【论文推荐】最新五篇强化学习相关论文—轮廓绘制、连贯摘要提取方法、对话系统、不完全信息、多奖励强化摘要
【导读】既前两天推出13篇强化学习(Reinforcement Learning)相关文章,专知内容组今天又推出最近5篇强化学习相关文章,为大家进行介绍,欢迎查看!
1. Outline Objects using Deep Reinforcement Learning(基于深度强化学习的轮廓绘制)
作者:Zhenxin Wang,Sayan Sarcar,Jingxin Liu,Yilin Zheng,Xiangshi Ren
机构:Kochi University of Technology
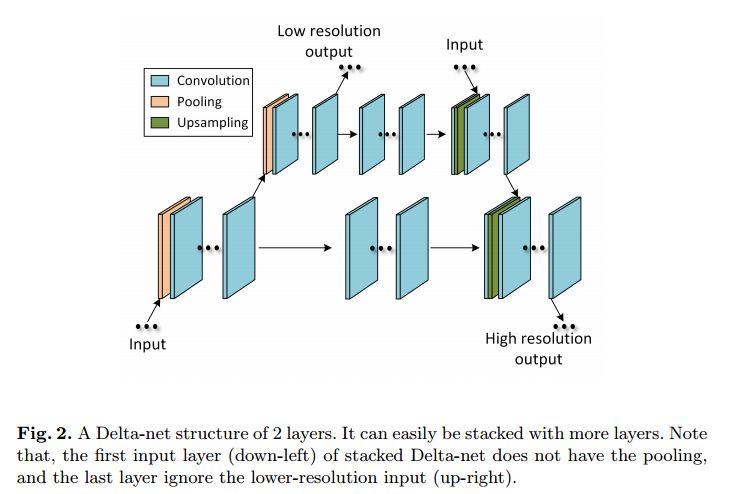
摘要:Image segmentation needs both local boundary position information and global object context information. The performance of the recent state-of-the-art method, fully convolutional networks, reaches a bottleneck due to the neural network limit after balancing between the two types of information simultaneously in an end-to-end training style. To overcome this problem, we divide the semantic image segmentation into temporal subtasks. First, we find a possible pixel position of some object boundary; then trace the boundary at steps within a limited length until the whole object is outlined. We present the first deep reinforcement learning approach to semantic image segmentation, called DeepOutline, which outperforms other algorithms in Coco detection leaderboard in the middle and large size person category in Coco val2017 dataset. Meanwhile, it provides an insight into a divide and conquer way by reinforcement learning on computer vision problems.
期刊:arXiv, 2018年4月20日
网址:
http://www.zhuanzhi.ai/document/114dcff0793e11915d59d9467a43713c
2. Learning to Extract Coherent Summary via Deep Reinforcement Learning(基于深度强化学习的连贯摘要提取方法)
作者:Yuxiang Wu,Baotian Hu
机构:Hong Kong University of Science and Technology,University of Massachusetts Medical School
摘要:Coherence plays a critical role in producing a high-quality summary from a document. In recent years, neural extractive summarization is becoming increasingly attractive. However, most of them ignore the coherence of summaries when extracting sentences. As an effort towards extracting coherent summaries, we propose a neural coherence model to capture the cross-sentence semantic and syntactic coherence patterns. The proposed neural coherence model obviates the need for feature engineering and can be trained in an end-to-end fashion using unlabeled data. Empirical results show that the proposed neural coherence model can efficiently capture the cross-sentence coherence patterns. Using the combined output of the neural coherence model and ROUGE package as the reward, we design a reinforcement learning method to train a proposed neural extractive summarizer which is named Reinforced Neural Extractive Summarization (RNES) model. The RNES model learns to optimize coherence and informative importance of the summary simultaneously. Experimental results show that the proposed RNES outperforms existing baselines and achieves state-of-the-art performance in term of ROUGE on CNN/Daily Mail dataset. The qualitative evaluation indicates that summaries produced by RNES are more coherent and readable.

期刊:arXiv, 2018年4月19日
网址:
http://www.zhuanzhi.ai/document/88185cdcf2f50ff31dc0a8f5c060e4d8
3. Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems(端到端可训练的面向任务的对话系统中的人性化教学与反馈对话学习)
作者:Bing Liu,Gokhan Tur,Dilek Hakkani-Tur,Pararth Shah,Larry Heck
机构:Carnegie Mellon University
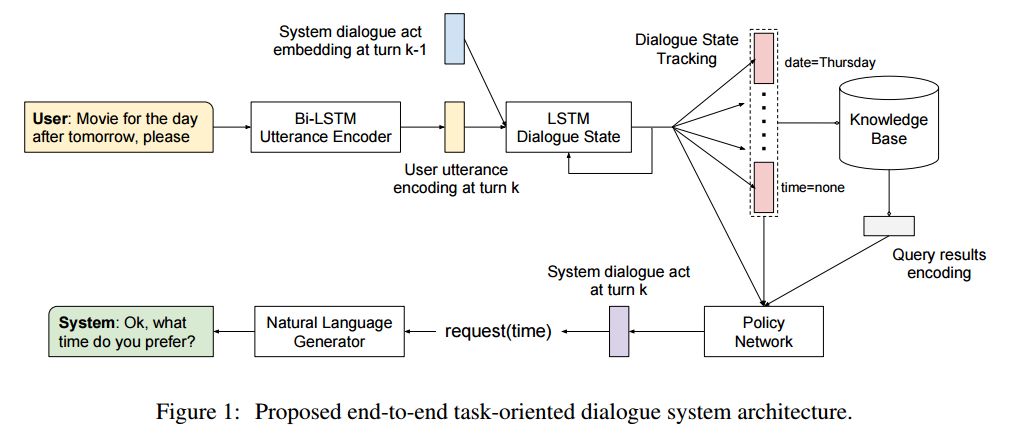
摘要:In this work, we present a hybrid learning method for training task-oriented dialogue systems through online user interactions. Popular methods for learning task-oriented dialogues include applying reinforcement learning with user feedback on supervised pre-training models. Efficiency of such learning method may suffer from the mismatch of dialogue state distribution between offline training and online interactive learning stages. To address this challenge, we propose a hybrid imitation and reinforcement learning method, with which a dialogue agent can effectively learn from its interaction with users by learning from human teaching and feedback. We design a neural network based task-oriented dialogue agent that can be optimized end-to-end with the proposed learning method. Experimental results show that our end-to-end dialogue agent can learn effectively from the mistake it makes via imitation learning from user teaching. Applying reinforcement learning with user feedback after the imitation learning stage further improves the agent's capability in successfully completing a task.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/cc8dcf0d2eab20a460a5508761289267
4. Sim-to-Real Optimization of Complex Real World Mobile Network with Imperfect Information via Deep Reinforcement Learning from Self-play(基于深度强化学习的不完全信息复杂现实移动网络的sim-to-real优化)
作者:Yongxi Tan,Jin Yang,Xin Chen,Qitao Song,Yunjun Chen,Zhangxiang Ye,Zhenqiang Su
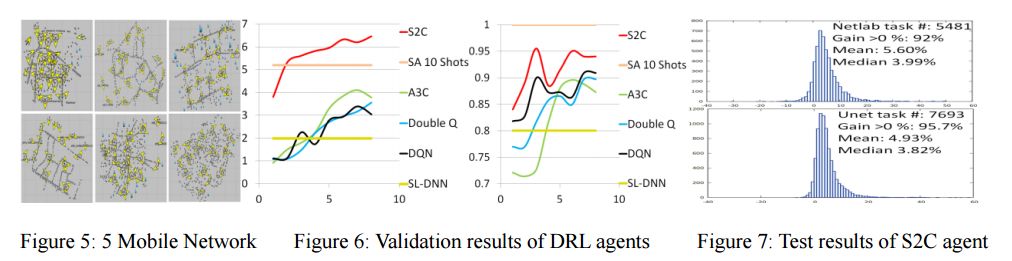
摘要:Mobile network that millions of people use every day is one of the most complex systems in real world. Optimization of mobile network to meet exploding customer demand and reduce CAPEX/OPEX poses greater challenges than in prior works. Actually, learning to solve complex problems in real world to benefit everyone and make the world better has long been ultimate goal of AI. However, application of deep reinforcement learning (DRL) to complex problems in real world still remains unsolved, due to imperfect information, data scarcity and complex rules in real world, potential negative impact to real world, etc. To bridge this reality gap, we propose a sim-to-real framework to direct transfer learning from simulation to real world without any training in real world. First, we distill temporal-spatial relationships between cells and mobile users to scalable 3D image-like tensor to best characterize partially observed mobile network. Second, inspired by AlphaGo, we introduce a novel self-play mechanism to empower DRL agents to gradually improve intelligence by competing for best record on multiple tasks, just like athletes compete for world record in decathlon. Third, a decentralized DRL method is proposed to coordinate multi-agents to compete and cooperate as a team to maximize global reward and minimize potential negative impact. Using 7693 unseen test tasks over 160 unseen mobile networks in another simulator as well as 6 field trials on 4 commercial mobile networks in real world, we demonstrate the capability of this sim-to-real framework to direct transfer the learning not only from one simulator to another simulator, but also from simulation to real world. This is the first time that a DRL agent successfully transfers its learning directly from simulation to very complex real world problems with imperfect information, complex rules, huge state/action space, and multi-agent interactions.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/605e27ee67d1454083c6b5acbb759de4
5. Multi-Reward Reinforced Summarization with Saliency and Entailment(具有显著性和蕴涵性的多奖励强化摘要)
作者:Ramakanth Pasunuru,Mohit Bansal
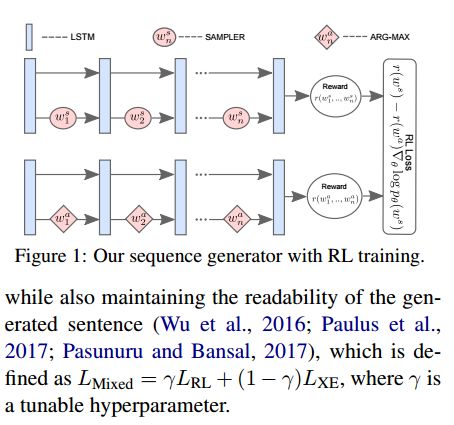
摘要:Abstractive text summarization is the task of compressing and rewriting a long document into a short summary while maintaining saliency, directed logical entailment, and non-redundancy. In this work, we address these three important aspects of a good summary via a reinforcement learning approach with two novel reward functions: ROUGESal and Entail, on top of a coverage-based baseline. The ROUGESal reward modifies the ROUGE metric by up-weighting the salient phrases/words detected via a keyphrase classifier. The Entail reward gives high (length-normalized) scores to logically-entailed summaries using an entailment classifier. Further, we show superior performance improvement when these rewards are combined with traditional metric (ROUGE) based rewards, via our novel and effective multi-reward approach of optimizing multiple rewards simultaneously in alternate mini-batches. Our method achieves the new state-of-the-art results on CNN/Daily Mail dataset as well as strong improvements in a test-only transfer setup on DUC-2002.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/4ea8d8ff424cc44911fbff332a211f7d
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



