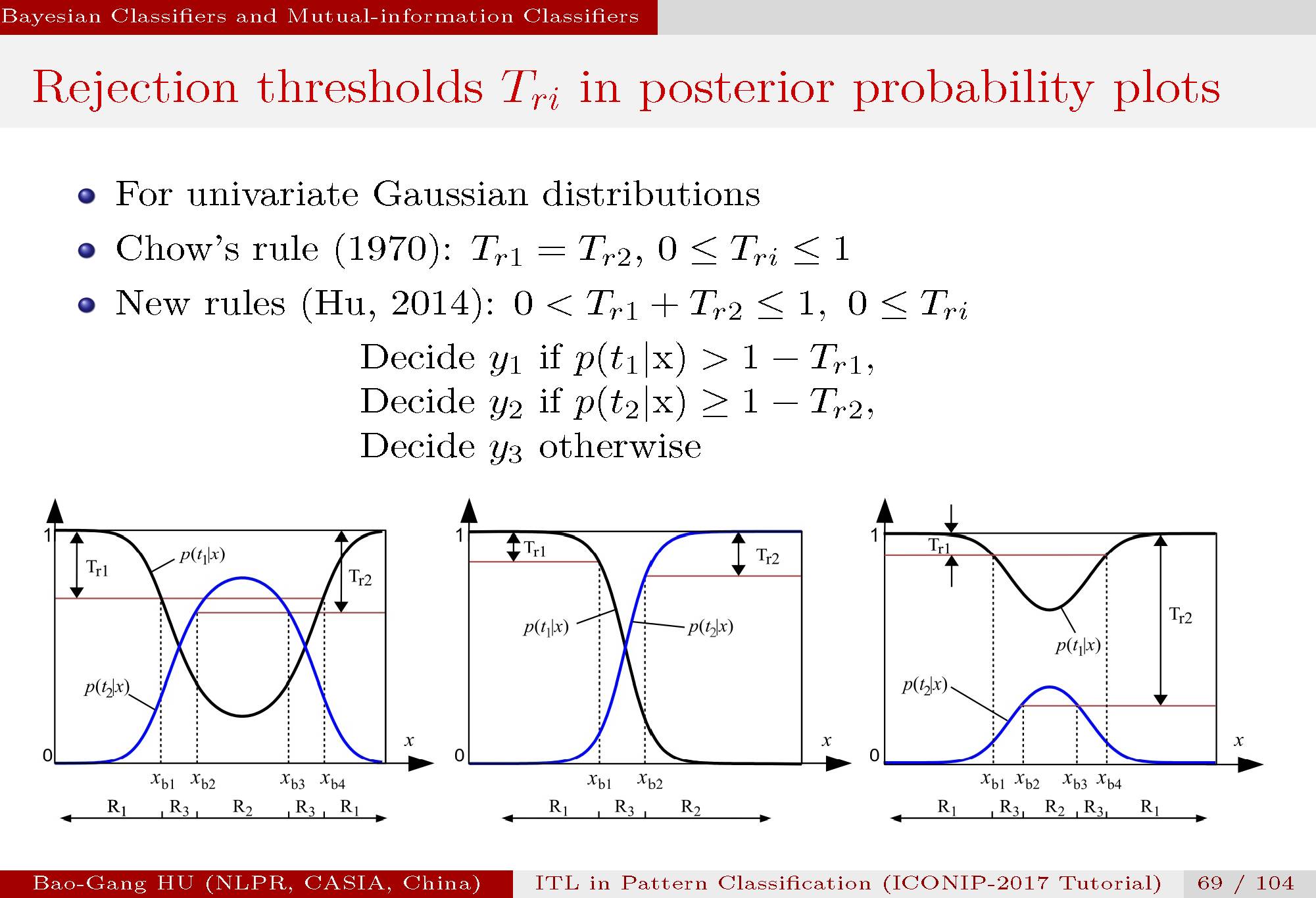
进一步采取了Chow1970年文章与 Duda一书中的假设策略,设定A3为:特征空间X是一维中的高斯分布。该假设是主要是为了能够推导显式的计算表达关系式而又不影响基本结论在推广到高维特征空间X,多值分类,以及其它分布情况下的相关理解。对于两类样本分别为高斯分布,在其后验概率曲线中,我们给出了三种图形情况。特征空间为横坐标中示意出了拒识范围由R3表示。
左图:有两个交叉点,对应类别1方差不等于类别2方差情况,分类中最为典型情况。
中图:有一个交叉点,但是这只能发生在 类别1方差等于类别2方差的情况下,而实际应用中很少有这样情况。要明白教科书(如2006年Bishop专著中图1.26)中仅给单交叉点图形并非是分类中的典型情况。
右图:无交叉点(类别1方差不等于类别2方差),但是类别2的概率远远低于类别1的概率。为极端不平衡数据中典型情况。
Tr1与Tr2分别为拒识门槛值。周先生1970年文章给出Tr1与Tr2分别在0与1之间。我们进一步给出了两者之和必须满足在0与1之间的约束。同时给出了一般情况下的推断规则。当Tr1与Tr2都设定为0.5时,则恢复到无拒识分类情况。

这里的推断规则等价于上页中的规则,只是表达中换为代价矩阵元素。我们推导了拒识情况下的拒识门槛值Tr1和Tr2与代价矩阵元素的关系式,并给出了各个变量的不等式约束关系。
这些计算公式的具体推导过程可见本人文章(Hu,2014)中附录A部分。
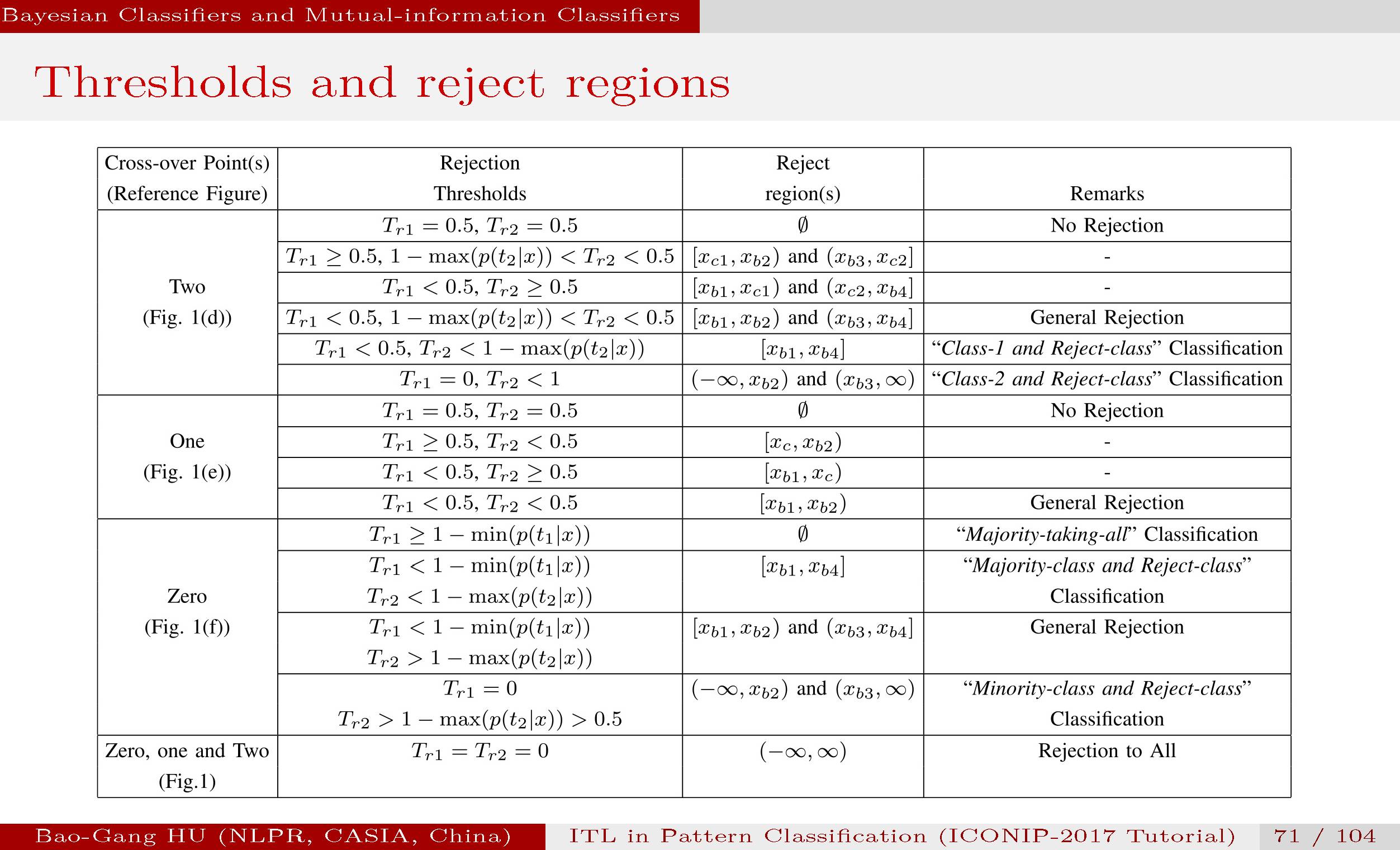
根据各种拒识门槛值设定,可以组合出各种分类,比如“小类与拒识类”的两类分类输出。

定理5证明了贝叶斯二值分类器在未设定代价矩阵情况下(相当于缺省地选择了0-1代价方式),如果小类趋于零则该分类器会将其小类样本全部分错。即贝叶斯二值分类器误差会趋向等于小类概率。
这个定理告诉我们贝叶斯分类器并不在本质上能够保护小类。另一个解释可以是:为取得理论上最小的分类误差,贝叶斯分类器宁愿牺牲小类样本。具体证明见原文。

定理6证明了二值分类器(贝叶斯或非贝叶斯)中,无拒识分类的代价矩阵独立参数是1个(这个结论前人已经证明)。拒识分类的代价矩阵独立参数最大为2个(为首次证明)。具体证明见原文。从69页推断规则中我们也可以理解Tr1与Tr2两个参数即可以确定一个二值拒识分类器。对应的代价矩阵中6个自由参数(或元素)是冗余的。如果我们设定Tr1=Tr2/2, 则拒识分类的代价矩阵独立参数变为1个。
我们由证明中还推论了m类分类中的代价矩阵中的独立参数最大是m。这也是首次给出的知识发现。

我们讨论了独立参数定理在拒识分类中的意义。指明应用代价矩阵可能会产生若干问题。
问题1:对代价矩阵设定会出现不一致性的解释。我们给出两种设定,分别是误差类别代价相同,与拒识类别代价相同。我们认为它们会是不同的分类器,而通过70页中的拒识门槛值Tr1和Tr2与代价矩阵元素的关系式,我们可以获得同一个分类器结果,其输入对应了两种设定。由此产生了两种解释。
该定理建议应用独立参数Tr1和Tr2来获得一致性解释。但是这不是分类(或医学诊断)中常规的操作。

问题2:拒识类别代价设定困难。代价设定的初始原因之一是由于数据不平衡要保护小类。在无拒识分类情况中,人们采取了“再平衡”策略获得客观的误差代价设定,即大类误差对应小类概率,小类误差对应大类概率。然而,当分类扩展到包括拒识类别,如何给定或分配拒识代价值基本上无规律可寻。
客观性在机器学习中是一个挑战。我们认为各种自由参数(如代价)是由数据决定的方符合客观性。任何人为设定方式都是主观的。

给定了互信息分类器,以最大归一化互信息为学习目标。其中应用了修正的互信息计算公式以适应拒识分类情况。我们是通过混淆矩阵来获得联合概率分布的估计。
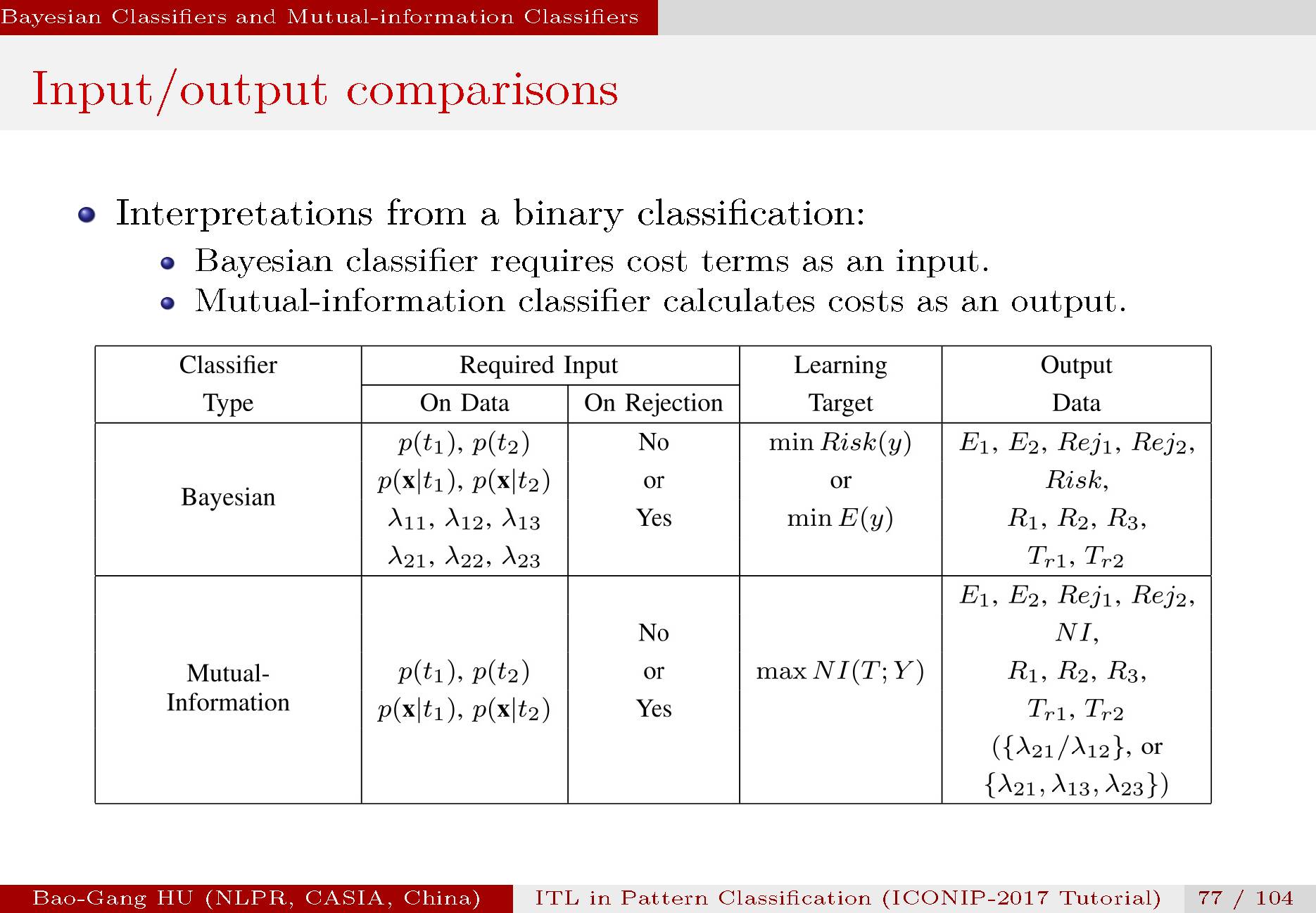
表中对比了贝叶斯与互信息分类器的输入与输出情况。当贝叶斯分类器需要代价矩阵或拒识门槛值作为输入量时,互信息分类器是将其变为输出结果。
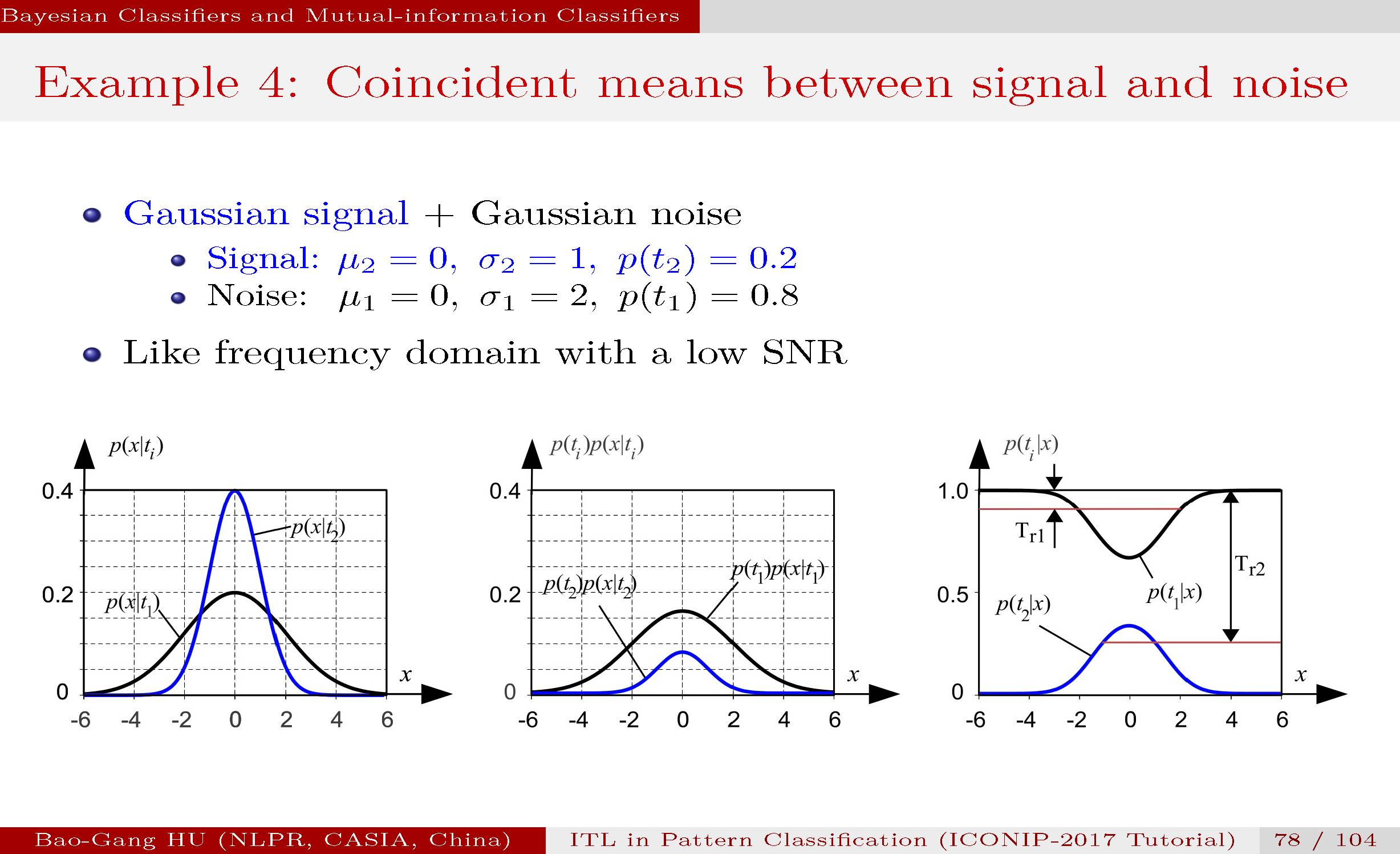
左图:给出了两类的均值是等同,方差不同。
中图:经过类别概率加权乘积到两个分布,可以看到小类(如信号)被淹没在大类(如噪声)中。横轴可以理解为是频域,在两类信号叠加下如何恢复有用信号?
右图:转换为后验概率曲线表达,我们可以看到在任何观察特征x值下,总有大类后验概率值大于小类后验概率值的结果。

如果应用贝叶斯分类器与0-1代价,无拒识类别。解析解表明小类全部错误,大类完全正确。
而这实际对应了无信息分类(zero-information classification)中的一种。读者设想一下该题如何转变为拒识分类,你如何设定相关代价参数?

应用互信息分类器并选择有拒识类别。解析解得出的计算结果表明,70%的有用信号被正确分类出来。特别重要的是,该分类器是自动计算出拒识门槛值。
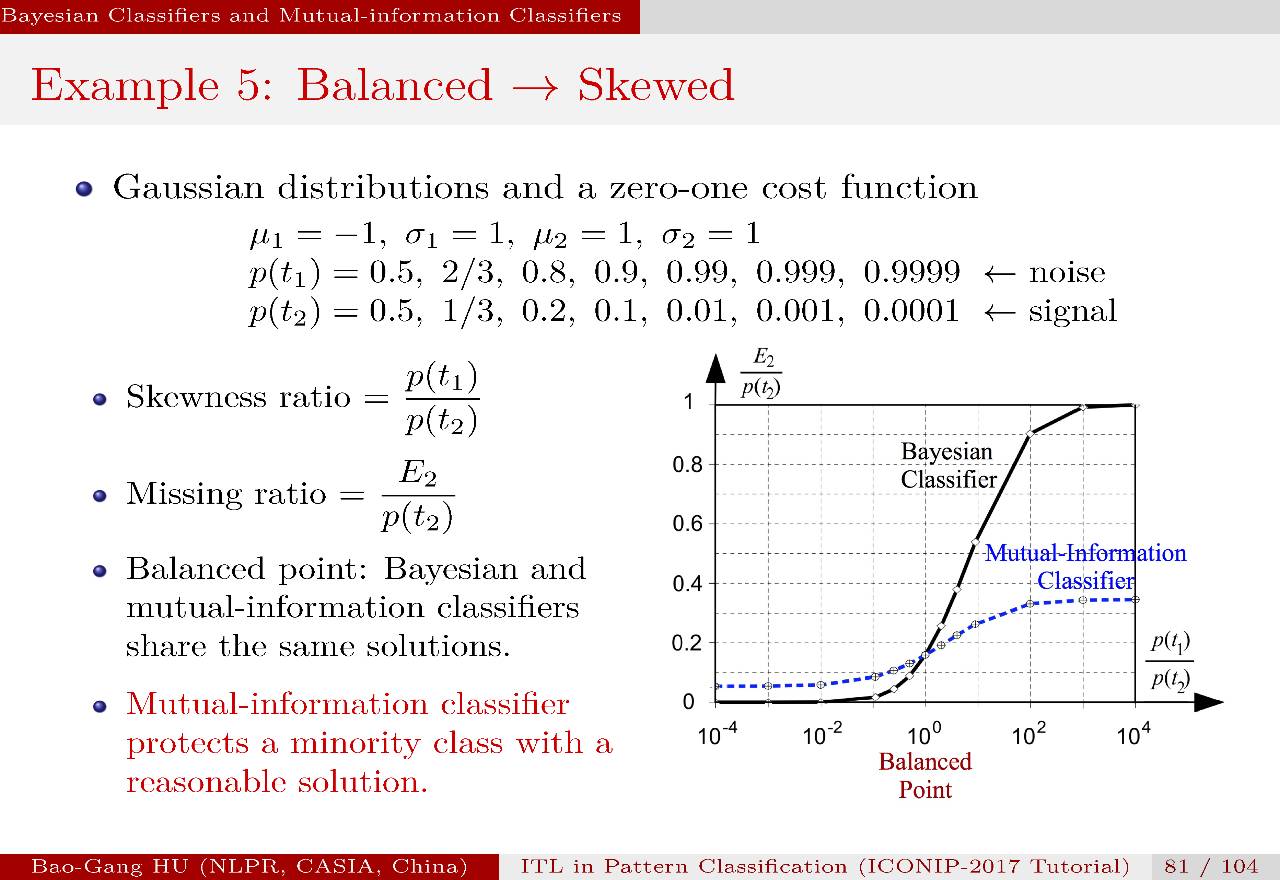
图中横坐标为不平衡比,纵坐标是漏检率。两个曲线分别对应了两种分类器。交叉点对应了类别为平衡分布(p1=p2)。可以看到,当不平衡比趋于极端时,贝叶斯分类器的漏检率是100%。而互信息分类器的漏检率是低于40%,说明它至少是一个有用的弱分类器。
我个人理解该例题的理论意义在于否定了所谓“贝叶斯大脑”的假说?该假说认为贝叶斯定理是大脑推理的统一解释理论。根据“证伪原理”,一个反证实例即可以推翻一个假说。而证实则要穷举,因此实际中是无法实现的。至少该例题支撑了信息指标可以解释不平衡分类中保护小类的机理。

该章前面的例题都是解析解。对于真实数据下面展开了互信息分类器的具体研究,前提是没有分布信息。这就涉及了学习算法。为此我们采取应用传统分类器计算初值,在获得混淆矩阵结果后,应用互信息为学习目标。其中我们先计算无拒识类别下的情况,在调整归一化代价参数下获得最大互信息后,该归一化代价参数固定。开始计算拒识类别情况,其中有两个新的归一化代价参数,获得最大互信息后,可以获得唯一解释的三个归一化代价参数。
读者可以思考为什么这会是唯一解释,而不存在不一致性解释的问题?再有就是保证各个归一化代价参数的非负条件?

左图:为无拒识类别下的ROC理论曲线。
右图:为拒识类别下的ROC理论曲线。据我们所知,这是首次给出二维ROC表示下的拒识类别解释。过去有文献记录是增加一维来表示拒识类别。该二维ROC曲线对于理解误差,拒识与各个参数关联更为简洁而十分重要。要理解左图只是该图的特例。
回答上页问题2:非负条件是ROC为严格凸曲线。
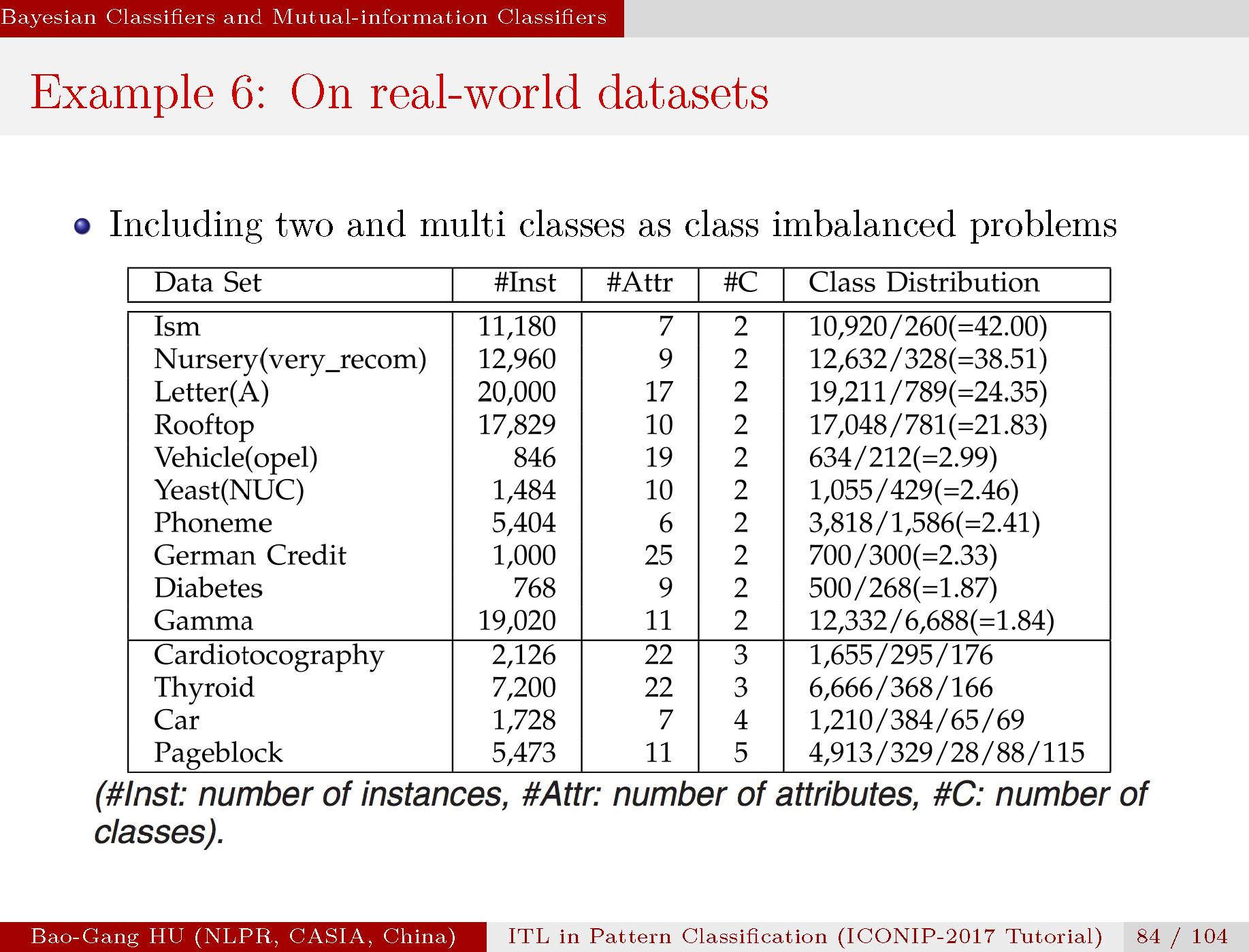
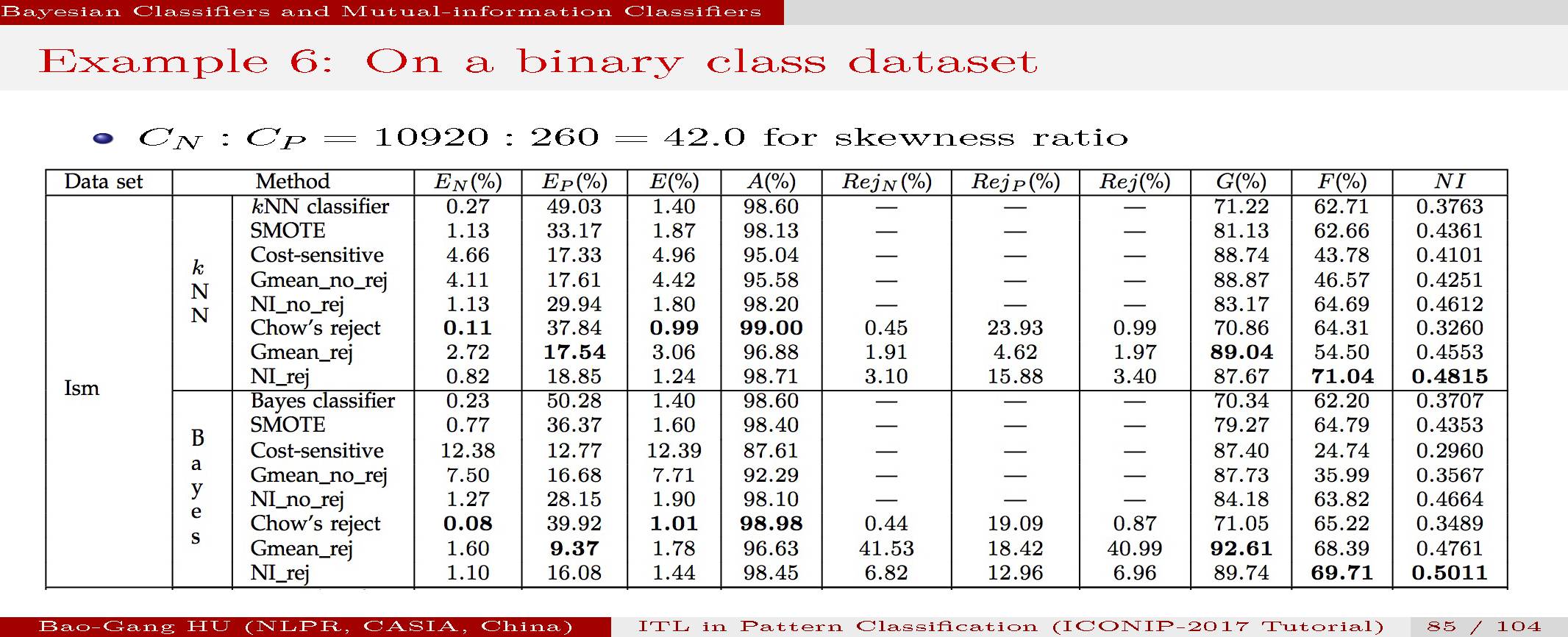
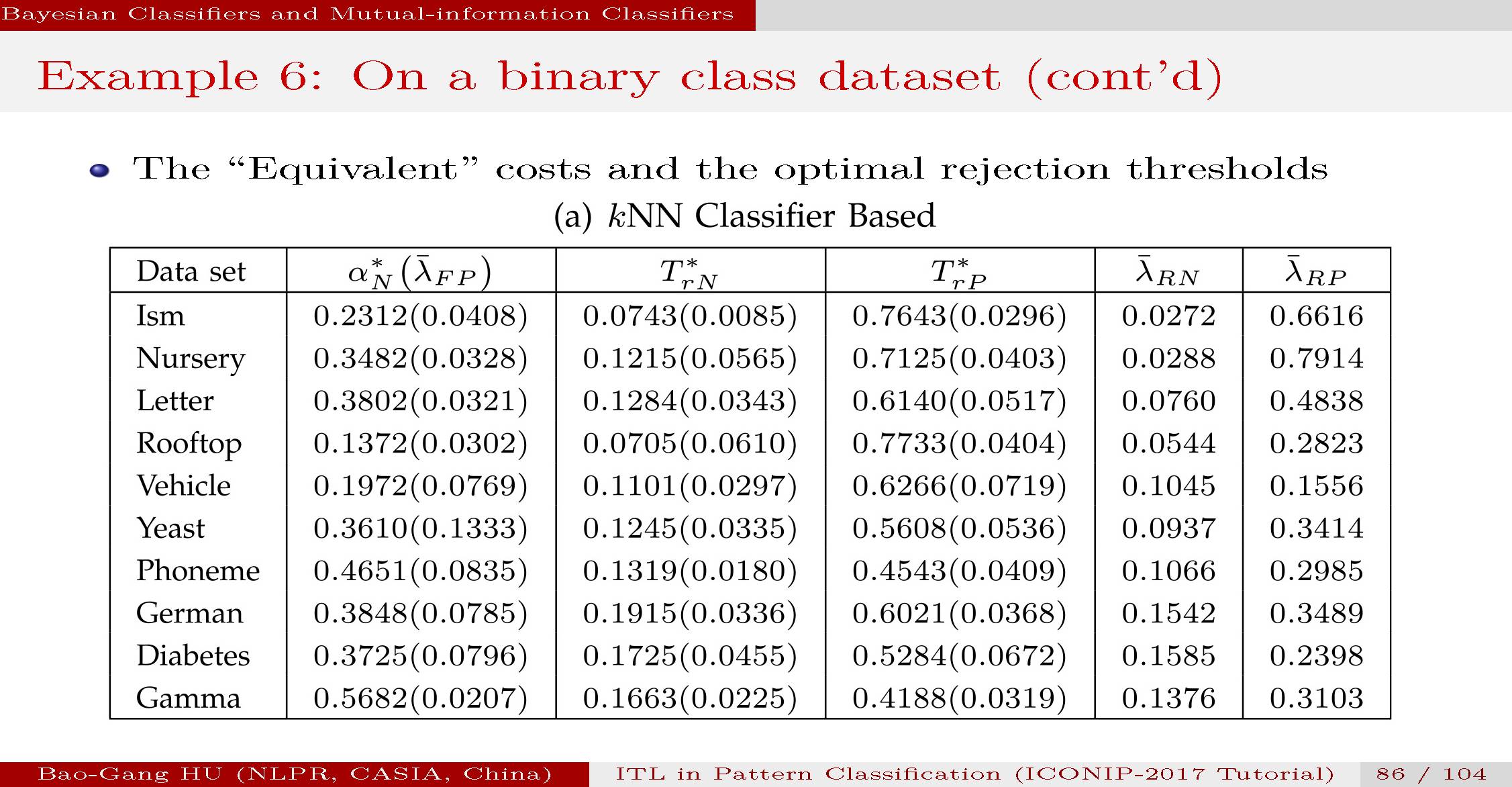
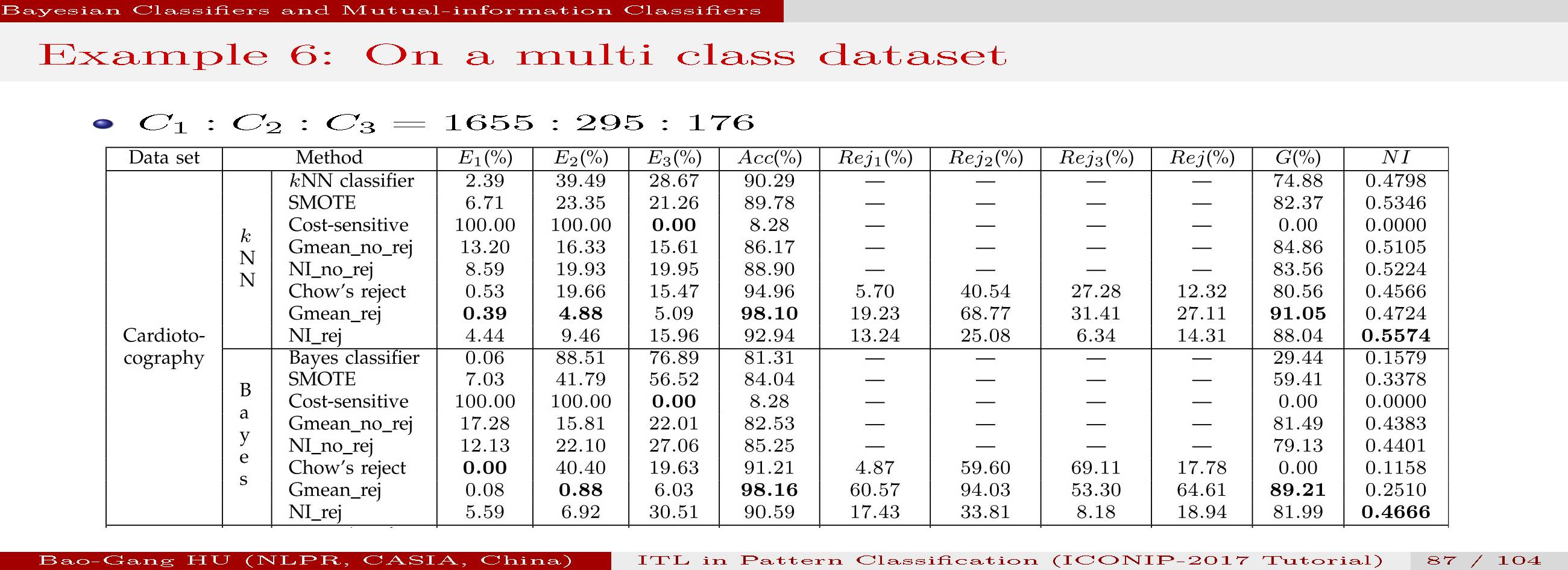
我们根据公开数据集进行了多种分类方法对比数值实验。包括二值分类与多值分类。
具体情况参见文章。计算结果表明互信息分类器能够给出比较合理的结果。
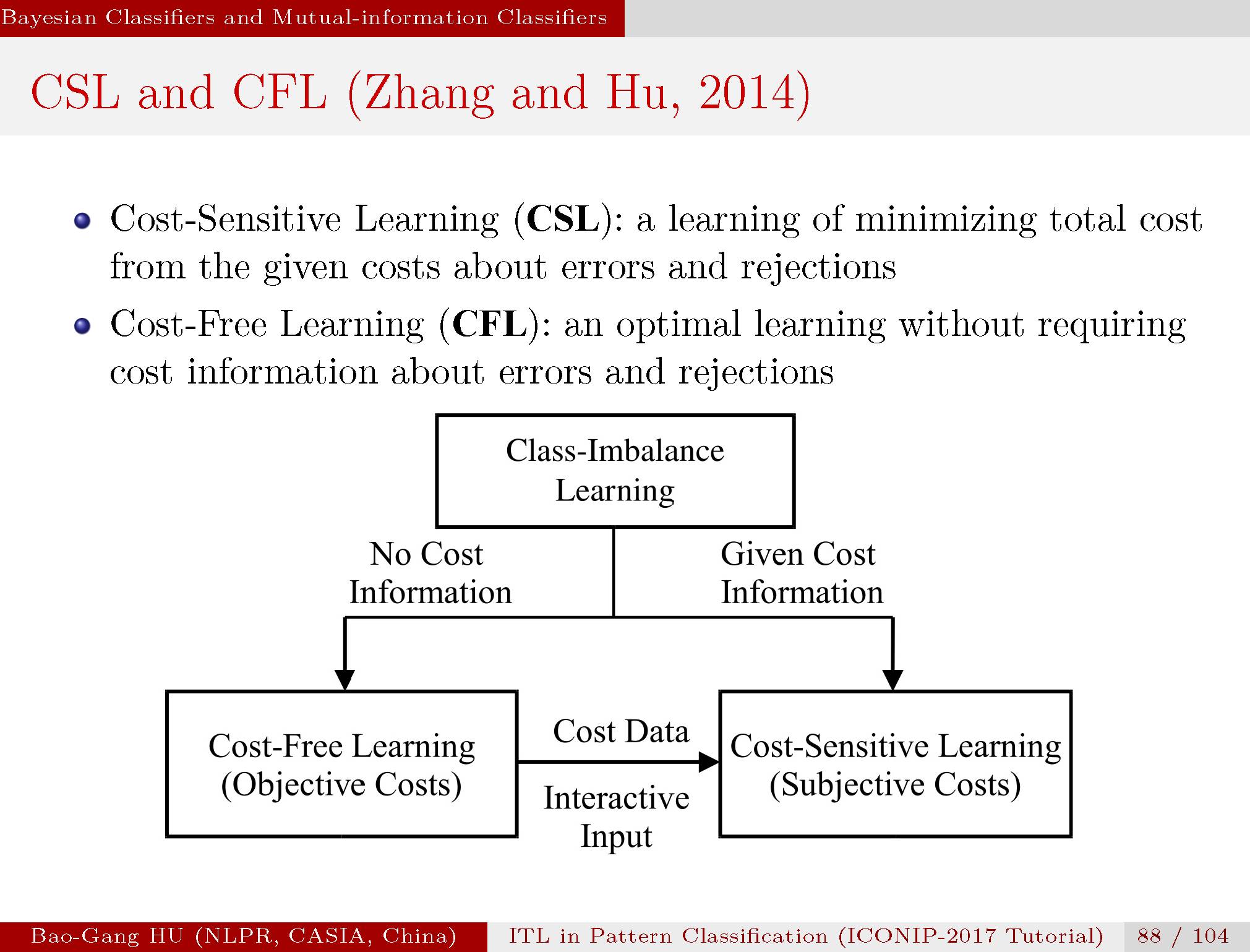
我们将不平衡数据学习进一步分为两种学习,更为传统的是“代价敏感学习”与我们新提出的“代价缺失学习”。
两者区别主要源于应用中给定的条件不同。如果给定代价信息,代价敏感学习只能是一种主观方法。在没有代价信息时,我们希望代价缺失学习(如互信息分类器)不仅能够给出合理计算结果,还能够自动计算内在的代价信息并输出,以便用户调整。它会为主观分类中提供一种客观结果的参照。代价敏感学习与代价缺失学习的关联关系如图。

事实上代价缺失学习方法已经存在。如已有的AUC,F准则,几何平均,“再平衡”方法都不需要代价信息来实现不平衡数据中的代价缺失学习。但是它们均无法在拒识分类学习中胜任。而互信息分类器在拒识分类学习中表现了独特的优势。该方法能够根据数据的分布自动平衡误差类别与拒识类别。
第5章总结:本章主要是基于拒识学习中考察互信息分类器与贝叶斯分类器。为了理解互信息分类器与已有分类器的不同,我们将贝叶斯分类器作为参照物。在考察贝叶斯拒识分类器设计中我们受到来自于华人学者周绍康先生开创性研究工作的启发。阅读周先生1970年文章之后让我们思考应该发展贝叶斯二值拒识分类器一般形式的理论方法。由此产生了第69至71页中新的贝叶斯二值拒识分类计算公式。周先生的计算公式(不区分误差与拒识类型)成为其中一种特例, 他还设定了关系式:误差代价> 拒识代价>正确分类代价(Chow, 1970, 公式(22)之后)。而我们可以从理论中导出这样的关系式。69页与83页中的图形都是新的基础知识,需要读者理解并能够解释。另一方面我们首次考察了拒识分类以及多值分类中代价矩阵的独立参数个数,这与分类器类型无关。
存在问题:如何发展互信息为学习目标(基本上为非凸函数)的高速有效的学习方法仍是开放问题。
第六章:总结与讨论


本教学课程介绍了信息论在模式分类中的基本关系。基于信息论理论的机器学习研究将会对信息论,模式识别等领域都是促进发展。其中我们给出了若干研究后的新进展。

同时给出了个人认为的应用熵函数的优缺点。
优点:包容高阶统计量的计算,提供一种客观指标,对于离散变量计算复杂度相对不高,可能是一种统一的解释框架,
缺点:非日常生活中可理解的概念,在许多工程应用中非常规要求,任然需求经验指标的计算获得最终决策,函数呈现非凸性质,对于连续变量需要估计而显著增加计算复杂度

人们日常活动可以认为是处在大数据处理中。在这样背景下讨论并理解人类应用何种智能准则是十分重要的。 其中一个智能准则就是有效保护小类,因为相对于大数据有用信息通常是小类。我们应用“沙与米”的多少变换说明“物以稀为贵”在许多应用中是常规的智能准则。但是应用中也会有例外,你能够举出实例吗?
在此提个“学说明”的问题:当“物以稀为贵”是一种智能准则(或学习目标)时,支撑它的背后数学理论原理(或计算层面的表达)是什么呢?是贝叶斯原理么?你怎么验证?

未来人工智能的挑战是:“学习+思考”后走向“理解(或认知)”
我们提倡将人工智能研究,或机器学习,模式识别等研究最终落脚于是一种“洞见(或见解,认知)式”研究。该类研究是对自然,机器,或数据等开展原理、机制、解释性的探索。
它同时包含了两个层面中的问题。本课程试图给出这方面两个原理性研究样例。我们认为目前人工智能研究更多是“工具”式研究。当这方面工作十分必要时,读者还应该思考未来的发展趋势。

基于14页中列举的前人研究成果和结论,本人大胆提出“学习目标选择猜想” ,并具体表述如下:
“机器学习中所有学习目标的计算表达均可以应用熵函数的优化形式来描述或解释”。
上述猜想并非目标于否定应用基于经验式的计算表达。
主旨是要回到“统一理论”为主题的思考。该主题能够促使我们尽快地切入到机器学习以及人工智能研究中的核心问题:学习过程的基础原理或定律会是什么?科学层面解释性的统一理论框架存在否,又会是什么?

本章给出若干基于信息理论的典型研究工作表明未来研究工作展望和发展空间
特别要提及的有:
Becker与Hinton 1992年发表在《自然》上的方法,为无监督学习带来启迪。
Shwartz-Ziv 与Tishby 2017 年的研究,其中信息瓶颈等方法为深度学习带来更好的解释性。
我们还应关注量子信息理论方面的研究工作,并应理解信息理论自身要发展。

这是针对第4章中的开源代码工具箱。Scilab是类似于Matlab的开源软件。打开该工具箱中文件,采用“拷贝+粘贴”方式即可在Scilab界面中运行程序。这两个图标均为本人设计。希望读者能够未来也给个开源作品设计。

不同于一般教程中会给出的“课下信息(Take home message)”,我们给出“课下思考“。除了这3个内容外,应该结合个人研究给出个人思考,并记录下来不断思考与解答。






注意符号使用中的差异。
第五章和第六章的贝叶斯分类器和互信息分类器、总结和讨论报告结束了,至此胡老师关于基于信息理论的机器学习教程已经全部结束,感谢大家阅读和分享!
今天胡老师专门撰写《“理论在哪里” ?- 参加2017年NIPS会议感言》也在专知平台发出,是为《基于信息理论的机器学习》教程中文注释后记准备的,希望大家继续阅读胡老师的NIPS参会感言。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



