【论文推荐】最新5篇自动问答相关论文——多关系自动问答、知识图谱联合实体和关系、生物医学问题、维基百科语料数据、多句式旅游推荐
【导读】专知内容组整理了最近自动问答相关文章,为大家进行介绍,欢迎查看!
1. An Interpretable Reasoning Network for Multi-Relation Question Answering(基于可解释推理网络的多关系自动问答)
作者:Mantong Zhou,Minlie Huang,Xiaoyan Zhu
摘要:Multi-relation Question Answering is a challenging task, due to the requirement of elaborated analysis on questions and reasoning over multiple fact triples in knowledge base. In this paper, we present a novel model called Interpretable Reasoning Network that employs an interpretable, hop-by-hop reasoning process for question answering. The model dynamically decides which part of an input question should be analyzed at each hop; predicts a relation that corresponds to the current parsed results; utilizes the predicted relation to update the question representation and the state of the reasoning process; and then drives the next-hop reasoning. Experiments show that our model yields state-of-the-art results on two datasets. More interestingly, the model can offer traceable and observable intermediate predictions for reasoning analysis and failure diagnosis.

期刊:arXiv, 2018年1月15日
网址:
http://www.zhuanzhi.ai/document/c6a9000b254c9d4d2fa4470387bcbe52
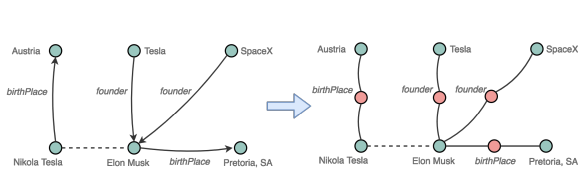
2. EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs(EARL:基于知识图谱的联合实体和关系的自动问答)
作者:Mohnish Dubey,Debayan Banerjee,Debanjan Chaudhuri,Jens Lehmann
摘要:In order to answer natural language questions over knowledge graphs, most processing pipelines involve entity and relation linking. Traditionally, entity linking and relation linking has been performed either as dependent sequential tasks or independent parallel tasks. In this paper, we propose a framework called "EARL", which performs entity linking and relation linking as a joint single task. EARL uses a graph connection based solution to the problem. We model the linking task as an instance of the Generalised Travelling Salesman Problem (GTSP) and use GTSP approximate algorithm solutions. We later develop EARL which uses a pair-wise graph-distance based solution to the problem.The system determines the best semantic connection between all keywords of the question by referring to a knowledge graph. This is achieved by exploiting the "connection density" between entity candidates and relation candidates. The "connection density" based solution performs at par with the approximate GTSP solution.We have empirically evaluated the framework on a dataset with 5000 questions. Our system surpasses state-of-the-art scores for entity linking task by reporting an accuracy of 0.65 to 0.40 from the next best entity linker.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/89f729dc2cd8bee92e07e7db662a506d
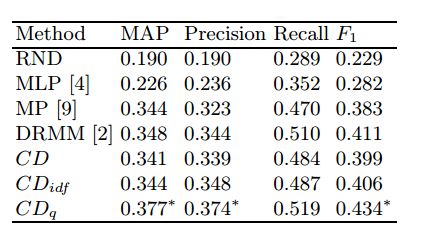
3. Biomedical Question Answering via Weighted Neural Network Passage Retrieval(基于加权神经网络通路检索的生物医学问题自动问答)
作者:Ferenc Galkó,Carsten Eickhoff
摘要:The amount of publicly available biomedical literature has been growing rapidly in recent years, yet question answering systems still struggle to exploit the full potential of this source of data. In a preliminary processing step, many question answering systems rely on retrieval models for identifying relevant documents and passages. This paper proposes a weighted cosine distance retrieval scheme based on neural network word embeddings. Our experiments are based on publicly available data and tasks from the BioASQ biomedical question answering challenge and demonstrate significant performance gains over a wide range of state-of-the-art models.
期刊:arXiv, 2018年1月9日
网址:
http://www.zhuanzhi.ai/document/2ced5743129d136a3cc07e123e06a0b1
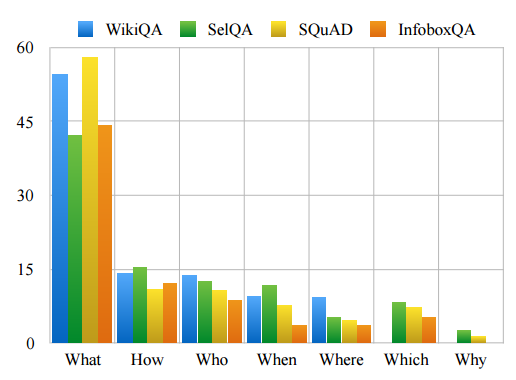
4. Analysis of Wikipedia-based Corpora for Question Answering(基于自动问答的维基百科语料数据的分析)
作者:Tomasz Jurczyk,Amit Deshmane,Jinho Choi
摘要:This paper gives comprehensive analyses of corpora based on Wikipedia for several tasks in question answering. Four recent corpora are collected,WikiQA, SelQA, SQuAD, and InfoQA, and first analyzed intrinsically by contextual similarities, question types, and answer categories. These corpora are then analyzed extrinsically by three question answering tasks, answer retrieval, selection, and triggering. An indexing-based method for the creation of a silver-standard dataset for answer retrieval using the entire Wikipedia is also presented. Our analysis shows the uniqueness of these corpora and suggests a better use of them for statistical question answering learning.
期刊:arXiv, 2018年1月7日
网址:
http://www.zhuanzhi.ai/document/90678ba6a67f840ca1b0780cf29a6190
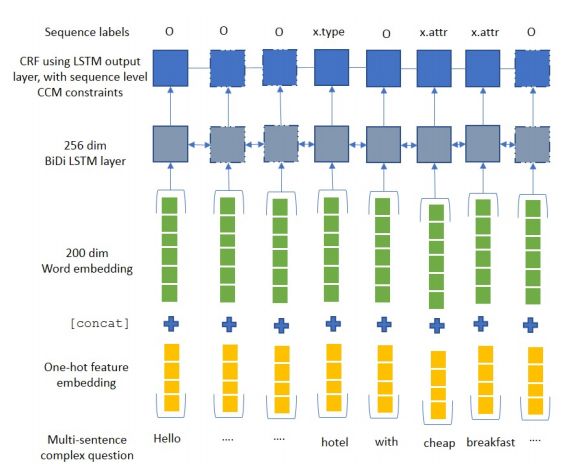
5. Towards Understanding and Answering Multi-Sentence Recommendation Questions on Tourism(多句式旅游推荐问题:理解与回答)
作者:Danish Contractor,Barun Patra,Mausam Singla,Parag Singla
摘要:We introduce the first system towards the novel task of answering complex multisentence recommendation questions in the tourism domain. Our solution uses a pipeline of two modules: question understanding and answering. For question understanding, we define an SQL-like query language that captures the semantic intent of a question; it supports operators like subset, negation, preference and similarity, which are often found in recommendation questions. We train and compare traditional CRFs as well as bidirectional LSTM-based models for converting a question to its semantic representation. We extend these models to a semisupervised setting with partially labeled sequences gathered through crowdsourcing. We find that our best model performs semi-supervised training of BiDiLSTM+CRF with hand-designed features and CCM(Chang et al., 2007) constraints. Finally, in an end to end QA system, our answering component converts our question representation into queries fired on underlying knowledge sources. Our experiments on two different answer corpora demonstrate that our system can significantly outperform baselines with up to 20 pt higher accuracy and 17 pt higher recall.
期刊:arXiv, 2018年1月6日
网址:
http://www.zhuanzhi.ai/document/0bcdf4d6ea5522a8df5f2120056989af
更多论文请上专知查看:PC登录 www.zhuanzhi.ai 点击论文查看
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



