【David Silver 深度强化学习教程代码实战07】 DQN的实现
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践七 DQN的实现
今天实践七 DQN的实现
声明:本文及涉及的代码为作者原创,欢迎免费规范转载。
本文将带您一起实践深度学习与强化学习联合解决问题的一个经典算法:深度Q学习网络(DQN)。深度学习算法在强化学习领域的应用主要体现在价值函数或策略函数的近似表示上,理解了这一点将有助于您直击深度强化学习问题的本质。正因为如此,我们也可以使用不基于深度学习的其他函数近似工具。
由于训练、调试一个深度学习网络需要较长的时间,并且我基本上是使用自己的风格来写这些代码和博客,因此后续的进度会不固定,成熟一个算法释放一篇文章。不过我这里可以贴一些别人已经写好的基于深度学习算法的一些链接:
borgwang/reinforce_py 用不同的机器学习库实现了各种深度强化学习算法
Reinforcement Learning (DQN) tutorial PyTorch官方教程提供直接基于游戏界面的CNN+DQN组合实现
在此对提供这些链接的作者一并表示感谢。
接下来我来按照自己的节奏和风格解释我的DQN算法实现。在我的代码里,我将把使用神经网络的价值函数的近似表示封装到一个Approximator类中,然后再实现包含此价值函数的继承自Agent基类的个体类:ApproxQAgent,最后我们将观察其在不同环境中的训练效果,并讲讲我自身的编程体会,基于深度学习库的代码我将使用PyTorch库。
好的,我们开始!
Approximator类的实现
Approximator类作为价值函数的近似函数,其要实现的功能很简单:一是输出基于一个状态行为对s,a在参数w描述的函数下的价值Q(s,a,w);另一个是调整参数来更新某型状态行为对s,a的价值。在先前基于GridWorld环境的SarsaAgent实现中,对应这两个函数的分别是读取和设置价值Q表:get_Q和set_Q,读者还记得吗?在基于价值函数的近似表示中,我们调整的不是直接的Q值,而是通过调整生成Q值的参数w来达到这个目的。
在第六讲中,我们学习到使用神经网络来近似价值函数,根据输入和输出数据的不同选择可以有三种不同的网络搭建方式,其中适用于Q学习的两种方式分别是:使用(s,a)为输入,单一的Q为输出,和使用基于s为输入不同行为对应的Q值组成的向量为输出。前者适用范围较广,后者更多见于行为空间为离散值的时候。本例中,我们使用的是后者。我们在__init__方法中声明这样的基于一个隐藏层的简单神经网络(近似价值函数):
#!/home/qiang/PythonEnv/venv/bin/python3.5# -*- coding: utf-8 -*-# function approximators of reinforcment learning# Author: Qiang Ye# Date: July 27, 2017import numpy as npimport torchfrom torch.autograd import Variableimport copyclass Approximator(torch.nn.Module):
'''base class of different function approximator subclasses '''
def __init__(self, dim_input = 1, dim_output = 1, dim_hidden = 16):
super(Approximator, self).__init__()
self.dim_input = dim_input
self.dim_output = dim_output
self.dim_hidden = dim_hidden
self.linear1 = torch.nn.Linear(self.dim_input, self.dim_hidden)
self.linear2 = torch.nn.Linear(self.dim_hidden, self.dim_output)我们主要是定义了两个nn.Module来实现线性变换,具体下文在进行网络的前向运算时会使用到ReLU激活函数。
设计一个_forward方法来预测基于某状态的价值:
def _forward(self, x):
h_relu = self.linear1(x).clamp(min=0) # 实现了ReLU
y_pred = self.linear2(h_relu)
return y_pred再写一个方法fit来进行训练,更新网络参数以更好的符合个体基于Q学习对于价值的判断:
def fit(self, x,
y,
criterion=None,
optimizer=None,
epochs=1,
learning_rate=1e-4):
if criterion is None:
criterion = torch.nn.MSELoss(size_average = False)
if optimizer is None:
optimizer = torch.optim.Adam(self.parameters(), lr = learning_rate)
if epochs < 1:
epochs = 1
x = self._prepare_data(x)
y = self._prepare_data(y, False)
for t in range(epochs):
y_pred = self._forward(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss我们还需要一个方法_prepare_data来对输入数据进行一定的修饰,使得它符合我们上两个方法设计使用到的参数
def _prepare_data(self, x, requires_grad = True):
'''将numpy格式的数据转化为Torch的Variable '''
if isinstance(x, np.ndarray):
x = Variable(torch.from_numpy(x), requires_grad = requires_grad)
if isinstance(x, int):
x = Variable(torch.Tensor([[x]]), requires_grad = requires_grad)
x = x.float() # 从from_numpy()转换过来的数据是DoubleTensor形式
if x.data.dim() == 1:
x = x.unsqueeze(0)
return x同时,为了使得个体在使用近似函数时更加简洁,我们为Approximator类写了一个__call__方法,使得可以像执行函数一样来使用该类提供的方法:
def __call__(self, x):
'''return an output given input. similar to predict function '''
x=self._prepare_data(x)
pred = self._forward(x)
return pred.data.numpy()最后还有一个很重要的事情,由于一些高级DQN算法使用两个近似函数+基于记忆重现的机制来训练个体,因此会产生将一个近似函数的神经网络参数拷贝给另一个近似函数的神经网络这个过程,也就是拷贝网络的过程,我们也需要提供一个能完成此功能的方法clone:
def clone(self):
'''返回当前模型的深度拷贝对象 '''
return copy.deepcopy(self)至此,一个简单但够用的Approximator类就写好了。完整的代码请参见:approximator.py
ApproxQAgent类的实现
由于我们在前几讲的实践中已经为Agent基类设计好的声明一个Agent子类需要的方法,我们在实现基于Q学习的神经网络强化学习算法时只需要集中精力实现这些方法。我们在一个个体中使用双份近似价值函数,一个用来生成策略,另一个用来进行价值估计,每训练一定时间把时刻在更新参数的生成策略的近似价值函数(网络)的参数传递给生成价值的近似价值函数;同样我们的Agent是基于经历回放ExperienceReplay的,这样有利于消除单个Episode内Transition的相关性,提升模型的性能。为此,我们将单独写一个辅助方法来实现基于经历回放的学习。如果不熟悉我们对经历回放的实现机制,请参考前一篇实践:强化学习实践六 给Agent添加记忆功能。
__init__方法初始化ApproxQAgent类
class ApproxQAgent(Agent):
'''使用近似的价值函数实现的Q学习的个体 '''
def __init__(self, env: Env = None,
trans_capacity = 20000,
hidden_dim: int = 16):
if env is None:
raise "agent should have an environment"
super(ApproxQAgent, self).__init__(env, trans_capacity)
self.input_dim, self.output_dim = 1, 1
# 适应不同的状态和行为空间类型
if isinstance(env.observation_space, spaces.Discrete):
self.input_dim = 1
elif isinstance(env.observation_space, spaces.Box):
self.input_dim = env.observation_space.shape[0]
if isinstance(env.action_space, spaces.Discrete):
self.output_dim = env.action_space.n
elif isinstance(env.action_space, spaces.Box):
self.output_dim = env.action_space.shape[0]
# print("{},{}".format(self.input_dim, self.output_dim))
# 隐藏层神经元数目
self.hidden_dim = hidden_dim
# 关键在下面两句,声明了两个近似价值函数
# 变量Q是一个计算价值,产生loss的近似函数(网络),
# 该网络参数在一定时间段内不更新参数
self.Q = Approximator(dim_input = self.input_dim,
dim_output = self.output_dim,
dim_hidden = self.hidden_dim)
# 变量PQ是一个生成策略的近似函数,该函数(网络)的参数频繁更新
self.PQ = self.Q.clone() # 更新参数的网络从经历学习 _learn_from_memory
def _learn_from_memory(self, gamma, batch_size, learning_rate, epochs):
trans_pieces = self.sample(batch_size) # 随机获取记忆里的Transmition
states_0 = np.vstack([x.s0 for x in trans_pieces])
actions_0 = np.array([x.a0 for x in trans_pieces])
reward_1 = np.array([x.reward for x in trans_pieces])
is_done = np.array([x.is_done for x in trans_pieces])
states_1 = np.vstack([x.s1 for x in trans_pieces])
X_batch = states_0
y_batch = self.Q(states_0) # 得到numpy格式的结果
# 使用了Batch,代码是矩阵运算,有点难理解,多通过观察输出来理解
Q_target = reward_1 + gamma * np.max(self.Q(states_1), axis=1)*\ (~ is_done) # is_done则Q_target==reward_1
y_batch[np.arange(len(X_batch)), actions_0] = Q_target
# loss is a torch Variable with size of 1
loss = self.PQ.fit(x = X_batch,
y = y_batch,
learning_rate = learning_rate,
epochs = epochs)
mean_loss = loss.sum().data[0] / batch_size
self._update_Q_net()
return mean_loss重些的学习方法 learning
def learning(self, gamma = 0.99,
learning_rate=1e-5,
max_episodes=1000,
batch_size = 64,
min_epsilon = 0.2,
epsilon_factor = 0.1,
epochs = 1):
"""learning的主要工作是构建经历,当构建的经历足够时,同时启动基于经历的学习 """
total_steps, step_in_episode, num_episode = 0, 0, 0
target_episode = max_episodes * epsilon_factor
while num_episode < max_episodes:
epsilon = self._decayed_epsilon(cur_episode = num_episode,
min_epsilon = min_epsilon,
max_epsilon = 1,
target_episode = target_episode)
self.state = self.env.reset()
# self.env.render()
step_in_episode = 0
loss, mean_loss = 0.00, 0.00
is_done = False
while not is_done:
s0 = self.state
a0 = self.performPolicy(s0, epsilon)
# act方法封装了将Transition记录至Experience中的过程,还记得吗?
s1, r1, is_done, info, total_reward = self.act(a0)
# self.env.render()
step_in_episode += 1
# 当经历里有足够大小的Transition时,开始启用基于经历的学习
if self.total_trans > batch_size:
loss += self._learn_from_memory(gamma,
batch_size,
learning_rate,
epochs)
mean_loss = loss / step_in_episode
print("{0} epsilon:{1:3.2f}, loss:{2:.3f}".
format(self.experience.last, epsilon, mean_loss))
# print(self.experience)
total_steps += step_in_episode
num_episode += 1
return 重写和添加一些辅助方法
在前面的代码中,我们使用了performPolicy方法,我们需要对此方法进行重些,实现基于衰减的 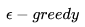
def _decayed_epsilon(self,cur_episode: int,
min_epsilon: float,
max_epsilon: float,
target_episode: int) -> float:
'''获得一个在一定范围内的epsilon '''
slope = (min_epsilon - max_epsilon) / (target_episode)
intercept = max_epsilon
return max(min_epsilon, slope * cur_episode + intercept)
def _curPolicy(self, s, epsilon = None):
'''依据更新策略的价值函数(网络)产生一个行为 '''
Q_s = self.PQ(s)
rand_value = random()
if epsilon is not None and rand_value < epsilon:
return self.env.action_space.sample()
else:
return int(np.argmax(Q_s))
def performPolicy(self, s, epsilon = None):
return self._curPolicy(s, epsilon)最后,我们还需要一个方法来将一直在更新参数的近似函数(网络)的权重拷贝给生成价值并基于此得到损失的近似函数(网络):
def _update_Q_net(self):
'''将更新策略的Q网络(连带其参数)复制给输出目标Q值的网络 '''
self.Q = self.PQ.clone()至此,一个完整的使用神经网络(深度学习)作为近似价值函数、通过对经历进行Q学习的强化学习个体就实现了。该个体类的完整代码在Agents.py类中。
观察DQN的训练效果
我们写一小段代码来基于某个环境来训练我们的ApproxQAgent类。我们使用了三种环境,分别是:CartePole、PuckWorld、和MountainCar。新建一个文件来写入如下代码:
from random import random, choice
from gym import Env
import gym
from gridworld import *
from core import Transition, Experience, Agent
from approximator import Approximator
from agents import ApproxQAgent
import torch
def testApproxQAgent():
env = gym.make("MountainCar-v0")
#env = SimpleGridWorld()
directory = "/home/qiang/workspace/reinforce/monitor"
env = gym.wrappers.Monitor(env, directory, force=True)
agent = ApproxQAgent(env,
trans_capacity = 10000, # 记忆容量(按状态转换数计)
hidden_dim = 16) # 隐藏神经元数量
env.reset()
print("Learning...")
agent.learning(gamma=0.99, # 衰减引子
learning_rate = 1e-3,# 学习率
batch_size = 64, # 集中学习的规模
max_episodes=2000, # 最大训练Episode数量
min_epsilon = 0.01, # 最小Epsilon
epsilon_factor = 0.3,# 开始使用最小Epsilon时Episode的序号占最大
# Episodes序号之比,该比值越小,表示使用
# min_epsilon的episode越多
epochs = 2 # 每个batch_size训练的次数
)
if __name__ == "__main__":
testApproxQAgent()该段代码也可以在我的GitHub上找到。您可以修改环境名称来让Agent在不同环境进行训练。
我们设计的DQN在PuckWorld类、CartPole类上都得到了较好的训练结果,其中实践的前一讲我已近贴上了经过一定时间训练的个体在PuckWorld上的表现情况。这里贴上其在CartPole上的表现:
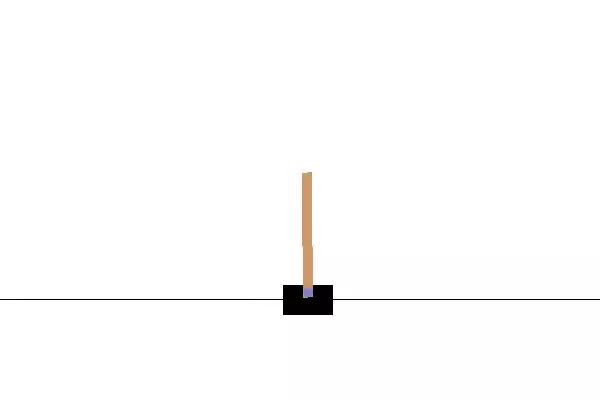
效果也是挺好的,读者可以绘制loss随训练次数的曲线来观察训练的趋势。不过我们的个体在MountainCar上表现不佳,可能和训练时间不够有关系,也可能是和MountainCar环境类好像每隔一定数量的Transition就重置有关系。具体有待我抽空分析解决,读者如果在MountainCar上得到了较好的训练结果或者找到了问题来源和解决方法,欢迎您在评论区留言。
读者也可以拿这个Agent在GridWorld中训练,代码几乎不用修改,但有点杀鸡用牛刀了。
同样,您也可以使用基于单个神经网络,同时不使用经历重现来方法来重写个体,观察个体在一些环境类中的表现,其实他们在某些环境中也有很不错的表现,这里就不详细展开了。
编程体会
基于深度学习的强化学习算法在编写和调试时比之前要难许多,这其中既涉及到深度学习算法实现过程中的难点:数据预处理、基于张量批运算;同时也要熟悉PyTorch库对于数据的处理格式;理解数值拷贝和引用拷贝的区别;最后还要花很多时间去调整超参数。可以说一路下来都不是省油的灯,只有通过不断的练习来自己体会啦,同时希望读者能熟悉并喜欢我这样的建模思想,并能从这样的代码中较容易地理解强化学习算法的核心。祝各位读者痛并快乐的学习着。
下一次实践将聚焦于策略梯度的PyTorch实现,读者可以参考我一开始贴的地址来了解别人是如何实现与策略梯度相关的算法的,比如Actor-Critic。
敬请期待!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



