【论文推荐】最新六篇深度强化学习( DRL)相关论文—VR眼镜、参数噪声、恶意软件、合成复杂程序、深度继承表示、自适应
【导读】专知内容组整理了最近六篇深度强化学习( Deep Reinforcement Learning)相关文章,为大家进行介绍,欢迎查看!
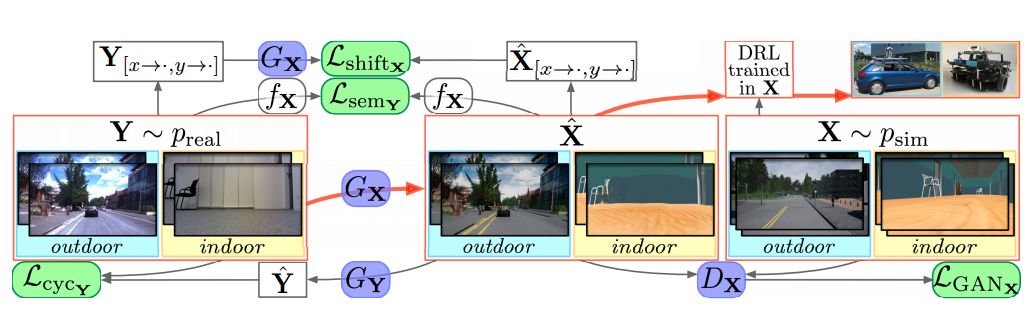
1. VR Goggles for Robots: Real-to-sim Domain Adaptation for Visual Control(机器人VR眼镜:用于视觉控制的Real-to-sim域自适应)
作者:Jingwei Zhang,Lei Tai,Yufeng Xiong,Ming Liu,Joschka Boedecker,Wolfram Burgard
摘要:This paper deals with the reality gap from a novel perspective, targeting transferring Deep Reinforcement Learning (DRL) policies learned in simulated environments to the real-world domain for visual control tasks. Instead of adopting the common solutions to the problem by increasing the visual fidelity of synthetic images output from simulators during the training phase, this paper seeks to tackle the problem by translating the real-world image streams back to the synthetic domain during the deployment phase, to make the robot feel at home. We propose this as a lightweight, flexible, and efficient solution for visual control, as 1) no extra transfer steps are required during the expensive training of DRL agents in simulation; 2) the trained DRL agents will not be constrained to being deployable in only one specific real-world environment; 3) the policy training and the transfer operations are decoupled, and can be conducted in parallel. Besides this, we propose a conceptually simple yet very effective shift loss to constrain the consistency between subsequent frames, eliminating the need for optical flow. We validate the shift loss for artistic style transfer for videos and domain adaptation, and validate our visual control approach in real-world robot experiments. A video of our results is available at: https://goo.gl/b1xz1s.
期刊:arXiv, 2018年2月1日
网址:
http://www.zhuanzhi.ai/document/dc0a7c8ad125a5377401bfb3e20b9a31
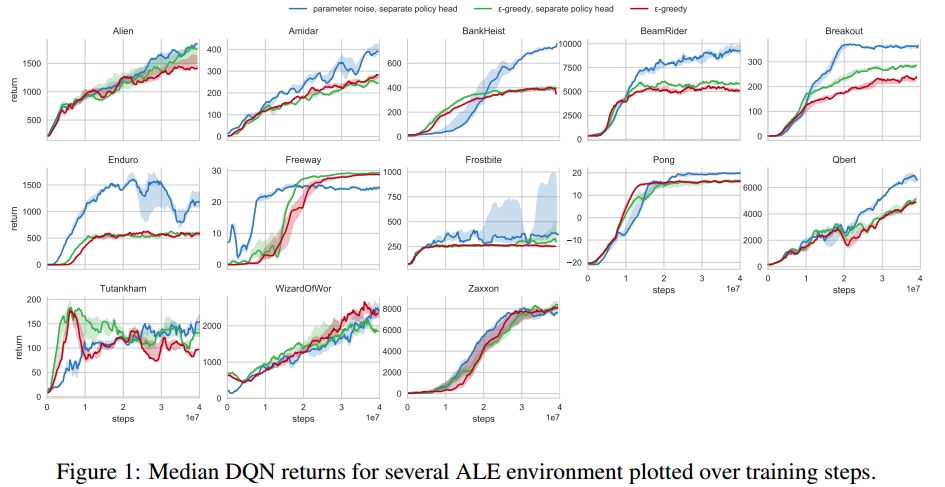
2. Parameter Space Noise for Exploration(基于参数空间噪声的探测方法)
作者:Matthias Plappert,Rein Houthooft,Prafulla Dhariwal,Szymon Sidor,Richard Y. Chen,Xi Chen,Tamim Asfour,Pieter Abbeel,Marcin Andrychowicz
摘要:Deep reinforcement learning (RL) methods generally engage in exploratory behavior through noise injection in the action space. An alternative is to add noise directly to the agent's parameters, which can lead to more consistent exploration and a richer set of behaviors. Methods such as evolutionary strategies use parameter perturbations, but discard all temporal structure in the process and require significantly more samples. Combining parameter noise with traditional RL methods allows to combine the best of both worlds. We demonstrate that both off- and on-policy methods benefit from this approach through experimental comparison of DQN, DDPG, and TRPO on high-dimensional discrete action environments as well as continuous control tasks. Our results show that RL with parameter noise learns more efficiently than traditional RL with action space noise and evolutionary strategies individually.
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/e47bb4e14d72e5846cc0ae6bd98aeb08
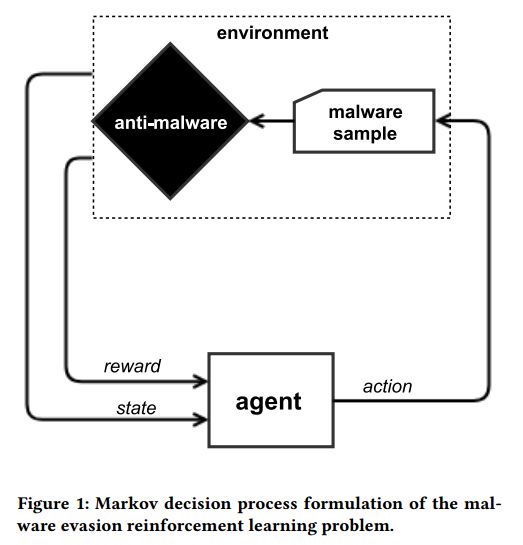
3. Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning(通过强化学习方法来避免静态PE机器学习恶意软件)
作者:Hyrum S. Anderson,Anant Kharkar,Bobby Filar,David Evans,Phil Roth
摘要:Machine learning is a popular approach to signatureless malware detection because it can generalize to never-before-seen malware families and polymorphic strains. This has resulted in its practical use for either primary detection engines or for supplementary heuristic detection by anti-malware vendors. Recent work in adversarial machine learning has shown that deep learning models are susceptible to gradient-based attacks, whereas non-differentiable models that report a score can be attacked by genetic algorithms that aim to systematically reduce the score. We propose a more general framework based on reinforcement learning (RL) for attacking static portable executable (PE) anti-malware engines. The general framework does not require a differentiable model nor does it require the engine to produce a score. Instead, an RL agent is equipped with a set of functionality-preserving operations that it may perform on the PE file. Through a series of games played against the anti-malware engine, it learns which sequences of operations are likely to result in evading the detector for any given malware sample. This enables completely black-box attacks against static PE anti-malware, and produces functional evasive malware samples as a direct result. We show in experiments that our method can attack a gradient-boosted machine learning model with evasion rates that are substantial and appear to be strongly dependent on the dataset. We demonstrate that attacks against this model appear to also evade components of publicly hosted antivirus engines. Adversarial training results are also presented: by retraining the model on evasive ransomware samples, a subsequent attack is 33% less effective. However, there are overfitting dangers when adversarial training, which we note. We release code to allow researchers to reproduce and improve this approach.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/7172e70404a6fe552defa8f8853e49a0
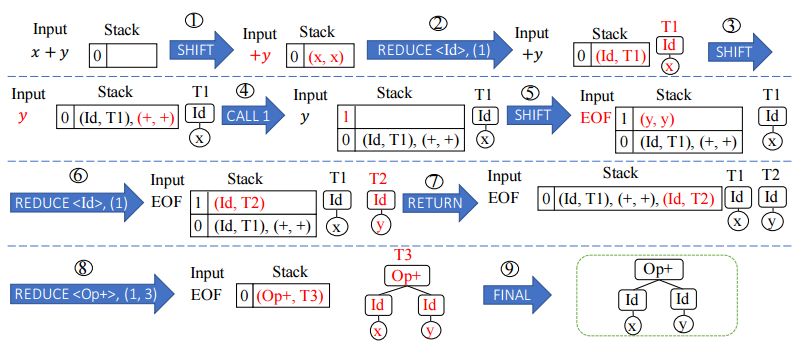
4. Towards Synthesizing Complex Programs from Input-Output Examples(从输入输出示例中合成复杂的程序)
作者:Xinyun Chen,Chang Liu,Dawn Song
摘要:In recent years, deep learning techniques have been developed to improve the performance of program synthesis from input-output examples. Albeit its significant progress, the programs that can be synthesized by state-of-the-art approaches are still simple in terms of their complexity. In this work, we move a significant step forward along this direction by proposing a new class of challenging tasks in the domain of program synthesis from input-output examples: learning a context-free parser from pairs of input programs and their parse trees. We show that this class of tasks are much more challenging than previously studied tasks, and the test accuracy of existing approaches is almost 0%. We tackle the challenges by developing three novel techniques inspired by three novel observations, which reveal the key ingredients of using deep learning to synthesize a complex program. First, the use of a non-differentiable machine is the key to effectively restrict the search space. Thus our proposed approach learns a neural program operating a domain-specific non-differentiable machine. Second, recursion is the key to achieve generalizability. Thus, we bake-in the notion of recursion in the design of our non-differentiable machine. Third, reinforcement learning is the key to learn how to operate the non-differentiable machine, but it is also hard to train the model effectively with existing reinforcement learning algorithms from a cold boot. We develop a novel two-phase reinforcement learning-based search algorithm to overcome this issue. In our evaluation, we show that using our novel approach, neural parsing programs can be learned to achieve 100% test accuracy on test inputs that are 500x longer than the training samples.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/682cbd3461234381b0b0763cc0efea7a
5. Eigenoption Discovery through the Deep Successor Representation(基于深度继承表示的Eigenoption发现)
作者:Marlos C. Machado,Clemens Rosenbaum,Xiaoxiao Guo,Miao Liu,Gerald Tesauro,Murray Campbell
摘要:Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/755279a74418ae8048ccab357d52dbb7
6. Safety-aware Adaptive Reinforcement Learning with Applications to Brushbot Navigation(基于安全意识自适应强化学习的电刷导航应用)
作者:Motoya Ohnishi,Li Wang,Gennaro Notomista,Magnus Egerstedt
摘要:This paper presents a safety-aware learning framework that employs an adaptive model learning method together with barrier certificates for systems with possibly nonstationary agent dynamics. To extract the dynamic structure of the model, we use a sparse optimization technique, and the resulting model will be used in combination with control barrier certificates which constrain feedback controllers only when safety is about to be violated. Under some mild assumptions, solutions to the constrained feedback-controller optimization are guaranteed to be globally optimal, and the monotonic improvement of a feedback controller is thus ensured. In addition, we reformulate the (action-)value function approximation to make any kernel-based nonlinear function estimation method applicable. We then employ a state-of-the-art kernel adaptive filtering technique for the (action-)value function approximation. The resulting framework is verified experimentally on a brushbot, whose dynamics is unknown and highly complex.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/edb72d02dc9ec2fad8fa7a7f9eebdaa3
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



