【2017年末AI最新论文精选】词向量fasttext,CNN is All,强化学习,自回归生成模型, 可视化神经网络损失函数
【导读】专知内容组整理出最近arXiv放出的五篇论文,包括《Tomas Mikolov新作词向量表示,CNN Is All You Need,强化学习库, 自回归生成模型, 揭开神经网络中损失函数的神秘面纱》,每篇都有干货,值得大家收藏阅读。
▌1. Tomas Mikolov新作:高质量的词向量表示
题目: Advances in Pre-Training Distributed Word Representations
作者:Tomas Mikolov, Edouard Grave, Piotr Bojanowski, Christian Puhrsch, Armand Joulin(from Facebook AI Research)
目标:训练高质量的词向量表示。
链接:https://arxiv.org/abs/1712.09405

Tomas Mikolov的文章必属精品,现在许多自然语言处理任务都非常依赖在大型文本语料库(如新闻语料集,维基百科和爬取得网页)上预训练好的词向量。
在本文中,作者展示了如何通过将已有的各种技巧组合来训练高质量的词向量,而这些技巧通常很少被一起使用。 主要成果是提供一系列公开可用的预训练模型,这些模型在许多任务上大大优于现有技术。
▌2. 一个CNN就够了
标题:CNN Is All You Need
作者:Qiming Chen, Ren Wu(来自美国NovuMind公司)
目标:PoseNet显著提高基于CNN的序列到序列学习的准确性
链接:https://arxiv.org/abs/1712.09662
继Attention is All You Need 之后,这一篇题目取CNN Is All You Need,卷积神经网络(CNN)已经在音频,图像和文本学习方面表现出强大的优势; 最近它又在序列到序列(sequence-to-sequence)的学习领域中对流行的基于长期短期记忆单元(LSTM)的递归神经网络(RNN)发出了挑战。之所以要用CNN做序列模式建模,是因为CNN的计算容易并行化,而涉及到RNN的计算大多是连续的、不可并行的,这导致RNN方法遇到性能瓶颈。
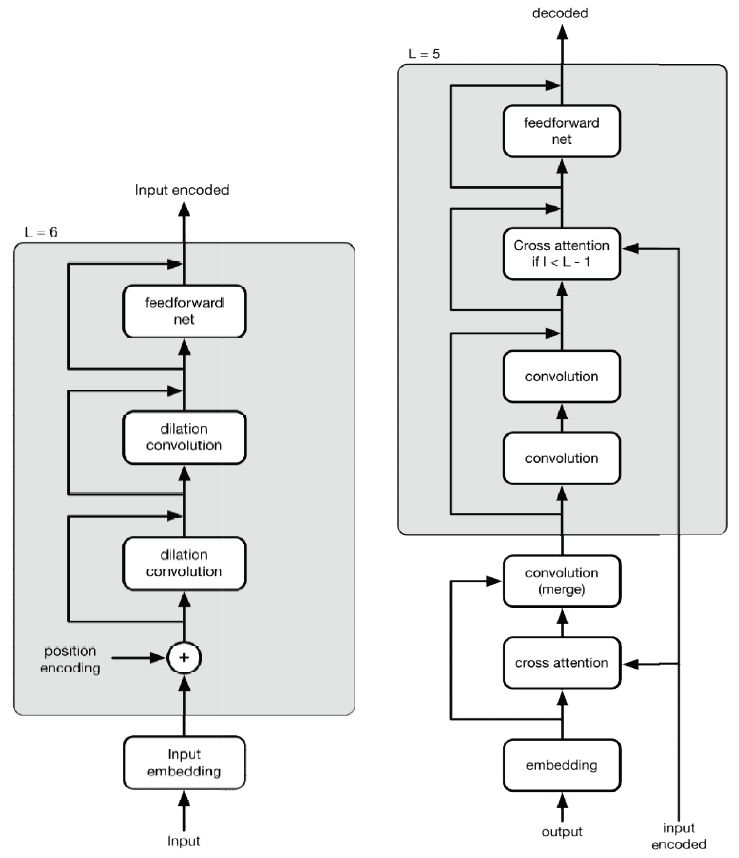
与RNN不同,原始版本的CNN结构缺乏对序列转换所需历史信息的敏感性; 因此增强顺序意识(sequential order awareness)或位置敏感性成为CNN向更一般化的深度学习模型转化的关键。在这项工作中,作者引入一个扩展的CNN模型,称为PoseNet,其加强了对位置信息的敏感程度。 PoseNet的一个显著特点是编码器和解码器中位置信息的不对称处理。实验表明,PoseNet能显着提高基于CNN的序列到序列学习的准确性,在WMT 2014英语到德语翻译任务中获得大约33-36的BLEU分数,在英语到法语翻译任务中获得44-46的BLEU分数。
▌3. Ray RLLib库:一个可组合、可伸缩的强化学习库
标题:Ray RLLib: A Composable and Scalable Reinforcement Learning Library
作者:Eric Liang, Richard Liaw, Robert Nishihara, Philipp Moritz, Roy Fox, Joseph Gonzalez, Ken Goldberg, Ion Stoica(来自加州大学伯克利分校)
目标:一个可组合、可伸缩的强化学习库
链接:https://arxiv.org/abs/1712.09381
代码:https://github.com/ray-project/ray/

强化学习(RL)算法涉及不同组件的深层嵌套,其中每个组件为分布式计算提供了可能。当前的RL库在整个程序层面进行并行, 这种方法将所有组件连接在一起,使单个组件难以扩展、组合和重用。本文中,作者通过在单个组件中封装并行的资源来构建可以灵活组合的RL模块,具体可以基于灵活任务导向的编程模型来实现。
作者通过在Ray之上构建Ray RLLib来证明这一原理,并证明了可以通过组合和重用少数标准组件来实现各种最先进的算法。这种可组合性不以性能为代价,在文章的实验中,RLLib达到或超过了参考方法的性能。 Ray RLLib可作为Ray的一部分使用:参考https://github.com/ray-project/ray/。
▌4. 自回归生成模型:PixelSNAIL
标题:PixelSNAIL: An Improved Autoregressive Generative Model
作者:Xi Chen, Nikhil Mishra, Mostafa Rohaninejad, Pieter Abbeel (from Skolkovo Institute of Science and Technology and University of Oxford)
目标:PixelSNAIL: 改进的自回归生成模型
链接:https://arxiv.org/abs/1712.09763
代码:https://github.com/neocxi/pixelsnail-public
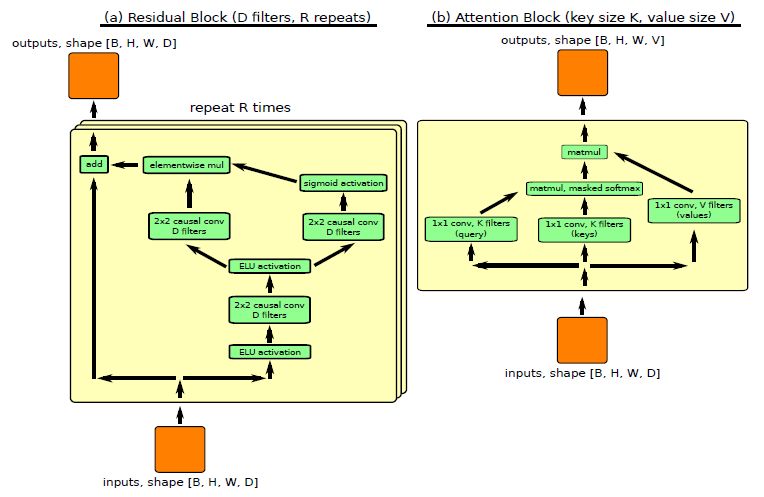
自回归生成模型在对高维度数据(比如图像或音频)进行密度估计任务中一直都有不错的效果。他们把密度估计作为一个序列建模的任务,其中递归神经网络(RNN)模拟下一个元素在它之前的所有元素的条件分布。在这一模式中,瓶颈在于RNN能在多大程度上建模比较长的依赖关系,而最成功的方法依赖于因果卷积,因为它对序列中比较早期部分的访问比传统的RNNs做的更好。
最近的元强化学习的工作中处理长期依赖关系也是必不可少的,受此启发,作者引入了一种新的生成模型架构,它将因果卷积与self attention相结合。在本文中,其在CIFAR-10(2.85 bits per dim)和32×32 ImageNet(3.80 bits per dim)数据集中进行了实验比较。
本文的实现可以在这个网址中找到:https://github.com/neocxi/pixelsnail-public。
▌5.揭开神经网络中损失函数的神秘面纱
标题:Visualizing the Loss Landscape of Neural Nets
作者:Hao Li, Zheng Xu, Gavin Taylor, Tom Goldstein(来自University of Maryland, 和 United States Naval Academy)
目标:神经网络中损失函数可视化面面观
链接:https://arxiv.org/abs/1712.09913
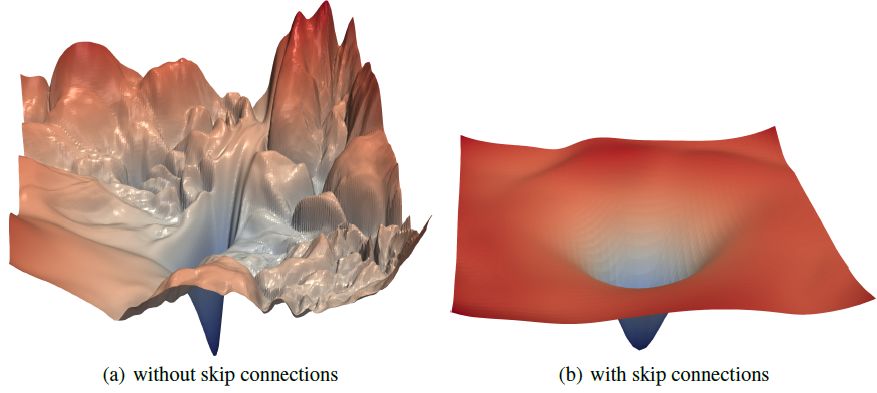
神经网络训练依赖于发现高度非凸损失函数的“好的”极小值的能力。 众所周知,某些网络体系结构(例如,跳跃式连接)能产生更容易训练的损失函数,并且选择好的训练参数(batchsize,学习率,优化方法)能产生更好的最小化值。 然而,这些参数造成结果不同的原因,以及它们对损失函数的影响,目前尚不清楚。 在本文中,文章中使用一系列可视化方法,分析神经网络的损失函数,以及损失函数对泛化性能的影响。
首先,作者介绍一个简单的“滤波器归一化”方法,它能够将损失函数曲率进行可视化,并对损失函数进行各方面的比较。 然后,使用各种可视化方法,探索网络结构是如何影响损失函数,以及训练参数是如何影响极小值的形状(the shape of minimizers)。
参考链接:
https://arxiv.org/abs/1712.09405
https://arxiv.org/abs/1712.09662
https://arxiv.org/abs/1712.09381
https://arxiv.org/abs/1712.09763
https://arxiv.org/abs/1712.09913
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



