双人协作游戏带你理解变分自编码器-Part1
【导读】本文是AI研究员Max Frenzel的一篇技术博客,专门介绍变分自编码器。目标并不是给读者提供实际实现VAE的技术理解,也不是对该领域中最新研究发表评论,而是从一个独特的角度——双人协作游戏,使读者能够容易的理解变分自编码器。这是一个系列文章,本文是Part 1,主要介绍多人协作游戏模拟自编码器的最简单情况,将在Part 2、Part 3继续介绍简单的情况遇到的问题及其他更加复杂的情况。
编译 | 专知
参与 | Yingying, Xiaowen

声明:本系列文章的目的是使变分自编码器的基本思想和自然语言的编码尽可能的易于理解,并鼓励已经熟悉它们的人从新的角度看待它们。为了更好的叙述,也许有时候牺牲一些技术的准确性。我希望读者在没有任何技术背景的情况下,能有趣味地进行学习。
Meet Alice and Bob (and Charlie)
人工智能领域,尤其是深度学习的子领域,在过去几年里一直在飞速发展。其中,生成模型发挥着至关重要的作用。
关于为什么生成模型在通往真正的人工智能的道路上是有用的,其中一个重要的论据是,生成真实数据的系统必须至少具有一定的真实世界的知识。
生成模型有不同的变种。其中之一就是所谓的变分自编码器(VAE)[1],由Diederik Kingma和Max Welling在2013年首次引入。
VAEs有许多实际的应用程序,而且还有很多正在不断地被发现。
它们可以用来压缩数据,或者重构噪声或损坏的数据。它们允许我们在真实数据之间进行平滑的插值,例如,给一张脸拍一张照片,然后慢慢地把它变成另一张脸。它们允许复杂的数据处理,例如,改变一个人的头发长度,或者平稳地改变一个声音从男性到女性变化,而不改变任何其他的声音特征。
更微妙的是,它们更擅长从大量未标记的数据中发现隐藏的概念和关系。这就把它们归于非监督学习算法的类别中(需要标记数据的是监督算法)。
还有一组相关模型遵循与VAE非常相似的原则。例如,用于谷歌翻译的模型就是其中之一。如果你理解了这一系列文章,那么你基本上也可以理解谷歌翻译的原理。
有很多很棒的博客文章,在技术细节和代码解释其如何工作(例如,[2]和[3])。
我的目标不是给你提供实际实现VAE的技术理解,也不是对该领域中最新研究发表评论。
相反,我想提供一种新的方式来理解VAE实际上在做什么。我希望通过一种简单的方法来向没有太多背景知识的人(老奶奶或小学生)解释,同时不至于遗漏太多细节。
即使你是一个有经验的专业人士或研究人员,我希望这个稍微古怪的解释可能会激发一些新的创造性见解。
在这三部分的系列中,我们首先要探讨的是自编码器的基础。下次我们将在part 2中讨论为什么使它们变分是有意义的(以及这意味着什么)。最后,在接下来的part3中,我们将会发现为什么编码文本更具有挑战性。Part 1和part2实际上只是part 3的一部分。
自编码器的基本概念的博文已经很多了,从简单的介绍一直到学术论文。然而,对于Part3的概念,我到目前为止还没有遇到任何好的非学术讨论。我希望这个系列能够填补这个空白。
本文的作者是一个量子物理学家,量子物理学家和信息理论家都喜欢通过把复杂的场景简化成简单的游戏来理解和解释这个世界。例如,许多加密问题可以作为发送方和接收方之间的游戏,而恶意玩家则充当窃听者。我已经把自己的研究重心从物理学转向了人工智能,我花了很多时间思考和研究VAEs。考虑到我的量子背景,将VAE作为游戏来解释是很自然的。特别是,我认为VAE是一个双人合作游戏(two-player cooperative game)。
在进入游戏的细节之前,让我们先介绍一下玩家:Alice作为编码器,Bob作为解码器。Alice和Bob很有抱负。他们的目标是在新成立的自编码奥运会上进行竞争,在那里,世界上最好的编码器和解码器会展示他们的技能。 为了准备比赛,Alice和Bob邀请了他们的朋友Charlie,他将评判我们两位选手的表演,并作为他们的教练。现在让我们来看看游戏规则。
自编码游戏(The Autoencoding Game)
正如我们将看到的,游戏有各种各样的风格和规则,每个都有自己的规则和目标。我们将首先考虑游戏的最简单情况,所有的后续版本都将构建这个简单的情况。在深度学习中,这个简单的版本对应于一个正常的(即非变分的)自编码器。基本的想法是:Alice获取一些数据,例如图像,文本,音频剪辑等,然后她必须将这些信息传递给Bob, Bob无法查看数据,这样他就可以重建Alice所看到或听到的内容。Charlie (他爱丽丝看到了什么)然后评估鲍勃的重建是否准确,并根据他的表现给他打分。
目的是为了让Alice和Bob获得尽可能高的分数,即Bob可以完美地复制Alice所得到的数据。问题是,Alice和Bob彼此分离,只能通过一组特殊的设备以非常有限的方式进行通信。特别是爱丽丝不能直接解释她所看到的。她能传递给鲍勃的唯一信息是一堆数字,一个“代码”。
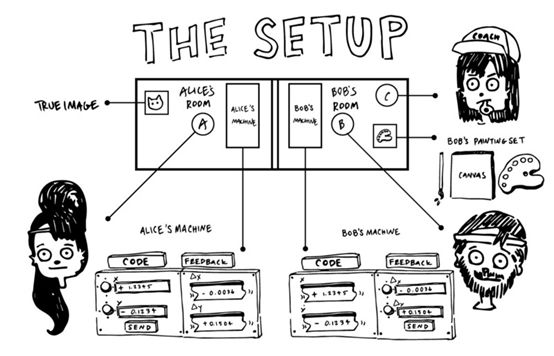
Alice需要编码这些数据。她可以发送多少个数字被称为“代码维度”或“代码大小”。在真实的VAEs中,代码维度通常是数百个。但是为了简单和方便的可视化,让我们假设它仅仅是两个。这不仅是为了这个游戏的简化,当人们想要可视化代码时也是这样假设的。如果代码大小为2,我们可以直接将代码作为一个二维坐标系中(x, y)。
对于这个游戏的初始版本,我们还会假设Alice所显示的数据是猫和狗的照片。有很多这样的数据,我们称之为训练数据。为了简单起见,我们假设有100万个训练图像。对于现实数据集来说,这是一个相当平均的数字。
一些典型的例子如图:

因此,给定其中一个图像,Alice必须将两个数字输入到她的机器中,比如(2.846,-5.049),并将此代码发送给Bob。鲍勃现在必须试着画出他认为Alice看到的东西。
这听起来是很难的!
实际上是非常非常难!
我们都知道狗和猫是什么,它们是什么样子,它们的行为,我们通常在什么环境下看到它们,等等。但人工智能必须从头开始,没有对真实世界的预想,也不可能有什么图像。就好像Bob和Alice都是在一个封闭的房间里长大的,他们闭着眼睛,第一次看到真实的世界,通过照片展示出来。他们绝对没有“狗”或“猫”的概念,在游戏开始的时候,猫的照片看起来很有可能像随机噪声或抽象画一样。

他们甚至没有被告知照片中包含的大部分是我们称之为“猫”和“狗”的东西。困难甚至还没有结束。当Alice看到真实的照片时,Bob从来没有看到过真实的照片。他所看到的只是来自Alice的代码。他只能根据这些神秘的数字做出随机的画。但这正是我们的教练Charlie的重要性。每次Bob根据Alice的一个代码完成一幅画时,Charlie将其与原始码进行比较,并给它分配一个分数(这个分数的技术术语是“损失函数”)。越准确,得分越高。

不仅仅是提供一个分数来告诉Bob他有多好(或坏),Charlie还告诉他他的哪个决定有助于这一点,以及如何做出贡献。在技术方面,他为Bob提供了“梯度”。基于这些信息,Bob可以调整他的程序,以便下次获得更高的分数。因为Bob知道Alice的代码是如何影响他的进程和最终输出的,他还可以告诉Alice如何提高编码。为了在这个特殊的案例中获得更高的分数,他希望得到什么样的代码。例如,他可以认为“1号应该更小,2号应该是4.956”。
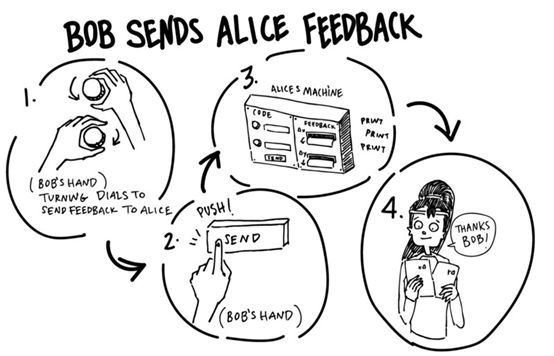
这是Bob对Alice唯一允许的通信。我们把这个过程称为“反向传播”,因为我们从最后的分数开始,然后向后工作,根据反馈调整导致分数的过程。 这种反向传播的方法目前构成了训练大多数深层神经网络的基础,而不仅仅在VAEs或生成模型中使用。
在调整过程的同时,Alice和Bob需要小心,不要在一张照片的基础上调整太多。如果他们这样做了,他们只会在之前的印象中变得更好,然后“改写”这一进步,因为他们会过度调整到下一个。相反,他们需要在每个反馈的基础上对他们的流程进行小的更新,并希望随着时间的推移,这些小的调整将会使他们在所有的图像上都有一个好的分数,而不仅仅是当前的。他们根据每个图像的反馈调整他们的过程,这取决于所谓的学习速率。学习率越高,他们调整过程的速度就越快。但如果学习率过高,他们就有可能对每一幅新图像进行过度补偿。
起初,由于Alice从未见过真正的照片,也不知道Bob会喜欢什么代码,所以她所能做的就是发送给Bob随机数。而且,Bob不知道这些数字意味着什么,也不知道他预计会创作什么样的画作。从字面上看,任何一幅画都和其他画一样,是随机的。但是在创作了许多随机的画作之后,Bob开始注意到一些东西。当他在他的绘画中心使用某些颜色,而其他一些在边缘的时候,他的分数会稍微高一些。特别是当他在中间画一个灰色或棕色的圆圈时,他通常会得到比他完全随机画出的更高的平均分。

Bob,没有“皮毛”或“眼睛”的概念,只是发现大多数图片都包含有皮毛的动物,通常有两只眼睛。记住这个。在Part 3中,当Alice和Bob试图对文本进行编码时,可能出现的重大进展将会再次困扰Alice和Bob。
同样,这种完全忽略Alice输入的方法,只画一个带有两个圆的棕色斑点。使他被卡住了,不能提高分数。他需要开始尝试使用Alice的代码,因为Alice没有从Bob那里得到任何有用的反馈,所以在这一点上仍然是随机的。他需要开始将这些代码融入到他的创作过程中,并给Alice一些线索来引导她的编码方向正确。接下来的过程是Alice和Bob的共同努力。Bob首先了解什么是真实的或可能的图像,而Alice在Bob的反馈的帮助下,可以引导他向正确的方向输入一个给定的输入。如果没有Bob对世界的了解,比如在游戏的开始,她就必须为他指定图像的每一个像素。后来,她可以用更少的信息(猫或狗?棕色或灰色?坐着,站着,还是跑步?等等)。
作为数据压缩的一小部分,让我们考虑一个简单的游戏版本。在这个版本中,代码维度与图像像素的数量完全相同。
有了像图像有像素一样多的输入插槽的机器,Alice可以简单地通过机器传输精确的图像。(假设它是黑白的。对于彩色照片,我们实际上需要3倍的像素,来为每个像素编码红色、绿色和蓝色的值。Bob只需把每一个像素都画出来,就像Alice教给他的一样,并且可以100%地得到完美的复制品。
稍微不那么简单的版本是代码大小为像素的一半。Alice现在可以学习指定每一个像素,一个向下采样的照片。Bob只需要填充剩下的像素。假设他对真实世界的样子有一个很好的概念,这就变成了一个相当琐碎的任务。这些图像并不都是100%准确的,但是足够接近。
但是Alice和Bob永远都无法摆脱这种“像素编码”。随着代码规模的缩小,比如在我们最初的游戏中,如果他们想要获得成功,他们必须改变策略。
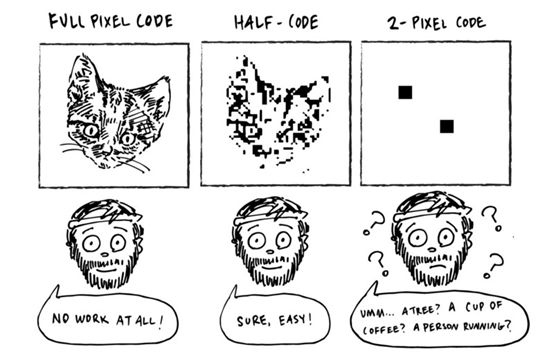
他们不需要编码像素,而是需要一个更智能、更“信息密集”的代码。一种能捕捉更多抽象概念的代码,比如什么动物,什么姿势,什么摄像机角度等等。这是数据压缩的基础。我们越想压缩一个数据,我们需要设计的代码就越高效(而且我们冒的风险越高,它就越不会完全被重建)。诀窍是将复杂的信息分解为一些简单的、普遍的概念,但仍然允许相当忠实的重构。
回到我们最初的游戏,Alice和Bob已经玩了一段时间(我的意思是很长一段时间),并且在训练数据集上玩了大约十次的游戏。Bob已经成为一个多产的画家,画了几百万幅画,而Alice已经成为了一个专业的信息编码器,并学会了为Bob提供代码,帮助他弄清楚她看到的是什么照片。
与原始的随机性相比,Bob对现实世界的想法有了显著的改善。

然而,注意Alice和Bob只知道他们在训练图像中遇到的事情。另一种动物对于他们几乎和随机噪声一样。Alice和Bob在比赛中表现得相当出色,并且开始得分相当高。
学习的编码(The Learned Code)
让我们简单地看一下Alice在训练中可能发现的代码。由于代码由两个数字组成,我们可以很容易地将它们可视化为平面上的x和y坐标。在一种可能的代码中,Alice可以决定用一个负值来表示猫的值,而对狗来说则是正数。y轴可以用来做皮毛颜色。正的值更黑,负的更亮。
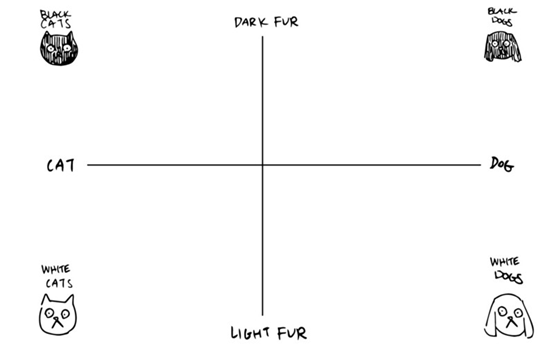
用这段代码,如果Alice得到一张非常“狗狗”的照片,她会给Bob发送两个大的正数。如果她看到一只非常“猫”的白猫,她就会发出两个大的负数。对于一张照片,她几乎不确定它是一只狗还是一只猫,而毛皮的颜色是中等的黑暗,她将发送两个接近零的值。
如果Bob了解到这是Alice正在使用的编码,它将允许他更好地猜测他的绘画。然而,他的新画虽然比完全随机的画有了很大的改进,但仍然包含了大量的随机性和猜测性。他知道它是猫还是狗,皮毛有多深,但有很多信息,这种特殊的编码不能传播。例如,Bob不知道皮毛的长度和图案是什么,动物在什么姿势,在什么部位,背景是什么,场景的灯光是什么,……他需要更多的信息来充分说明问题。这就是为什么真正的神经网络往往会学习非常复杂的代码,在大多数情况下,人类对坐标轴的解释并不容易。这样他们就可以把更多的信息塞进这两个数字里。如果你仔细想想,在一个简单的图像中有很多信息。如果你被要求寻找猫或狗,你会以一种特别的方式来观察图像,非常的二元化:猫或狗?如果你在另一只手上问猫狗是在城市还是在自然环境中,你会对这些图像有不同的看法。Alice和Bob没有被要求去寻找任何具体的东西。他们没有这样的背景。他们只知道重建整个图像的任务。然而,当他们学习的时候,他们可能会自然而然地想出“狗”和“猫”这样的概念。但是,人工智能也有很大的机会提出对我们人类毫无意义的概念。概念更加抽象和高效。因此,如果Alice和Bob玩的时间足够长,他们最终会在这些更复杂的代码中达成一致,从而捕获高度抽象和高效的概念。
似乎他们已经掌握了游戏规则,对吧?
如果Alice和Bob太"聪明"怎么办?
在Charlie的帮助下,Alice和Bob正在为自编码奥运会进行训练。在训练过程中,他们一次又一次地练习同一组照片。但是,奥运会上使用的这些照片是保密的。他们不会看到,直到他们在比赛时间真正开始做。在这一点上,他们可能会意识到自己遇到了麻烦。他们没有理解“狗和猫照片的一般世界”,而是学会了在训练集中完全记住所有的照片。事实上,他们并没有发现我们讨论过的任何概念。他们基本上只是想出了一个作弊的方法,在他们的训练图像上获得一个完美的分数,而实际上并没有真正的理解。

这个问题在所有深度学习中非常普遍,被称为过度拟合。就像一个学生把考试的答案偷走,然后记住这些答案,而不是真正的掌握知识,Alice和Bob,一旦过拟合,对他们遇到的例子100%的自信,但对其他的事情完全没有头绪。采取这种极端,如果Alice和Bob很“聪明”,有大内存,并允许训练很长一段时间,他们可以学会对任何图像进行完美的编码,不管有多少图片。
他们如何做到这一点呢?有无数的代码可以让他们这样做,我们来考虑一个特别简单的方法。我们之前假设有100万个训练图像。考虑到这些知识,他们可能会同意从第一个0.000001开始编码,第一个0.000002,第100万的编码是1.000000。对于每个图像,它们只是决定一个唯一的代码编号。在这段代码中,连续编号的图像与它们的代码非常接近,但是图像至少不需要相似。图156可能是一只在客厅玩球的黑狗,图像157可能是一只白色的猫在草地上追逐老鼠。每当Alice看到图像156,她就发送0.000156。Bob已经知道了他需要什么才能得到一个完美的分数。同样的,当他在他的机器上看到0.000157的时候,他已经弄清楚了要画什么。这样,他们就得到一个完美的分数。但如果Bob看到0.0001565? 或-0.000001 ? 或1.000001 ? 他就不知道了。类似地,如果Alice突然出现了一个以前从未遇到过的新图像,那么她将如何将其与现有的代码相匹配,从而使Bob可以直接进行猜测呢?
再一次,不知道怎么办了。
这不是学习或理解,这是纯粹的记忆。
每一个微小的变化,每一个微小的不熟悉,他们完全不知所措了。
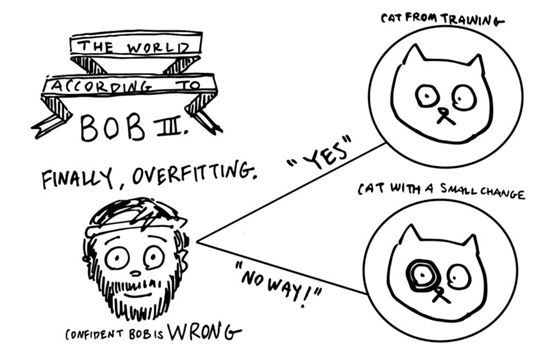
我们需要阻止他们进入这个阶段,而不是加强理解。如果做得正确,他们可能还会在一定程度上记住以前遇到过的例子,但也学会了一些基本原理,让他们能够推理出以前没见过的东西。这叫做泛化,是几乎任何深度学习算法的核心技术之一。防止这个问题的一种方法,是在基本的理解被遗忘之前,及时停止训练。但是在自编码器的情况下,有一种更好的方法来确保实际的理解和有意义的代码。
下次,我们将介绍Part 2,我们将讨论Alice和Bob如何处理他们的这种失败,并了解一种新的训练方法,使用所谓的变分机器,可以帮助他们提高性能,并提出有意义的代码来概括以前未见过的数据。
相关链接:
1.https://arxiv.org/abs/1312.6114
2.http://kvfrans.com/variational-autoencoders-explained/
3.http://blog.fastforwardlabs.com/2016/08/12/introducing-variational-autoencoders-in-prose-and.html
原文链接:
https://towardsdatascience.com/the-variational-autoencoder-as-a-two-player-game-part-i-4c3737f0987b
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



