16625份AI论文透露:26年来,人工智能并没有出现新技术,深度学习正在走向终点?
今天你听到的关于人工智能的几乎所有事情都要归功于深度学习。这类算法的工作原理是使用统计数据来发现数据中的模式,事实证明,它在模仿人类技能(如我们的视觉和听觉能力)方面非常强大。在一个非常狭窄的范围内,它甚至可以模仿我们的推理能力。这些功能为谷歌的搜索、Facebook的新闻feed和Netflix的推荐引擎提供了强大的支持,并正在改变医疗和教育等行业。
然而,尽管深度学习让人工智能进入了公众的视线,但它只是人类探索复制自身智能历史上的一个小插曲。在不到10年的时间里,它一直处于这一努力的最前沿。当你放大这个领域的整个历史,会很容易意识到它可能很快就会消失。
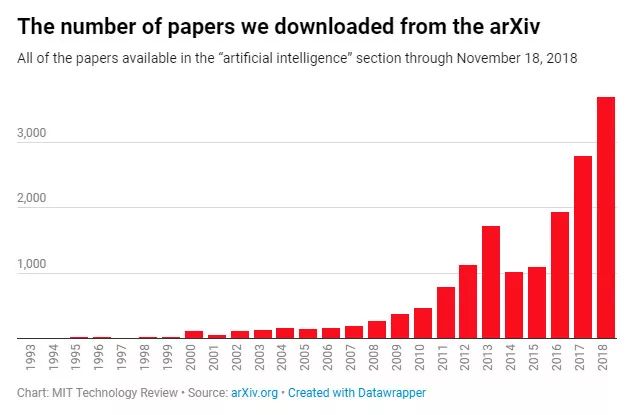
为了探寻人工智能技术在近几十年的发展轨迹,《麻省理工技术评论》下载了截止到2018年11月18日发表在arXiv上的16625篇“人工智能”方向的论文摘要,并对这些年来提到的词汇进行了追踪。
通过《麻省理工技术评论》的分析,发现了三个主要的趋势:90年代末到21世纪初向机器学习的转变,2010年代初神经网络开始普及,以及过去几年强化学习的增长。
有几点需要注意。首先,arXiv的人工智能论文部分只能追溯到1993年,而“人工智能”一词可以追溯到20世纪50年代,因此该数据库只是该领域历史的最新篇章。其次,每年添加到数据库中的论文只是当时该领域正在进行的工作的一小部分。尽管如此,arXiv为收集一些更大的研究趋势和观察不同想法的推动和拉动提供了一个很好的资源。
机器学习的范式
《麻省理工技术评论》发现最大的转变是在21世纪初从基于知识的系统过渡。这些计算机程序基于这样一种思想,即可以使用规则对所有人类知识进行编码。取而代之的是,研究人员转向机器学习——包括深度学习在内的算法的父类别。
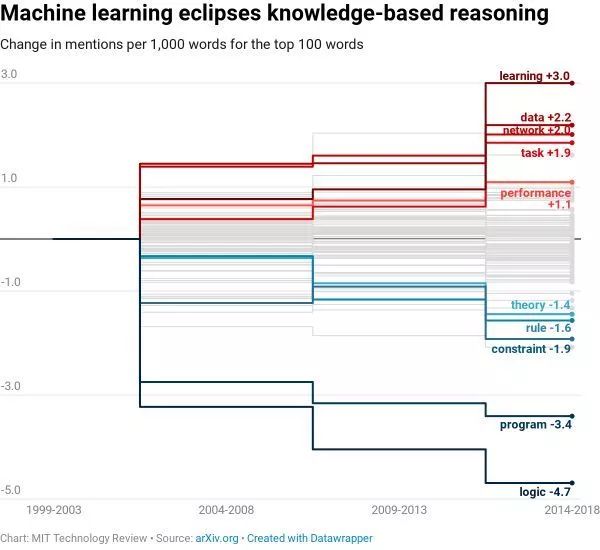
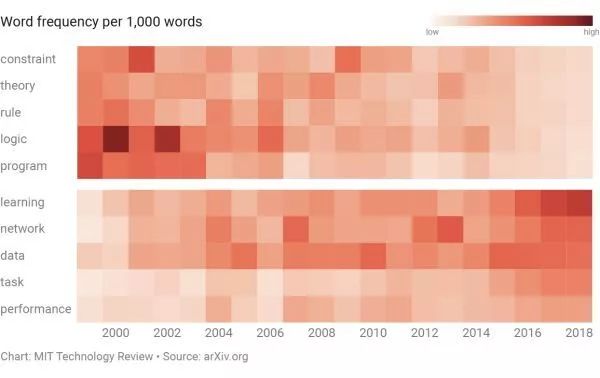
在排名前100的词汇中,与知识系统相关的词汇,如“逻辑”、“约束”、“规则”等词汇的跌幅最大。那些与机器学习相关的——如“数据”、“网络”和“性能”——增长最快。
这种巨大变化的原因相当简单。在20世纪80年代,基于知识的系统获得了广泛的关注,这要归功于围绕着那些试图在机器内部重建常识的雄心勃勃的项目而产生的兴奋情绪。但随着这些项目的展开,研究人员遇到了一个重大问题:系统要做有用的事情,需要对太多的规则进行编码。这推高了成本,大大减缓了正在进行的努力。
机器学习成为了这个问题的答案。这种方法不需要人们手动编码数十万条规则,而是让机器自动从一堆数据中提取这些规则。就这样,该领域抛弃了基于知识的系统,转而改进机器学习。
从分析结果看,“AI”概念的风靡,有三个典型时期:90年代末21世纪初机器学习兴起,2010年代初神经网络概念复辟,近几年强化学习概念卷土重来。

值得注意的是,arXiv的AI论文模块始于1993年,而“人工智能”的概念可以追溯到1950年,因此这一数据库只能反馈近26年以来的AI研究。而且,arXiv每年收录的论文,也仅代表当时人工智能领域的一部分研究。不过,它仍然是观测AI行业研究趋势的最佳窗口。
我们接下来就来看一下,16625份论文提供了哪些信息。
01 起点:解救程序员
基于知识的系统,由人类将知识赋予计算机,而计算机承担知识的存储和管理功能,帮助人类解决问题。转变为机器学习后,计算机可以自主学习所有的人类知识。这是21世纪以来AI研究最大的转变。
在相关论文提及率最高的100个单词中,“逻辑”“约束”“规则”等基于知识系统的词语,自90年代以来出现率显著下降,而“数据”“网络”“性能”增长最为明显。
麻省理工科技评论称,这种变化的原因非常好理解。上世纪80年代,基于知识的系统广受欢迎,但各种各样的项目推进的同时,研究者遇到了一个问题:需要编写太多太多的规则,才能让计算机作出有效决策,这种成本太过高昂,研究者的动力也就随之减少。
机器学习实际上是解决这个问题的方案。机器学习让计算机从一系列数据中提取规则,把程序员从编码“逻辑”“规则”“约束”中解救了出来。
02 神经网络井喷
机器学习开始登上舞台,但是向深度学习的转变并没有马上出现。
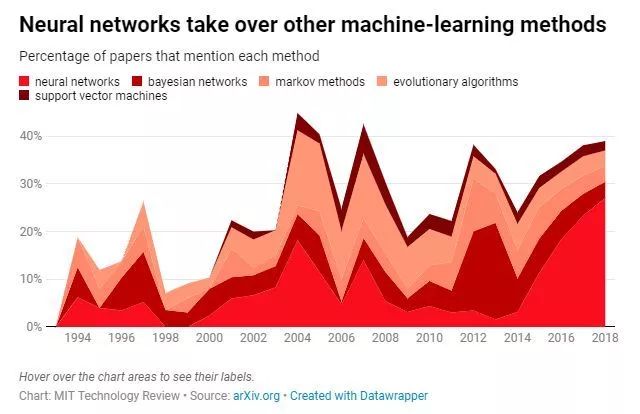
神经网络是深度学习的核心机制,但麻省理工科技评论对16625篇论文关键字检索的结果显示,研究者还尝试了各种其他“提取规则”的方法,包括贝叶斯网络、马尔可夫模型、进化算法和支持向量机(support vector machines,SVM)等。
上世纪90年代到21世纪初,这些方法都在相互竞争。一直到2012年,视觉识别领域一年一度的ImageNet竞赛中,多伦多大学的Geoffrey Hinton教授和两个学生(Ilya Sutskever 和Alex Krizhevsky)的AlexNet横空出世,把图像识别的Top-5错误率(给出的前N个答案中有一个是正确答案的概率)降低到了15.3%,比亚军的26.5%低了41%)。
为了构建识别成千上万图像的系统,该团队采用了卷积神经网络。为避免数据过度拟合,AlexNet采用的神经网络还使用了数据扩充(平移、翻转等),以及随机(概率为0.5)“删除”(dropout)一些神经元来减少工作量等。
Geoffrey Hinton教授当时强调,深度对最终的识别精度尤为重要。深度学习技术由此引起了广泛关注。它从图像识别领域逐渐扩展开来,神经网络概念也随之井喷。
03 强化学习兴起
在深度学习推广数年后,人工智能发生了迄今为止的最后一次重要转变,即强化学习的兴起。
机器学习算法可以分为三种:有监督的学习,无监督的学习,以及强化学习。
有监督的学习给机器提供已经标记过的数据,机器学习的那些行为都是正确的行为。例如,标记过的花卉数据集告诉正在学习的机器模型,哪些照片分别是玫瑰、雏菊和水仙。而在给出一张测试图像时,机器应该把它和学习的数据进行对比,判断那是玫瑰、雏菊还是水仙。
有监督的学习最适用于解决有参照背景的问题。例如物品分类,或是基于面积、位置和公交便利程度判断住宅价格。所以,它是是最常用的也是最实用的机器学习算法。
标记数据集并不容易,所以也有无监督的学习。提供给无监督学习的数据集没有特定的期望结果,或是正确答案。机器需要自己提取特征和规律,来理解数据。
无监督学习的应用场景,包括银行通过账户异常行为判断虚假交易,电商通过已经加入到购物车的产品,推荐相关的其他产品等。
过去几年里,强化学习在研究领域的出现频率迅速提高。强化学习同样也采用未经标记的数据,但与无监督学习不同地是,强化学习还模拟了训练动物地过程,对进行学习的机器提供“奖惩机制”,在执行最优解时提供反馈。
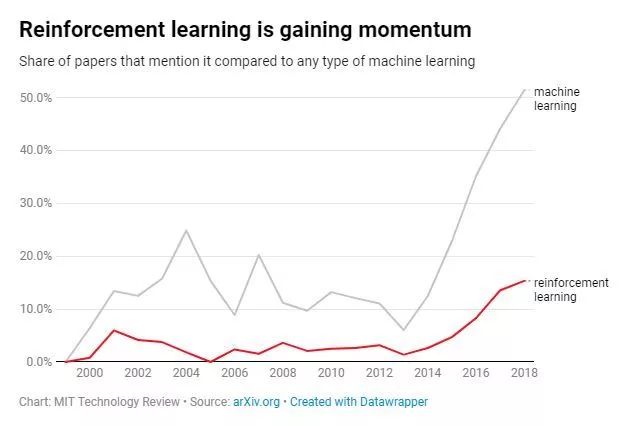
和深度学习一样地,强化学习也是通过里程碑式的突破,才引起了研究者的注意。2015年,DeepMind的AlphaGo在强化学习训练下,成长为可以击败代表人类最高水平的围棋棋手,让埋没数十年地强化学习再次走到大众视线中。
而游戏本身,也是强化学习最好的渠道——它的奖励机制足够明确。在机器作出了正确选择后,它会获得“胜利”的反馈,而这样的反馈越多,机器越能选择正确的策略。
04 下一个十年的AI趋势
从过去二十多年的经验来看,人工智能领域并没有出现什么明显的新技术。各种技术在研究界的地位起起落落,但热门的种种技术,许多都起源于同一时间,即上世纪50年代左右。
以神经网络为例,它在60年代统治AI届,80年代也有些存在感,而在2012年卷土重来之前,这一概念濒临灭绝。
每一个10年里,都有不同的技术统领AI研究,华盛顿大学教授、The Master Alogrithm一书作者Pedro Domingos 称,2020年代也不会有什么不同,意味着深度学习的时代可能也很快就要终结。
来源:
http://industry.caijing.com.cn/20190130/4559763.shtml
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



