【论文推荐】最新七篇图像描述生成相关论文—CNN+CNN、对抗样本、显著性和上下文注意力、条件生成对抗网络、风格化
【导读】专知内容组整理了近期七篇图像描述生成(Image Captioning)相关文章,为大家进行介绍,欢迎查看!
1.Quantifying the visual concreteness of words and topics in multimodal datasets(在多模态数据集中量化词和主题的视觉正确性)
作者:Jack Hessel,David Mimno,Lillian Lee
NAACL HLT 2018
机构:Cornell University
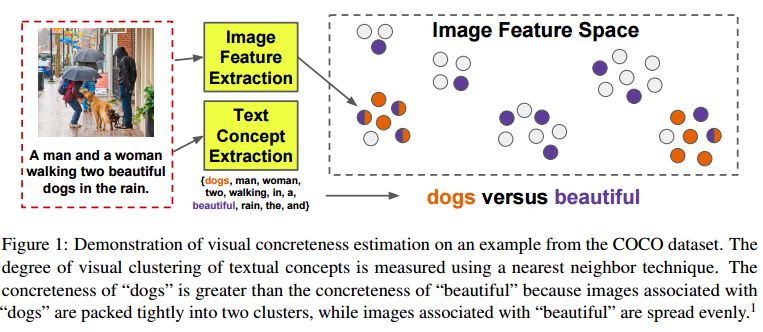
摘要:Multimodal machine learning algorithms aim to learn visual-textual correspondences. Previous work suggests that concepts with concrete visual manifestations may be easier to learn than concepts with abstract ones. We give an algorithm for automatically computing the visual concreteness of words and topics within multimodal datasets. We apply the approach in four settings, ranging from image captions to images/text scraped from historical books. In addition to enabling explorations of concepts in multimodal datasets, our concreteness scores predict the capacity of machine learning algorithms to learn textual/visual relationships. We find that 1) concrete concepts are indeed easier to learn; 2) the large number of algorithms we consider have similar failure cases; 3) the precise positive relationship between concreteness and performance varies between datasets. We conclude with recommendations for using concreteness scores to facilitate future multimodal research.
期刊:arXiv, 2018年5月24日
网址:
http://www.zhuanzhi.ai/document/0acb3e28920bebf4fd831996d41d2c5d
2.CNN+CNN: Convolutional Decoders for Image Captioning(CNN+CNN: 图像描述生成的卷积解码器)
作者:Qingzhong Wang,Antoni B. Chan
机构:City University of Hong Kong
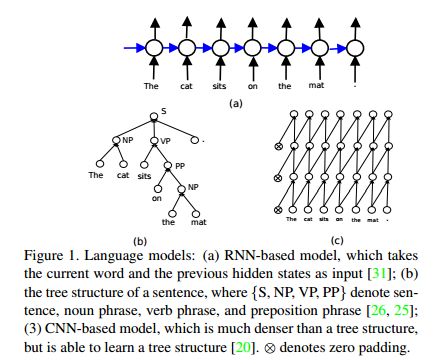
摘要:Image captioning is a challenging task that combines the field of computer vision and natural language processing. A variety of approaches have been proposed to achieve the goal of automatically describing an image, and recurrent neural network (RNN) or long-short term memory (LSTM) based models dominate this field. However, RNNs or LSTMs cannot be calculated in parallel and ignore the underlying hierarchical structure of a sentence. In this paper, we propose a framework that only employs convolutional neural networks (CNNs) to generate captions. Owing to parallel computing, our basic model is around 3 times faster than NIC (an LSTM-based model) during training time, while also providing better results. We conduct extensive experiments on MSCOCO and investigate the influence of the model width and depth. Compared with LSTM-based models that apply similar attention mechanisms, our proposed models achieves comparable scores of BLEU-1,2,3,4 and METEOR, and higher scores of CIDEr. We also test our model on the paragraph annotation dataset, and get higher CIDEr score compared with hierarchical LSTMs
期刊:arXiv, 2018年5月23日
网址:
http://www.zhuanzhi.ai/document/1444351b6639e42b5db47b588b76595c
3.Joint Image Captioning and Question Answering(联合图像描述生成和问答)
作者:Jialin Wu,Zeyuan Hu,Raymond J. Mooney
机构:The University of Texas at Austin
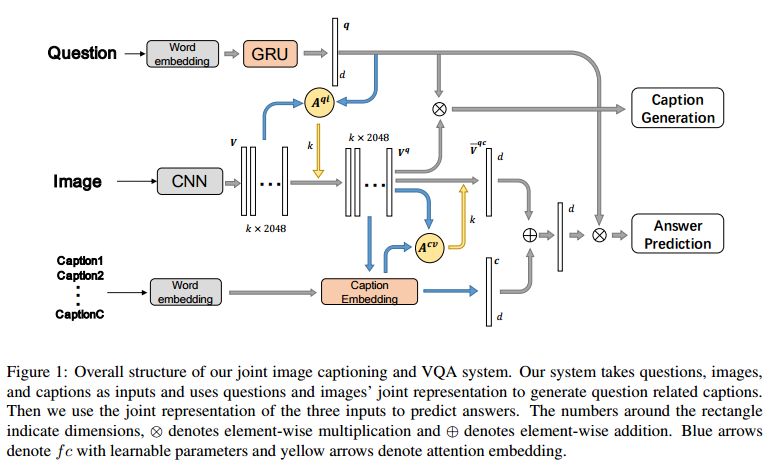
摘要:Answering visual questions need acquire daily common knowledge and model the semantic connection among different parts in images, which is too difficult for VQA systems to learn from images with the only supervision from answers. Meanwhile, image captioning systems with beam search strategy tend to generate similar captions and fail to diversely describe images. To address the aforementioned issues, we present a system to have these two tasks compensate with each other, which is capable of jointly producing image captions and answering visual questions. In particular, we utilize question and image features to generate question-related captions and use the generated captions as additional features to provide new knowledge to the VQA system. For image captioning, our system attains more informative results in term of the relative improvements on VQA tasks as well as competitive results using automated metrics. Applying our system to the VQA tasks, our results on VQA v2 dataset achieve 65.8% using generated captions and 69.1% using annotated captions in validation set and 68.4% in the test-standard set. Further, an ensemble of 10 models results in 69.7% in the test-standard split.
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/2e99d4ae006c8e0dc69b74084b02dfc1
4.Attacking Visual Language Grounding with Adversarial Examples: A Case Study on Neural Image Captioning(以对抗样本攻击视觉语言配准:一个关于神经图像描述生成的案例研究)
作者:Hongge Chen,Huan Zhang,Pin-Yu Chen,Jinfeng Yi,Cho-Jui Hsieh
ACL 2018
摘要:Visual language grounding is widely studied in modern neural image captioning systems, which typically adopts an encoder-decoder framework consisting of two principal components: a convolutional neural network (CNN) for image feature extraction and a recurrent neural network (RNN) for language caption generation. To study the robustness of language grounding to adversarial perturbations in machine vision and perception, we propose Show-and-Fool, a novel algorithm for crafting adversarial examples in neural image captioning. The proposed algorithm provides two evaluation approaches, which check whether neural image captioning systems can be mislead to output some randomly chosen captions or keywords. Our extensive experiments show that our algorithm can successfully craft visually-similar adversarial examples with randomly targeted captions or keywords, and the adversarial examples can be made highly transferable to other image captioning systems. Consequently, our approach leads to new robustness implications of neural image captioning and novel insights in visual language grounding.

期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/399259c725b0ce4c5b400bebc63ccfe8
5.Paying More Attention to Saliency: Image Captioning with Saliency and Context Attention(Paying More Attention to Saliency:基于显著性和上下文注意力的图像描述生成)
作者:Marcella Cornia,Lorenzo Baraldi,Giuseppe Serra,Rita Cucchiara
ACM Transactions on Multimedia Computing, Communications and Applications
机构:University of Modena and Reggio Emilia,University of Udine
摘要:Image captioning has been recently gaining a lot of attention thanks to the impressive achievements shown by deep captioning architectures, which combine Convolutional Neural Networks to extract image representations, and Recurrent Neural Networks to generate the corresponding captions. At the same time, a significant research effort has been dedicated to the development of saliency prediction models, which can predict human eye fixations. Even though saliency information could be useful to condition an image captioning architecture, by providing an indication of what is salient and what is not, research is still struggling to incorporate these two techniques. In this work, we propose an image captioning approach in which a generative recurrent neural network can focus on different parts of the input image during the generation of the caption, by exploiting the conditioning given by a saliency prediction model on which parts of the image are salient and which are contextual. We show, through extensive quantitative and qualitative experiments on large scale datasets, that our model achieves superior performances with respect to captioning baselines with and without saliency, and to different state of the art approaches combining saliency and captioning.

期刊:arXiv, 2018年5月21日
网址:
http://www.zhuanzhi.ai/document/2a9e1524fd6b66d1492b9813a4036690
6.Improving Image Captioning with Conditional Generative Adversarial Nets(用条件生成对抗网络改善图像描述生成)
作者:Chen Chen,Shuai Mu,Wanpeng Xiao,Zexiong Ye,Liesi Wu,Fuming Ma,Qi Ju
机构:Tencent
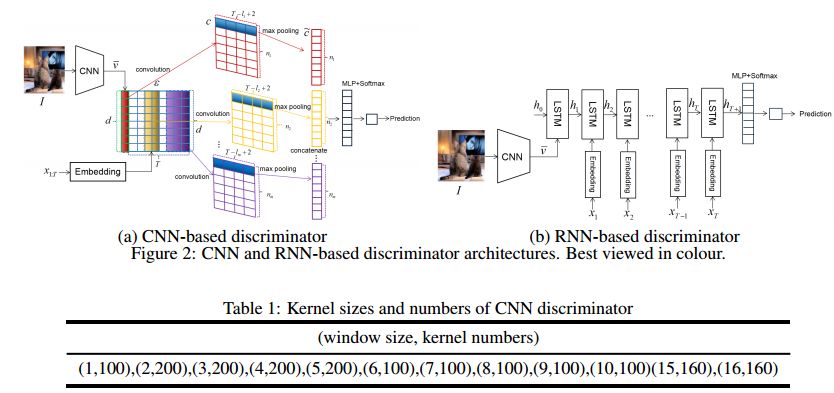
摘要:In this paper, we propose a novel conditional generative adversarial nets based image captioning framework as an extension of traditional reinforcement learning (RL) based encoder-decoder architecture. To deal with the inconsistent evaluation problem between objective language metrics and subjective human judgements, we are inspired to design some "discriminator" networks to automatically and progressively determine whether generated caption is human described or machine generated. Two kinds of discriminator architecture (CNN and RNN based structures) are introduced since each has its own advantages. The proposed algorithm is generic so that it can enhance any existing encoder-decoder based image captioning model and we show that conventional RL training method is just a special case of our framework. Empirically, we show consistent improvements over all language evaluation metrics for different stage-of-the-art image captioning models.
期刊:arXiv, 2018年5月18日
网址:
http://www.zhuanzhi.ai/document/97a5d2d63a0994814bb235f121b7cabb
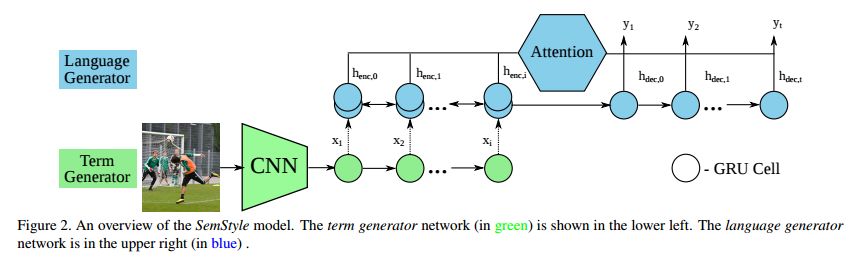
7.SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text(SemStyle: 学习使用未对齐的文本生成风格化的图像描述生成)
作者:Alexander Mathews,Lexing Xie,Xuming He
Accepted at CVPR 2018
机构:ShanghaiTech University,Australian National University
摘要:Linguistic style is an essential part of written communication, with the power to affect both clarity and attractiveness. With recent advances in vision and language, we can start to tackle the problem of generating image captions that are both visually grounded and appropriately styled. Existing approaches either require styled training captions aligned to images or generate captions with low relevance. We develop a model that learns to generate visually relevant styled captions from a large corpus of styled text without aligned images. The core idea of this model, called SemStyle, is to separate semantics and style. One key component is a novel and concise semantic term representation generated using natural language processing techniques and frame semantics. In addition, we develop a unified language model that decodes sentences with diverse word choices and syntax for different styles. Evaluations, both automatic and manual, show captions from SemStyle preserve image semantics, are descriptive, and are style shifted. More broadly, this work provides possibilities to learn richer image descriptions from the plethora of linguistic data available on the web.
期刊:arXiv, 2018年5月18日
网址:
http://www.zhuanzhi.ai/document/5c6cc62f458e097fe58385029e796c40
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



