基于金融-司法领域(兼有闲聊性质)的聊天机器人
Github作者charlexXu86发布了资源:基于金融-司法领域(兼有闲聊性质)的聊天机器人,其中的主要模块有信息抽取、NLU、NLG、知识图谱等,并且利用Django整合了前端展示,目前已经封装了nlp和kg的restful接口。
作者 | charlesXu86
整理 | Xiaowen

https://github.com/charlesXu86/Chatbot_CN
Chatbot_CN (www.chatbotcn.com)
项目介绍(Chatbot_CN)
该项目的目的为实现闲聊的聊天机器人,目前的领域主要针对金融领域
项目共分为七个模块,具体介绍可参照各模块目录下README文件:
Chatbot_CN 存放项目的整理配置文件
Chatbot_Data 存放项目的数据文件以及模型训练文件
Chatbot_Doc 存放项目的参考文献、笔记、收集的资料等文档文件
Chatbot_Model 项目的模型实现
Chatbot_KG 知识图谱实现
Chatbot_Web 页面展示
Chatbot_Rest RESTful接口模块 (Chatbot_Rest/README.md)
Chatbot_RASA rasa模块,包含部分nlu和部分任务型对话。
项目结构图
Chatbot_CN
├───Chatbot_CN 主要存放项目主体的配置文件
│ ├───data (内部实验数据)
│ │ ├───Attention-Based-BiLSTM-relation-extraction
│ │ ├───Info-extra
│ │ ├───lecture_2
│ │ ├───NRE
│ │ ├───pos-tagging
│ │ ├───QA
│ │ └───Relation_extraction
│ ├───example
│ │ ├───Attention-Based-BiLSTM-relation-extraction
│ │ ├───glove
│ │ ├───Info-extra
│ │ ├───lecture_1
│ │ ├───lecture_2
│ │ ├───lecture_3
│ │ ├───lecture_4
│ │ ├───NER
│ │ ├───NLP
│ │ ├───NRE
│ │ ├───POS-tagging
│ │ ├───Relation Extraction
│ │ ├───RL
│ │ ├───Sequence_labeling
│ │ ├───Synonyms
│ │ ├───syntactic
│ │ └───Syntactic_Parsing
│ ├───jieba_dict
│ ├───log
│ ├───QuestionAnswering
│ ├───RuleMatcher
│ ├───task_modules
│ ├───util
│ └───Validation
├───Chatbot_Data 主要存放数据文件及训练好的模型
├───Chatbot_Doc 主要存放一些文档,paper,笔记等文档文件
│ ├───cs224n
│ ├───note
│ ├───paper (paper目录)
│ │ ├───Attention
│ │ ├───Co-reference Resolution
│ │ ├───DeepDive
│ │ ├───Dialogue System
│ │ ├───Distant-Supervision
│ │ ├───Entity Alignment
│ │ ├───Entity Disambiguation
│ │ ├───Entity Linking
│ │ ├───Info-Extra
│ │ │ ├───entity extraction
│ │ │ ├───event extraction
│ │ │ ├───relation extraction
│ │ │ └───terminology extraction
│ │ ├───Intent Detection
│ │ ├───kg 知识图谱
│ │ ├───KG Embeddings
│ │ ├───Knowledge Base Completion
│ │ ├───mulDialogue
│ │ ├───NER
│ │ ├───NLG
│ │ ├───nlp
│ │ ├───NLU
│ │ ├───Pinyin2Chinese
│ │ ├───QA
│ │ ├───Representation-Learning
│ │ ├───RL 强化学习
│ │ ├───RL In Dialogue
│ │ ├───Semantic Parsing
│ │ ├───Semantic Role Labeling
│ │ ├───Sentiment-Analyse
│ │ ├───Seq2Seq
│ │ ├───Shortest Dependency Path
│ │ ├───Slot Filling
│ │ ├───Syntax parsing
│ │ ├───Textual Entailment
│ │ ├───WordRepresentation
│ │ └───因果推断
│ ├───pic
│ ├───小象Chatbot课件
│ └───知识图谱课件
├───Chatbot_KG 知识图谱
├───Chatbot_Model 整个项目的模型实现
└───output
安装教程
1、项目的依赖包请参考Chatbot_CN根目录下的requirement.txt文件。
2、1、导入sql文件到mysql,mysql数据主要作用为项目数据表,如用户注册、登录等。sql脚本文件上传在Chatbot_Data/DATA目录下,运行项目前需要将数据导入到mysql数据库,否则会启动报错
步骤:1、在Chatbot_CN目录下修改settings.py文件里的数据库配置
2、执行sql脚本,将数据导入到本地
3、导入数据到Neo4J,Neo4j为支持知识图谱的图数据库查询,数据也存放在Chatbot_Data/DATA目录下。导入脚本也放在该目录下。
步骤:1、启动图数据库,将数据复制到import目录下
2、导入。图数据库的部分教程以及数据的导入命令,关系查询构建请移步:Chatbot_Doc/图数据库 目录下
3、修改项目中的Neo4j连接。文件位置在:Chatbot_KG/util下,neo_models.py
4、启动图数据库。启动命令为:neo4j.bat console (win环境下)
4、启动mongodb。mongodb可选
5、启动sparql。对项目启动可选
启动项目
启动该项目可以选用两种方式:
1、命令行启动:启动命令为:python manage.py runserver
2、在pycharm里配置,debug运行项目(断点运行),这样方便调试
额外说明
1、由于该项目涉及到前端、后台、深度学习、模型部署等等方面的问题,目前该项目是我一个人开发维护,还有不少前端和后台的问题存在,具体在项目运行中存在的问题,请参见PROBLEM_RESOLVE.md
2、需要注意Linux和window上的区别。
项目架构
項目展示
登錄頁
註冊頁

首页
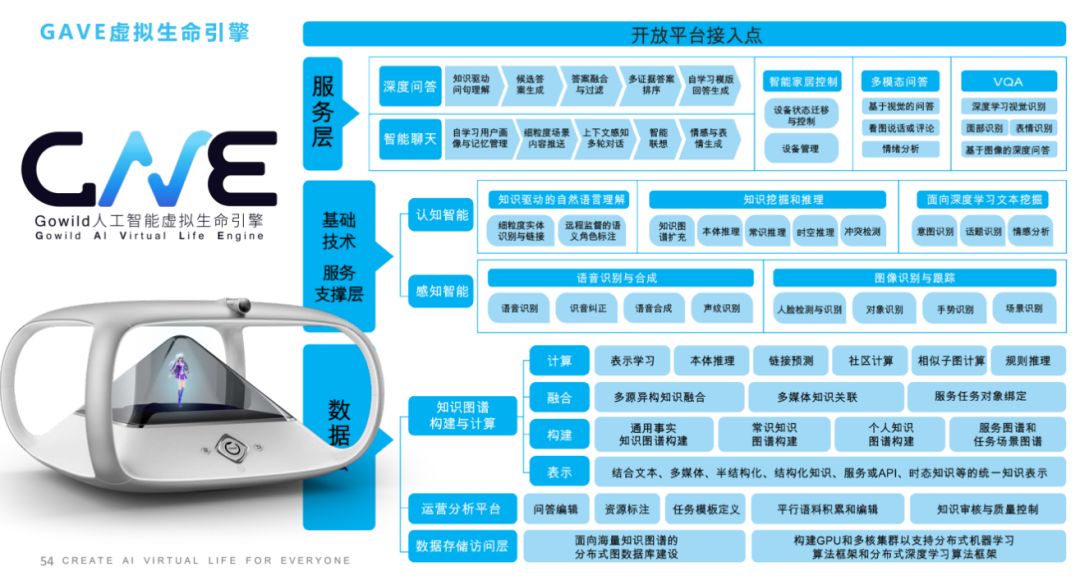
模型(参考图)
SPARQL查询
信息检索
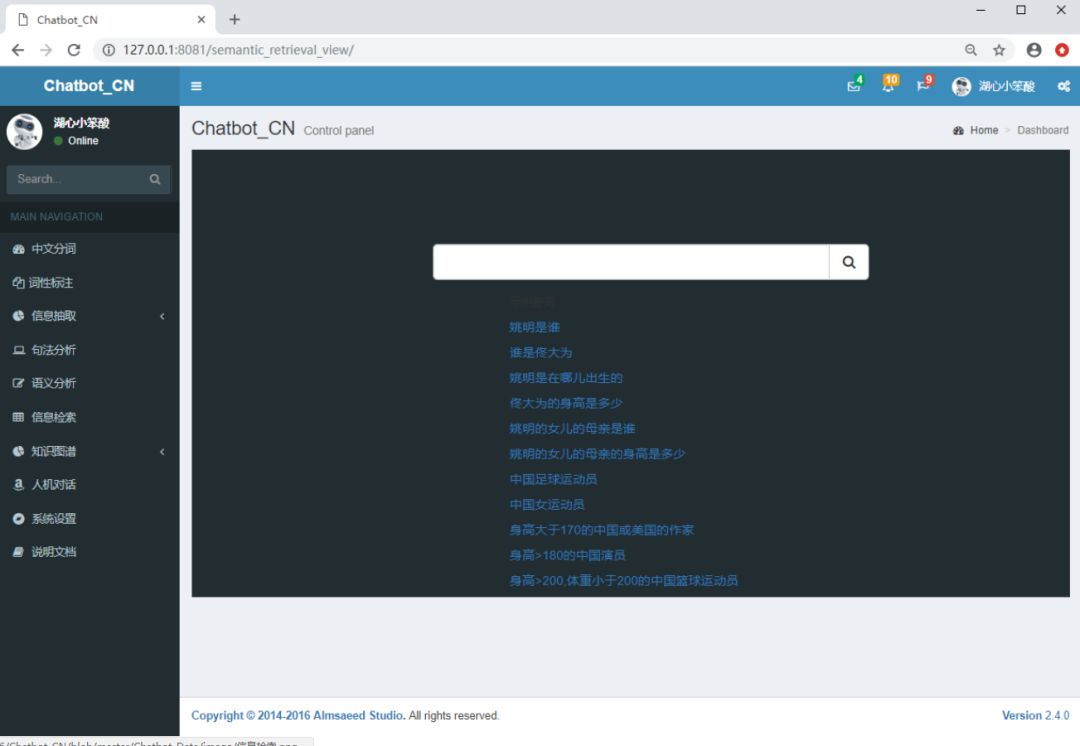
知识图谱模块
关系查询
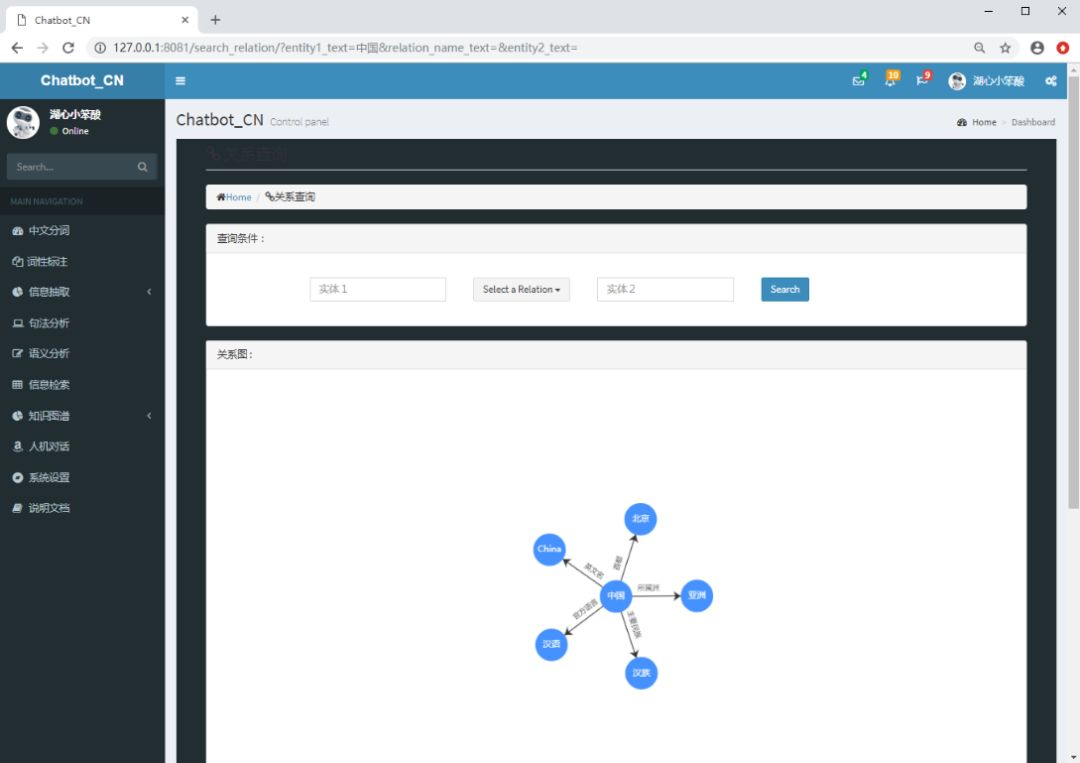
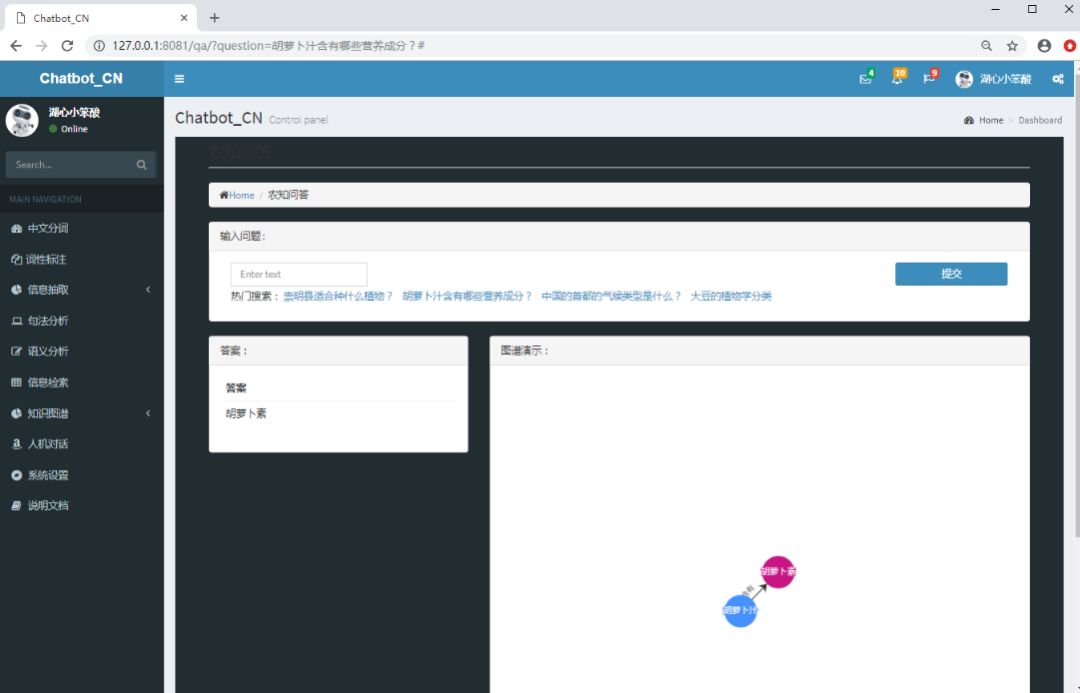
问答
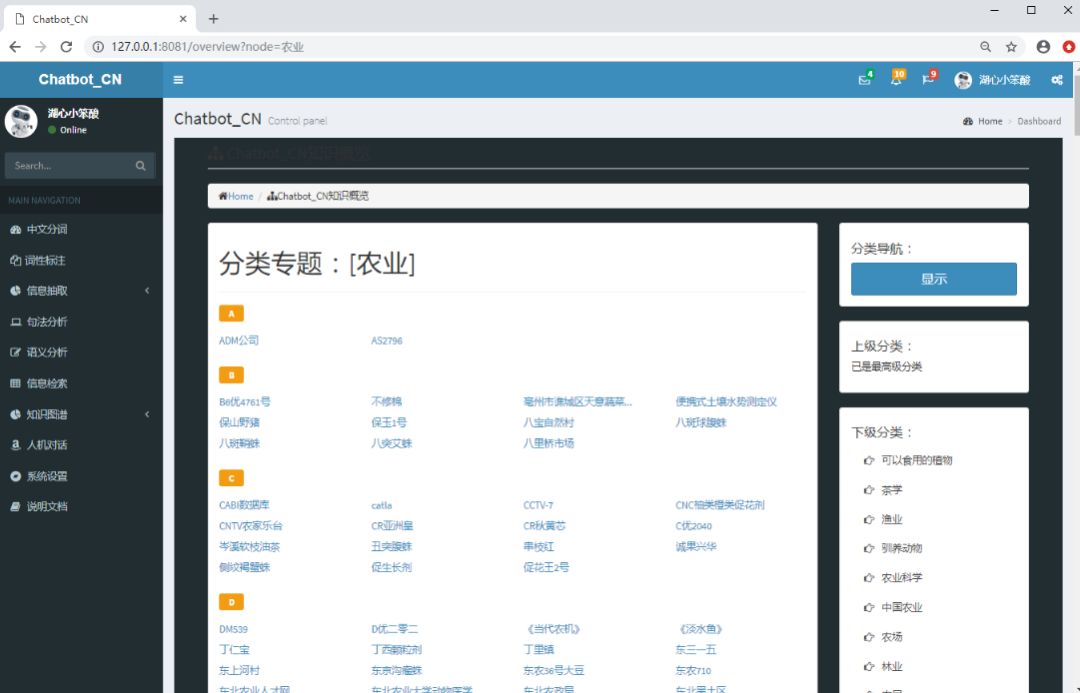
概览
演示
1、闲聊部分
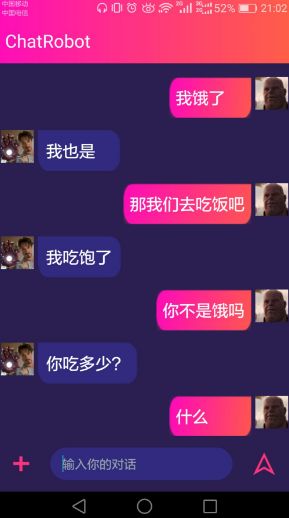

2、任务型
备注
1、各个模块的说明请参考各个模块下的README文件
2、代码会有一些冗余,不是所有代码在Chatbot运行流程中都会用上,有一些代码供学习用
3、目前正在封装接口,这样可以将Chatbot_Model 和 Chatbot_KG模块全部以RESTful api形式对外开放,提供远程调用。-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



