【论文推荐】最新六篇图像检索相关论文—多模态反馈、二值约束深度哈希、绘制草图、对话交互式、多目标图像检索
【导读】专知内容组在前天为大家推出六篇图像检索(Image Retrieval)相关论文,今天又推出六篇图像检索相关论文,欢迎查看!
7.Image Retrieval with Mixed Initiative and Multimodal Feedback(具有混合主动和多模态反馈的图像检索)
作者:Nils Murrugarra-Llerena,Adriana Kovashka
In submission to BMVC 2018
机构:University of Pittsburgh
摘要:How would you search for a unique, fashionable shoe that a friend wore and you want to buy, but you didn't take a picture? Existing approaches propose interactive image search as a promising venue. However, they either entrust the user with taking the initiative to provide informative feedback, or give all control to the system which determines informative questions to ask. Instead, we propose a mixed-initiative framework where both the user and system can be active participants, depending on whose initiative will be more beneficial for obtaining high-quality search results. We develop a reinforcement learning approach which dynamically decides which of three interaction opportunities to give to the user: drawing a sketch, providing free-form attribute feedback, or answering attribute-based questions. By allowing these three options, our system optimizes both the informativeness and exploration capabilities allowing faster image retrieval. We outperform three baselines on three datasets and extensive experimental settings.
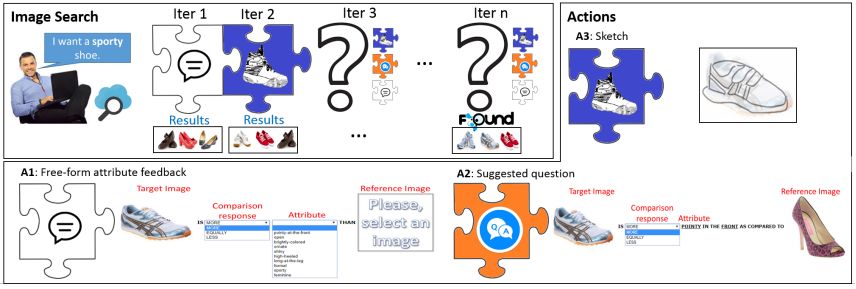
期刊:arXiv, 2018年5月9日
网址:
http://www.zhuanzhi.ai/document/c79d41583c3bde9215ad9db3c6c8bc9d
8.Binary Constrained Deep Hashing Network for Image Retrieval without Human Annotation(基于二值约束深度哈希网络无人工标注的图像检索)
作者:Jia-Hong Huang,Cuong Duc Dao,Modar Alfadly,C. Huck Yang,Bernard Ghanem
摘要:Hashing has attracted increasing research attentions in recent years due to its high efficiency of computation and storage in image retrieval. Recent works have demonstrated the superiority of simultaneous feature representations and hash functions learning with deep neural networks. However, most existing deep hashing methods directly learn the hash functions by encoding the global semantic information, while ignoring the local spatial information of images. The loss of local spatial structure makes the performance bottleneck of hash functions, therefore limiting its application for accurate similarity retrieval. In this work, we propose a novel Deep Ordinal Hashing (DOH) method, which learns ordinal representations by leveraging the ranking structure of feature space from both local and global views. In particular, to effectively build the ranking structure, we propose to learn the rank correlation space by exploiting the local spatial information from Fully Convolutional Network (FCN) and the global semantic information from the Convolutional Neural Network (CNN) simultaneously. More specifically, an effective spatial attention model is designed to capture the local spatial information by selectively learning well-specified locations closely related to target objects. In such hashing framework,the local spatial and global semantic nature of images are captured in an end-to-end ranking-to-hashing manner. Experimental results conducted on three widely-used datasets demonstrate that the proposed DOH method significantly outperforms the state-of-the-art hashing methods.
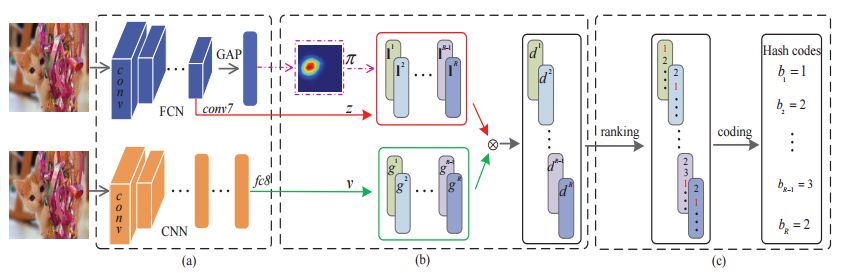
期刊:arXiv, 2018年5月7日
网址:
http://www.zhuanzhi.ai/document/aa1bcf03d3c4b18113c047620a6a8d97
9.Learning to Sketch with Shortcut Cycle Consistency(学习用快捷的循环一致性来绘制草图)
作者:Jifei Song,Kaiyue Pang,Yi-Zhe Song,Tao Xiang,Timothy Hospedales
To appear in CVPR2018
机构:Queen Mary University of London,The University of Edinburgh
摘要:Visual Question Answering (VQA) models should have both high robustness and accuracy. Unfortunately, most of the current VQA research only focuses on accuracy because there is a lack of proper methods to measure the robustness of VQA models. There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the ranked basic questions, with similarity scores, of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question about the given image. We claim that a robust VQA model is one, whose performance is not changed much when related basic questions as also made available to it as input. We formulate the basic questions generation problem as a LASSO optimization, and also propose a large scale Basic Question Dataset (BQD) and Rscore (novel robustness measure), for analyzing the robustness of VQA models. We hope our BQD will be used as a benchmark for to evaluate the robustness of VQA models, so as to help the community build more robust and accurate VQA models.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/c7d5aa78a6f8b15ec2d46b2a13a06667
10.Dialog-based Interactive Image Retrieval(基于对话交互式的图像检索)
作者:Xiaoxiao Guo,Hui Wu,Yu Cheng,Steven Rennie,Rogerio Schmidt Feris
机构:IBM Research AI
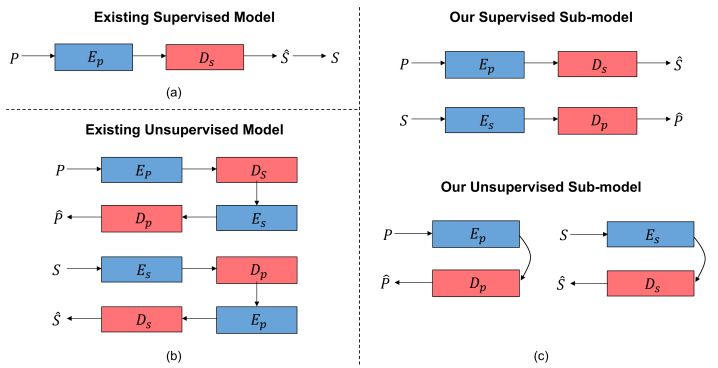
摘要:Existing methods for interactive image retrieval have demonstrated the merit of integrating user feedback, improving retrieval results. However, most current systems rely on restricted forms of user feedback, such as binary relevance responses, or feedback based on a fixed set of relative attributes, which limits their impact. In this paper, we introduce a new approach to interactive image search that enables users to provide feedback via natural language, allowing for more natural and effective interaction. We formulate the task of dialog-based interactive image retrieval as a reinforcement learning problem, and reward the dialog system for improving the rank of the target image during each dialog turn. To avoid the cumbersome and costly process of collecting human-machine conversations as the dialog system learns, we train our system with a user simulator, which is itself trained to describe the differences between target and candidate images. The efficacy of our approach is demonstrated in a footwear retrieval application. Extensive experiments on both simulated and real-world data show that 1) our proposed learning framework achieves better accuracy than other supervised and reinforcement learning baselines and 2) user feedback based on natural language rather than pre-specified attributes leads to more effective retrieval results, and a more natural and expressive communication interface.

期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/5de1b38af24a1fcf603a247382bd6662
11.How convolutional neural network see the world - A survey of convolutional neural network visualization methods(卷积神经网络如何看待世界——卷积神经网络可视化方法的研究)
作者:Zhuwei Qin,Funxun Yu,Chenchen Liu,Xiang Chen
机构:George Mason University,Clarkson University
摘要:Nowadays, the Convolutional Neural Networks (CNNs) have achieved impressive performance on many computer vision related tasks, such as object detection, image recognition, image retrieval, etc. These achievements benefit from the CNNs outstanding capability to learn the input features with deep layers of neuron structures and iterative training process. However, these learned features are hard to identify and interpret from a human vision perspective, causing a lack of understanding of the CNNs internal working mechanism. To improve the CNN interpretability, the CNN visualization is well utilized as a qualitative analysis method, which translates the internal features into visually perceptible patterns. And many CNN visualization works have been proposed in the literature to interpret the CNN in perspectives of network structure, operation, and semantic concept. In this paper, we expect to provide a comprehensive survey of several representative CNN visualization methods, including Activation Maximization, Network Inversion, Deconvolutional Neural Networks (DeconvNet), and Network Dissection based visualization. These methods are presented in terms of motivations, algorithms, and experiment results. Based on these visualization methods, we also discuss their practical applications to demonstrate the significance of the CNN interpretability in areas of network design, optimization, security enhancement, etc.
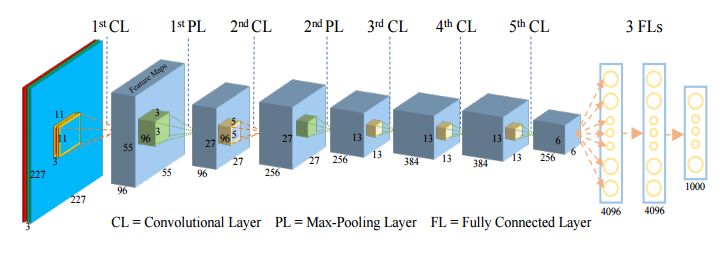
期刊:arXiv, 2018年4月30日
网址:
http://www.zhuanzhi.ai/document/3c3e20e263ed4cf213e392c8684d40ea
12.Learning Cross-Modal Deep Embeddings for Multi-Object Image Retrieval using Text and Sketch(学习利用文本和草图进行多目标图像检索的交叉模态深度嵌入)
作者:Sounak Dey,Anjan Dutta,Suman K. Ghosh,Ernest Valveny,Josep Lladós,Umapada Pal
Accepted at ICPR 2018
机构:Autonomous University of Barcelona
摘要:In this work we introduce a cross modal image retrieval system that allows both text and sketch as input modalities for the query. A cross-modal deep network architecture is formulated to jointly model the sketch and text input modalities as well as the the image output modality, learning a common embedding between text and images and between sketches and images. In addition, an attention model is used to selectively focus the attention on the different objects of the image, allowing for retrieval with multiple objects in the query. Experiments show that the proposed method performs the best in both single and multiple object image retrieval in standard datasets.
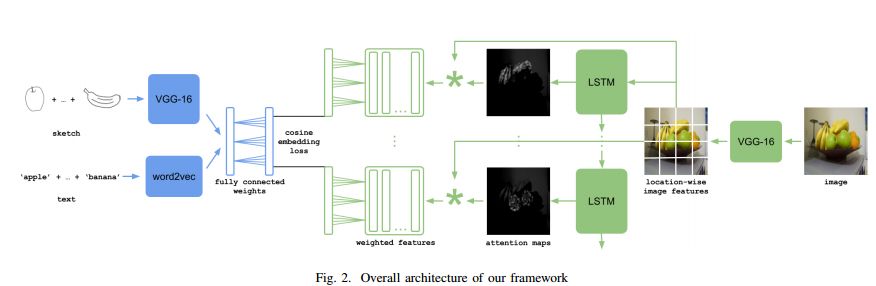
期刊:arXiv, 2018年4月28日
网址:
http://www.zhuanzhi.ai/document/2e530ebc26c287c95c17e2d01ce8f1a5
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



