【论文推荐】最新六篇机器翻译相关论文— 自注意力残差解码器、SGNMT、级联方法、神经序列预测、Benchmark、人类水平
【导读】专知内容组整理了最近六篇机器翻译(Machine Translation)相关文章,为大家进行介绍,欢迎查看!
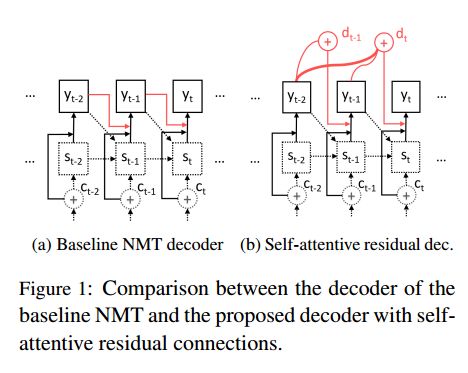
1.Self-Attentive Residual Decoder for Neural Machine Translation(基于自注意力残差解码器的神经机器翻译)
作者:Lesly Miculicich Werlen,Nikolaos Pappas,Dhananjay Ram,Andrei Popescu-Belis
摘要:Neural sequence-to-sequence networks with attention have achieved remarkable performance for machine translation. One of the reasons for their effectiveness is their ability to capture relevant source-side contextual information at each time-step prediction through an attention mechanism. However, the target-side context is solely based on the sequence model which, in practice, is prone to a recency bias and lacks the ability to capture effectively non-sequential dependencies among words. To address this limitation, we propose a target-side-attentive residual recurrent network for decoding, where attention over previous words contributes directly to the prediction of the next word. The residual learning facilitates the flow of information from the distant past and is able to emphasize any of the previously translated words, hence it gains access to a wider context. The proposed model outperforms a neural MT baseline as well as a memory and self-attention network on three language pairs. The analysis of the attention learned by the decoder confirms that it emphasizes a wider context, and that it captures syntactic-like structures.
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/dbc697ffcb43eb2a4b64fc55d86a543f
2.Why not be Versatile? Applications of the SGNMT Decoder for Machine Translation(为什么不是万能的呢?SGNMT解码器在机器翻译中的应用)
作者:Felix Stahlberg,Danielle Saunders,Gonzalo Iglesias,Bill Byrne
机构:University of Cambridge
摘要:SGNMT is a decoding platform for machine translation which allows paring various modern neural models of translation with different kinds of constraints and symbolic models. In this paper, we describe three use cases in which SGNMT is currently playing an active role: (1) teaching as SGNMT is being used for course work and student theses in the MPhil in Machine Learning, Speech and Language Technology at the University of Cambridge, (2) research as most of the research work of the Cambridge MT group is based on SGNMT, and (3) technology transfer as we show how SGNMT is helping to transfer research findings from the laboratory to the industry, eg. into a product of SDL plc.
期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/3e0197f22fd5e19520c2cdae69b4b726
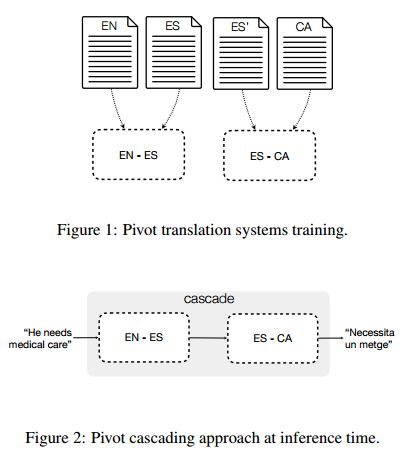
3.English-Catalan Neural Machine Translation in the Biomedical Domain through the cascade approach(在生物医学领域中通过级联方法进行的英语-加泰罗尼亚神经机器翻译)
作者:Marta R. Costa-jussà,Noe Casas,Maite Melero
机构:Universitat Politecnica de Catalunya
摘要:This paper describes the methodology followed to build a neural machine translation system in the biomedical domain for the English-Catalan language pair. This task can be considered a low-resourced task from the point of view of the domain and the language pair. To face this task, this paper reports experiments on a cascade pivot strategy through Spanish for the neural machine translation using the English-Spanish SCIELO and Spanish-Catalan El Peri\'odico database. To test the final performance of the system, we have created a new test data set for English-Catalan in the biomedical domain which is freely available on request.
期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/2fbed977773fddbd8da6233e0824d330
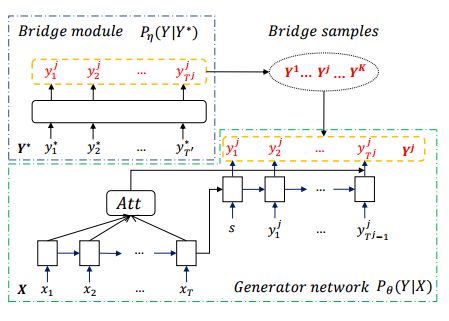
4.Generative Bridging Network in Neural Sequence Prediction(神经序列预测中的生成桥接网络)
作者:Wenhu Chen,Guanlin Li,Shuo Ren,Shujie Liu,Zhirui Zhang,Mu Li,Ming Zhou
机构:University of Science and Technology,Beijing University of Aeronautics and Astronautics,University of California
摘要:In order to alleviate data sparsity and overfitting problems in maximum likelihood estimation (MLE) for sequence prediction tasks, we propose the Generative Bridging Network (GBN), in which a novel bridge module is introduced to assist the training of the sequence prediction model (the generator network). Unlike MLE directly maximizing the conditional likelihood, the bridge extends the point-wise ground truth to a bridge distribution conditioned on it, and the generator is optimized to minimize their KL-divergence. Three different GBNs, namely uniform GBN, language-model GBN and coaching GBN, are proposed to penalize confidence, enhance language smoothness and relieve learning burden. Experiments conducted on two recognized sequence prediction tasks (machine translation and abstractive text summarization) show that our proposed GBNs can yield significant improvements over strong baselines. Furthermore, by analyzing samples drawn from different bridges, expected influences on the generator are verified.
期刊:arXiv, 2018年3月18日
网址:
http://www.zhuanzhi.ai/document/33ef54e6acf3422c70b73e5bfa1c4787
5.TBD: Benchmarking and Analyzing Deep Neural Network Training(TBD: 对深度神经网络训练进行Benchmark分析)
作者:Hongyu Zhu,Mohamed Akrout,Bojian Zheng,Andrew Pelegris,Amar Phanishayee,Bianca Schroeder,Gennady Pekhimenko
机构:University of Toronto,Microsoft Research
摘要:The recent popularity of deep neural networks (DNNs) has generated a lot of research interest in performing DNN-related computation efficiently. However, the primary focus is usually very narrow and limited to (i) inference -- i.e. how to efficiently execute already trained models and (ii) image classification networks as the primary benchmark for evaluation. Our primary goal in this work is to break this myopic view by (i) proposing a new benchmark for DNN training, called TBD (TBD is short for Training Benchmark for DNNs), that uses a representative set of DNN models that cover a wide range of machine learning applications: image classification, machine translation, speech recognition, object detection, adversarial networks, reinforcement learning, and (ii) by performing an extensive performance analysis of training these different applications on three major deep learning frameworks (TensorFlow, MXNet, CNTK) across different hardware configurations (single-GPU, multi-GPU, and multi-machine). TBD currently covers six major application domains and eight different state-of-the-art models. We present a new toolchain for performance analysis for these models that combines the targeted usage of existing performance analysis tools, careful selection of new and existing metrics and methodologies to analyze the results, and utilization of domain specific characteristics of DNN training. We also build a new set of tools for memory profiling in all three major frameworks; much needed tools that can finally shed some light on precisely how much memory is consumed by different data structures (weights, activations, gradients, workspace) in DNN training. By using our tools and methodologies, we make several important observations and recommendations on where the future research and optimization of DNN training should be focused.
期刊:arXiv, 2018年3月16日
网址:
http://www.zhuanzhi.ai/document/505ba67620ace41b240b8d9a310e61be
6.Achieving Human Parity on Automatic Chinese to English News Translation(自动中英文新闻翻译上达到人类水平)
作者:Hany Hassan,Anthony Aue,Chang Chen,Vishal Chowdhary,Jonathan Clark,Christian Federmann,Xuedong Huang,Marcin Junczys-Dowmunt,William Lewis,Mu Li,Shujie Liu,Tie-Yan Liu,Renqian Luo,Arul Menezes,Tao Qin,Frank Seide,Xu Tan,Fei Tian,Lijun Wu,Shuangzhi Wu,Yingce Xia,Dongdong Zhang,Zhirui Zhang,Ming Zhou
摘要:Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
期刊:arXiv, 2018年3月15日
网址:
http://www.zhuanzhi.ai/document/7586f0034a3b659e8c7148e63b02c0c2
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!
展开全文



