【论文推荐】最新6篇目标检测相关论文—场景文本检测 、显著对象、语义知识转移、混合监督目标检测、域自适应、车牌识别
【导读】专知内容组整理了最近六篇目标检测(Object Detection)相关文章,为大家进行介绍,欢迎查看!
1. Rotation-Sensitive Regression for Oriented Scene Text Detection(面向场景文本检测的旋转敏感型回归)
作者:Minghui Liao,Zhen Zhu,Baoguang Shi,Gui-song Xia,Xiang Bai
机构:Huazhong University of Science and Technology,Wuhan University
摘要:Text in natural images is of arbitrary orientations, requiring detection in terms of oriented bounding boxes. Normally, a multi-oriented text detector often involves two key tasks: 1) text presence detection, which is a classification problem disregarding text orientation; 2) oriented bounding box regression, which concerns about text orientation. Previous methods rely on shared features for both tasks, resulting in degraded performance due to the incompatibility of the two tasks. To address this issue, we propose to perform classification and regression on features of different characteristics, extracted by two network branches of different designs. Concretely, the regression branch extracts rotation-sensitive features by actively rotating the convolutional filters, while the classification branch extracts rotation-invariant features by pooling the rotation-sensitive features. The proposed method named Rotation-sensitive Regression Detector (RRD) achieves state-of-the-art performance on three oriented scene text benchmark datasets, including ICDAR 2015, MSRA-TD500, RCTW-17 and COCO-Text. Furthermore, RRD achieves a significant improvement on a ship collection dataset, demonstrating its generality on oriented object detection.

期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/1faa108edb43465c67f46f160b9bf1bb
2. Revisiting Salient Object Detection: Simultaneous Detection, Ranking, and Subitizing of Multiple Salient Objects(重显对象检测:同时检测、排序和对多个显著对象进行分类)
作者:Md Amirul Islam,Mahmoud Kalash,Neil D. B. Bruce
机构:University of Manitoba,Ryerson University
摘要:Salient object detection is a problem that has been considered in detail and many solutions proposed. In this paper, we argue that work to date has addressed a problem that is relatively ill-posed. Specifically, there is not universal agreement about what constitutes a salient object when multiple observers are queried. This implies that some objects are more likely to be judged salient than others, and implies a relative rank exists on salient objects. The solution presented in this paper solves this more general problem that considers relative rank, and we propose data and metrics suitable to measuring success in a relative objects saliency landscape. A novel deep learning solution is proposed based on a hierarchical representation of relative saliency and stage-wise refinement. We also show that the problem of salient object subitizing can be addressed with the same network, and our approach exceeds performance of any prior work across all metrics considered (both traditional and newly proposed).

期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/b5c0e7bce468129459509515573dfc75
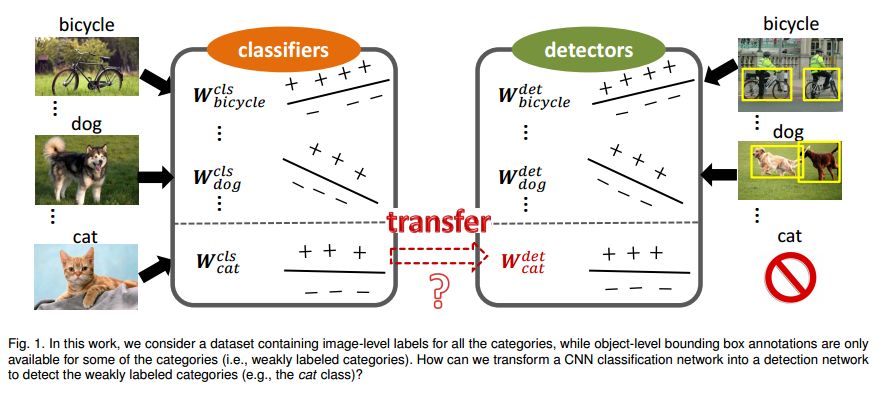
3. Visual and Semantic Knowledge Transfer for Large Scale Semi-supervised Object Detection(大规模半监督物体检测的可视化和语义知识转移)
作者:Yuxing Tang,Josiah Wang,Xiaofang Wang,Boyang Gao,Emmanuel Dellandrea,Robert Gaizauskas,Liming Chen
摘要:Deep CNN-based object detection systems have achieved remarkable success on several large-scale object detection benchmarks. However, training such detectors requires a large number of labeled bounding boxes, which are more difficult to obtain than image-level annotations. Previous work addresses this issue by transforming image-level classifiers into object detectors. This is done by modeling the differences between the two on categories with both image-level and bounding box annotations, and transferring this information to convert classifiers to detectors for categories without bounding box annotations. We improve this previous work by incorporating knowledge about object similarities from visual and semantic domains during the transfer process. The intuition behind our proposed method is that visually and semantically similar categories should exhibit more common transferable properties than dissimilar categories, e.g. a better detector would result by transforming the differences between a dog classifier and a dog detector onto the cat class, than would by transforming from the violin class. Experimental results on the challenging ILSVRC2013 detection dataset demonstrate that each of our proposed object similarity based knowledge transfer methods outperforms the baseline methods. We found strong evidence that visual similarity and semantic relatedness are complementary for the task, and when combined notably improve detection, achieving state-of-the-art detection performance in a semi-supervised setting.
期刊:arXiv, 2018年3月14日
网址:
http://www.zhuanzhi.ai/document/b6695a5d1ab6be2c9f4fbdf20b39334c
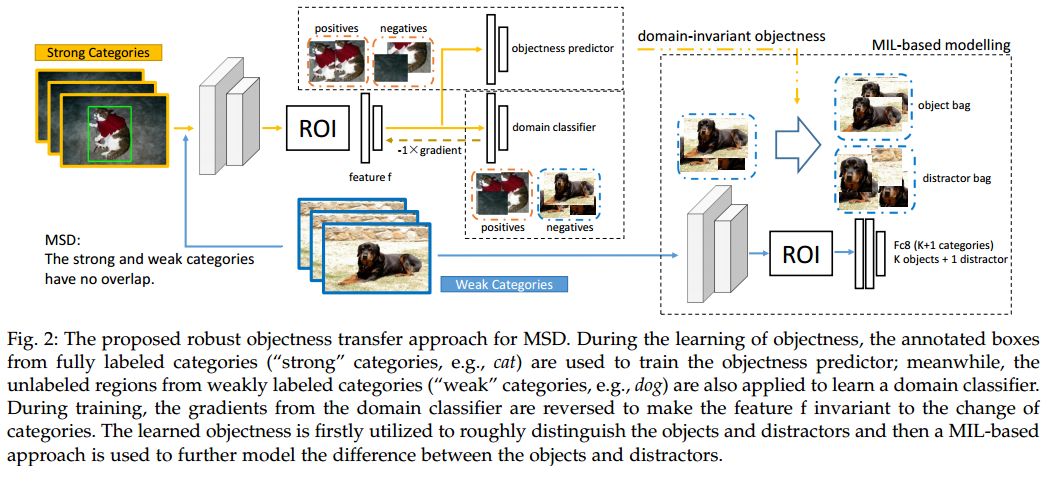
4. Mixed Supervised Object Detection with Robust Objectness Transfer(基于鲁棒物体性转移的混合监督目标检测)
作者:Yan Li,Junge Zhang,Kaiqi Huang,Jianguo Zhang
摘要:In this paper, we consider the problem of leveraging existing fully labeled categories to improve the weakly supervised detection (WSD) of new object categories, which we refer to as mixed supervised detection (MSD). Different from previous MSD methods that directly transfer the pre-trained object detectors from existing categories to new categories, we propose a more reasonable and robust objectness transfer approach for MSD. In our framework, we first learn domain-invariant objectness knowledge from the existing fully labeled categories. The knowledge is modeled based on invariant features that are robust to the distribution discrepancy between the existing categories and new categories; therefore the resulting knowledge would generalize well to new categories and could assist detection models to reject distractors (e.g., object parts) in weakly labeled images of new categories. Under the guidance of learned objectness knowledge, we utilize multiple instance learning (MIL) to model the concepts of both objects and distractors and to further improve the ability of rejecting distractors in weakly labeled images. Our robust objectness transfer approach outperforms the existing MSD methods, and achieves state-of-the-art results on the challenging ILSVRC2013 detection dataset and the PASCAL VOC datasets.
期刊:arXiv, 2018年3月13日
网址:
http://www.zhuanzhi.ai/document/2e2345f4710f476c4db6b74cd91eada8
5. Domain Adaptive Faster R-CNN for Object Detection in the Wild(基于域自适应Faster R-CNN的野外目标检测)
作者:Yuhua Chen,Wen Li,Christos Sakaridis,Dengxin Dai,Luc Van Gool
摘要:Object detection typically assumes that training and test data are drawn from an identical distribution, which, however, does not always hold in practice. Such a distribution mismatch will lead to a significant performance drop. In this work, we aim to improve the cross-domain robustness of object detection. We tackle the domain shift on two levels: 1) the image-level shift, such as image style, illumination, etc, and 2) the instance-level shift, such as object appearance, size, etc. We build our approach based on the recent state-of-the-art Faster R-CNN model, and design two domain adaptation components, on image level and instance level, to reduce the domain discrepancy. The two domain adaptation components are based on H-divergence theory, and are implemented by learning a domain classifier in adversarial training manner. The domain classifiers on different levels are further reinforced with a consistency regularization to learn a domain-invariant region proposal network (RPN) in the Faster R-CNN model. We evaluate our newly proposed approach using multiple datasets including Cityscapes, KITTI, SIM10K, etc. The results demonstrate the effectiveness of our proposed approach for robust object detection in various domain shift scenarios.

期刊:arXiv, 2018年3月9日
网址:
http://www.zhuanzhi.ai/document/767826c575554d3e41a85f2903a81ace
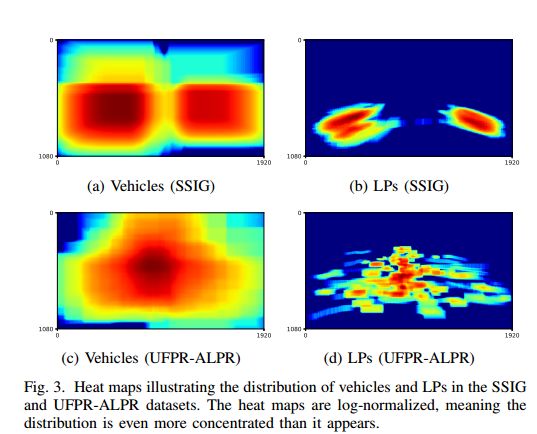
6. A Robust Real-Time Automatic License Plate Recognition based on the YOLO Detector(一种基于YOLO检测器的鲁棒实时自动车牌识别)
作者:Rayson Laroca,Evair Severo,Luiz A. Zanlorensi,Luiz S. Oliveira,Gabriel Resende Gonçalves,William Robson Schwartz,David Menotti
机构:Federal University of Minas Gerais (UFMG),Federal University of Parana (UFPR)
摘要:Automatic License Plate Recognition (ALPR) has been a frequent topic of research due to many practical applications. However, many of the current solutions are still not robust in real-world situations, commonly depending on many constraints. This paper presents a robust and efficient ALPR system based on the state-of-the-art YOLO object detection. The Convolutional Neural Networks (CNNs) are trained and fine-tuned for each ALPR stage so that they are robust under different conditions (e.g., variations in camera, lighting, and background). Specially for character segmentation and recognition, we design a two-stage approach employing simple data augmentation tricks such as inverted License Plates (LPs) and flipped characters. The resulting ALPR approach achieved impressive results in two datasets. First, in the SSIG dataset, composed of 2,000 frames from 101 vehicle videos, our system achieved a recognition rate of 93.53% and 47 Frames Per Second (FPS), performing better than both Sighthound and OpenALPR commercial systems (89.80% and 93.03%, respectively) and considerably outperforming previous results (81.80%). Second, targeting a more realistic scenario, we introduce a larger public dataset, called UFPR-ALPR dataset, designed to ALPR. This dataset contains 150 videos and 4,500 frames captured when both camera and vehicles are moving and also contains different types of vehicles (cars, motorcycles, buses and trucks). In our proposed dataset, the trial versions of commercial systems achieved recognition rates below 70%. On the other hand, our system performed better, with recognition rate of 78.33% and 35 FPS.
期刊:arXiv, 2018年3月2日
网址:
http://www.zhuanzhi.ai/document/4d2916ad31c895aa54f7604c4f41a9d0
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



