Yan Lecun 自监督学习:机器能像人一样学习吗? 110页PPT+视频
【导读】10月5日,瑞士洛桑理工授予Facebook首席AI科学家Yan Lecun荣誉博士学位,同时Yan Lecun做了名为《Self-supervisedlearning: could machines learn like humans?》的报告。
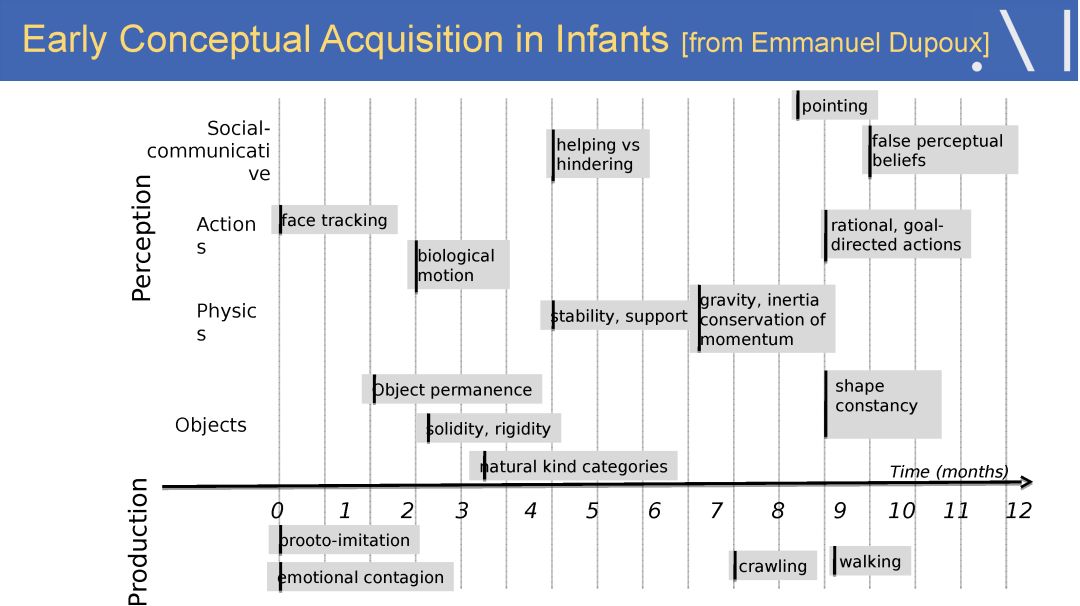
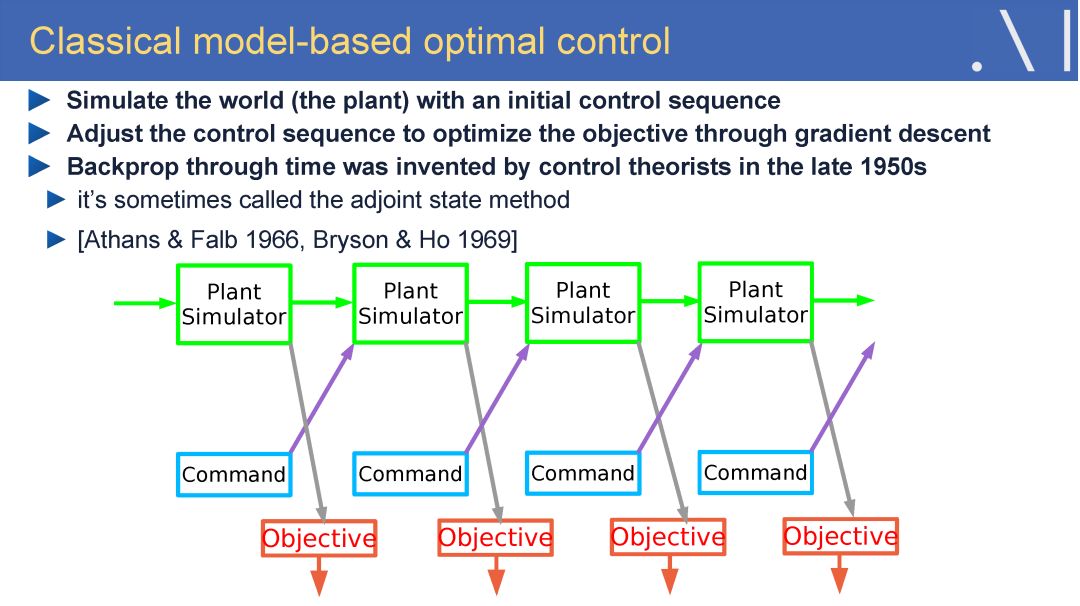
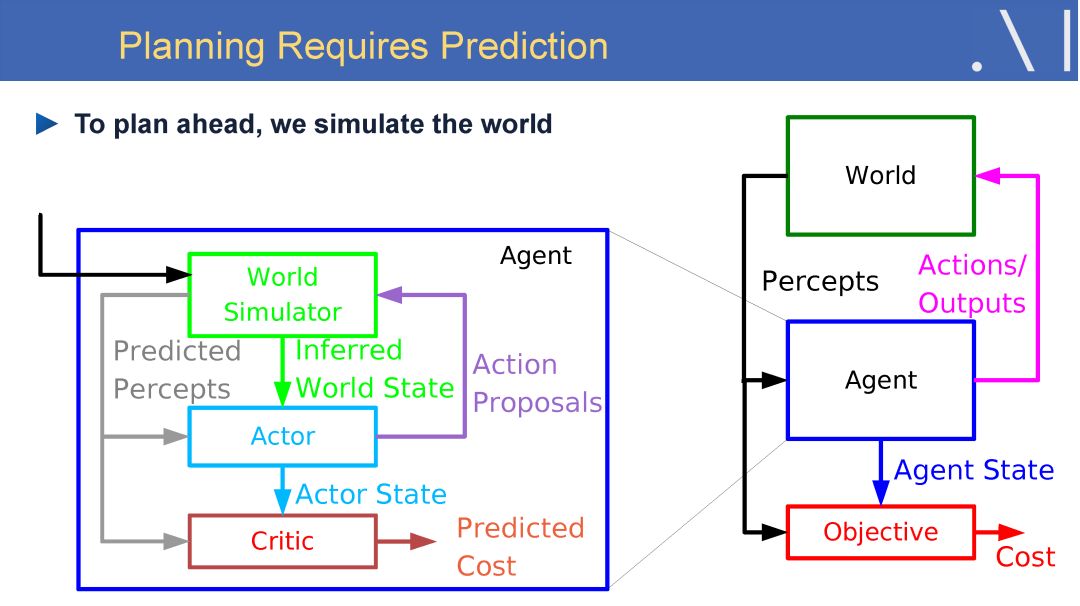
LeCun 表示人工智能革命的未来不会是有监督学习,也不会是单纯的强化学习,而是需要学习一个具备常识推理与预测能力的世界模型。LeCun 认为自监督学习是实现这一目标的一个潜在研究方向。他认可现有的有监督学习和强化学习技术可以使人类在自动驾驶、医疗诊断、机器翻译、客服机器人、信息检索等领域中取得不错的进展,但他认为仅仅依靠现有技术,无法实现常识推理、智能个人助理、智能聊天机器人、家庭机器人以及通用人工智能。
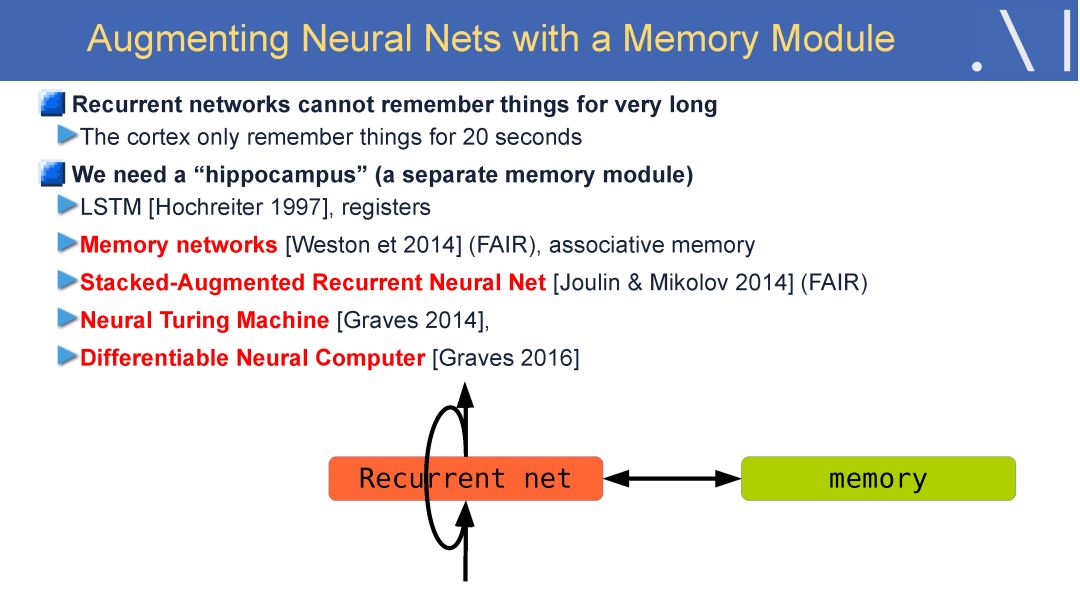
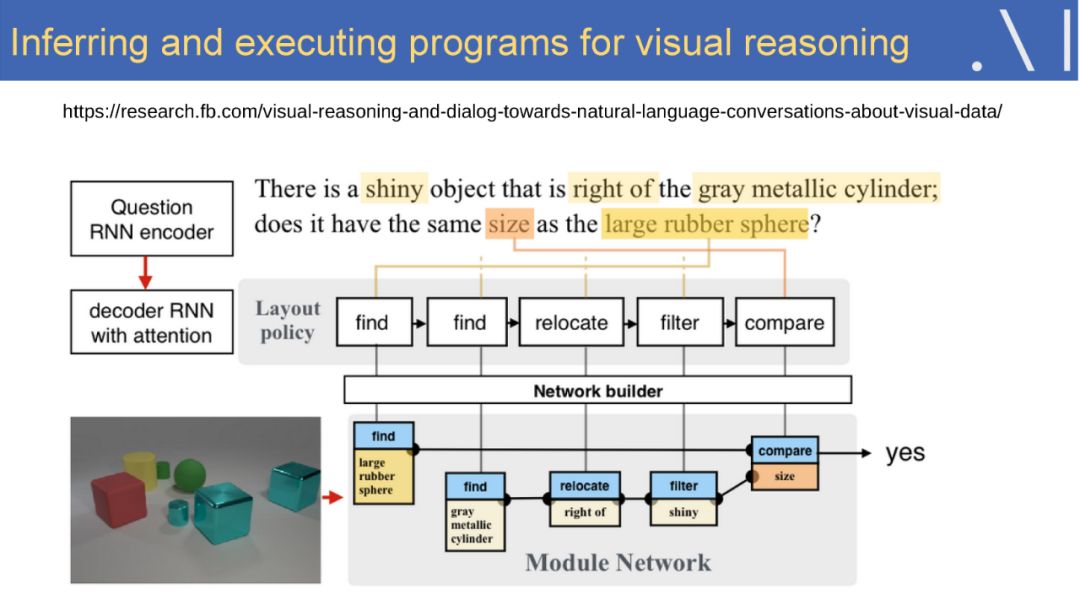
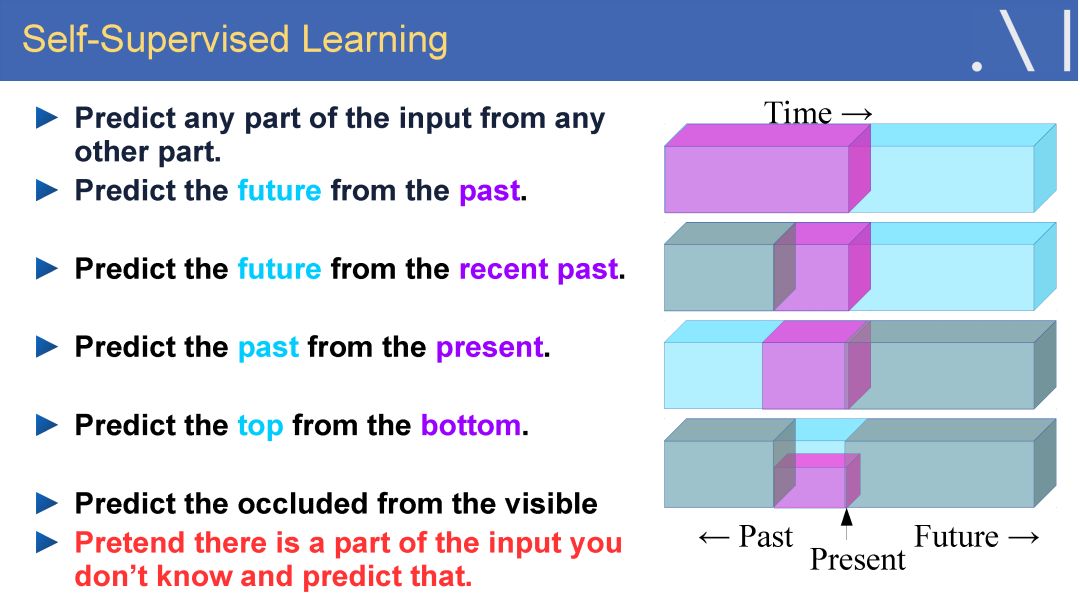
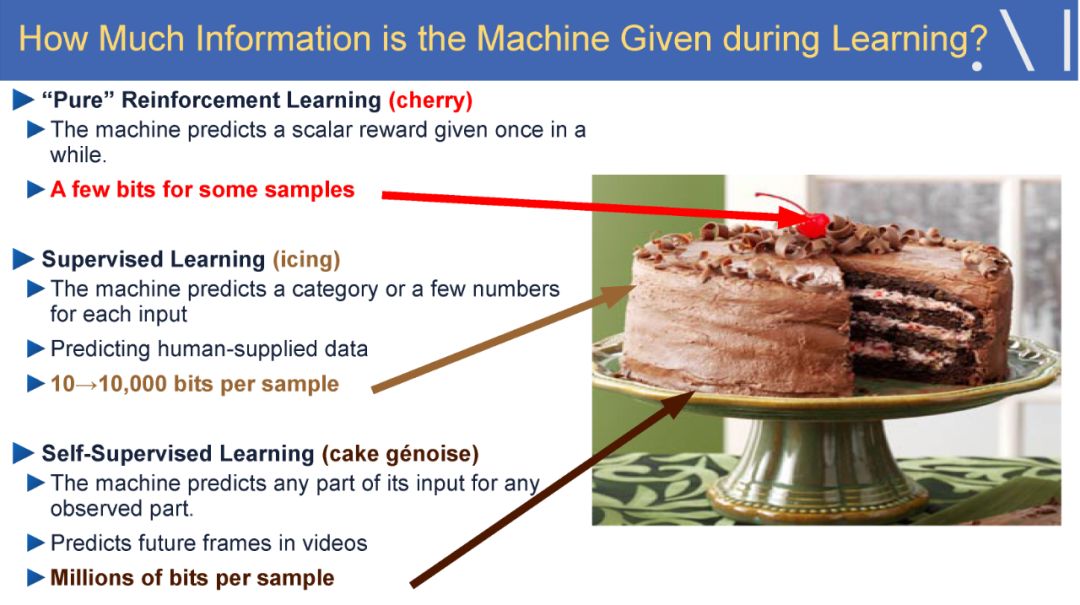
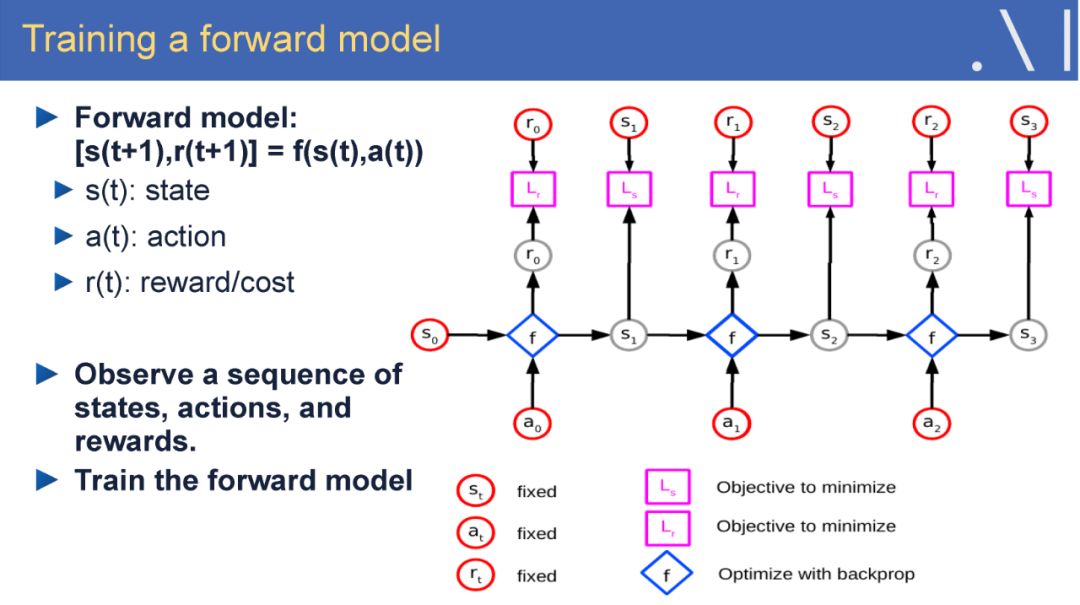
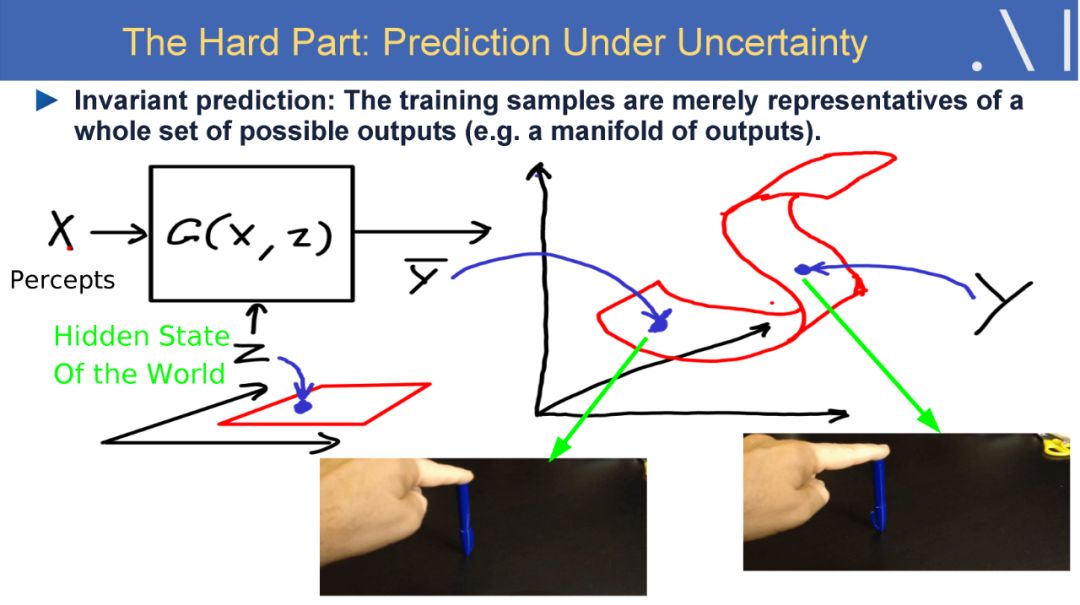
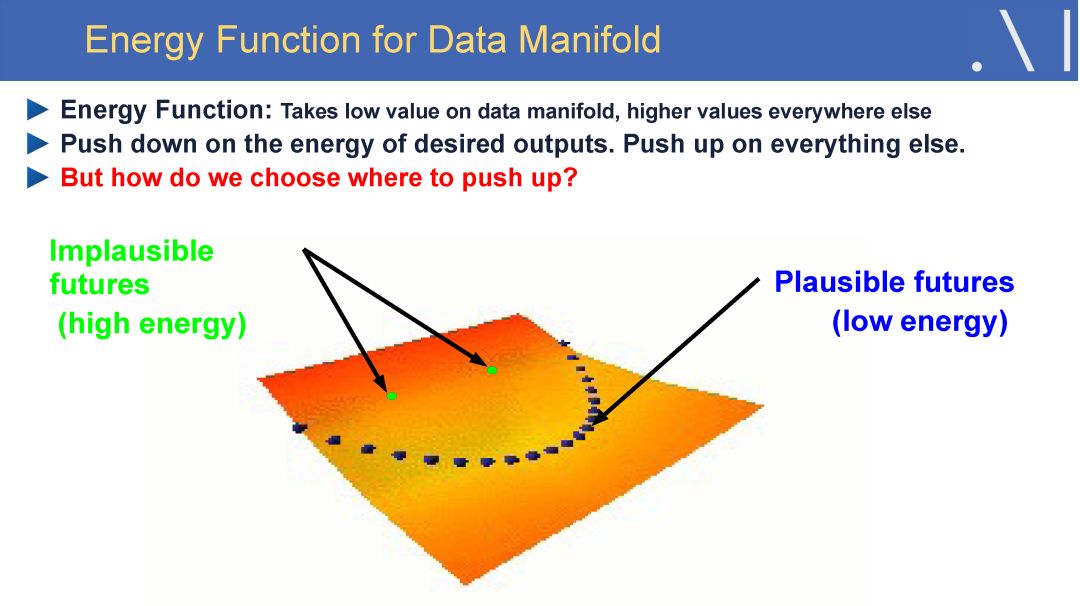
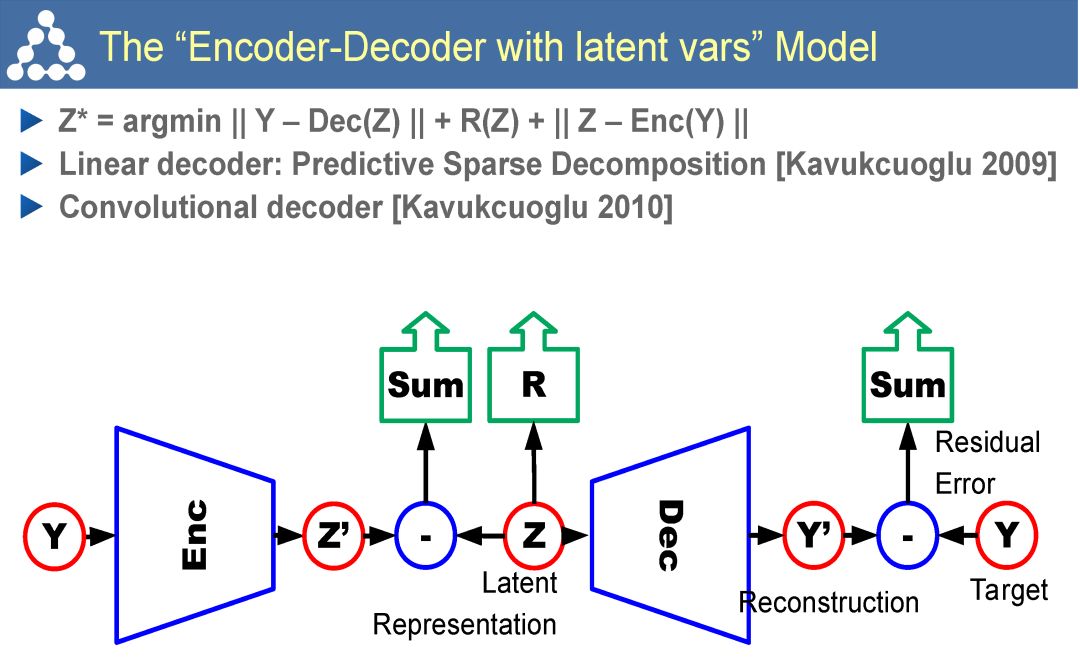
在这样的背景下,LeCun 认为自监督学习是有望突破有监督学习与强化学习现状、学习世界模型的一个潜在研究方向。自监督学习将输入和输出当成一个完整的整体,它通过挖掘输入数据本身提供的弱标注信息,基于输入数据的某些部分预测其它部分。在达到预测目标的过程中,模型可以学习到数据本身的语义特征表示,这些特征表示可以进一步被用于其他任务当中。当前自监督学习的发展主要体现在视频、图像处理领域。例如,在空间层面上包括图像补全、图像语义分割、灰度图像着色等,在时间层面上包括视频帧预测、自动驾驶等。
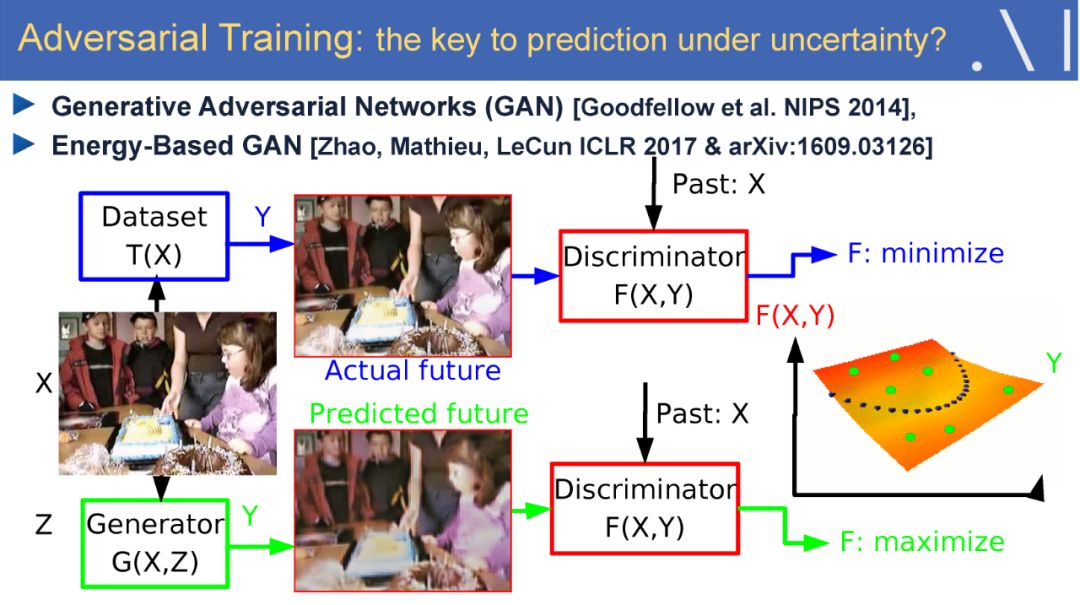
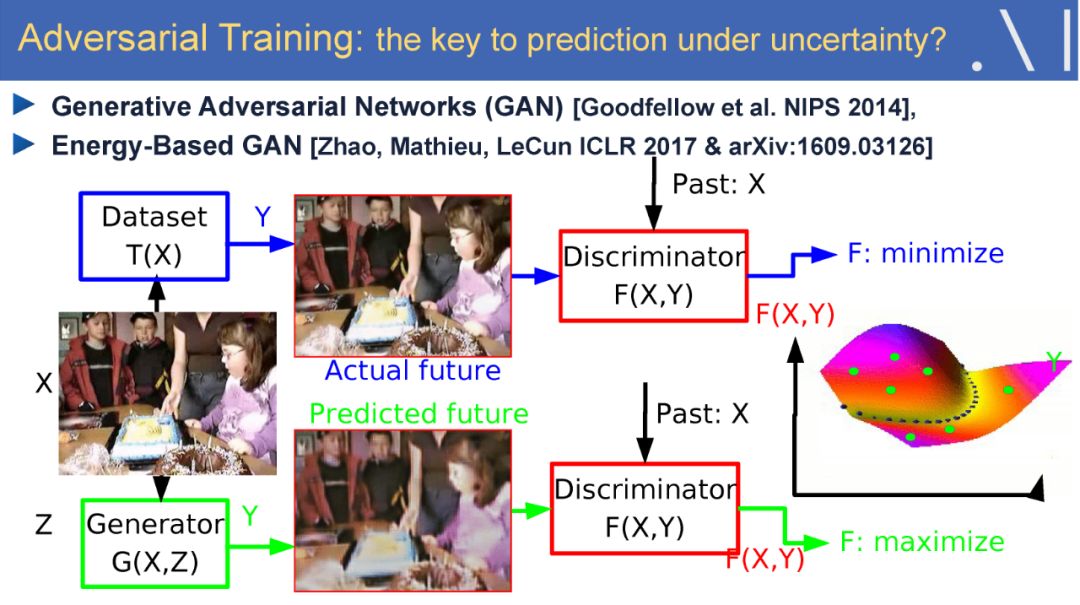
Yan Lecun在报告中指出自监督学习(Self-supervised learning)可以作为强化学习的一种潜在解决方案,因为自监督学习将输入和输出都当成完整系统的一部分,使得它在诸如图像补全,图像迁移,时间序列预测等任务上都非常有效。此外自监督模型的复杂度随着额外反馈信息的加入而增加,可以在很大程度上减少计算过程中人为的干预。
深度学习方法在计算机视觉领域所取得的巨大成功,要归功于大型训练数据集的支持。这些带丰富标注信息的数据集,能够帮助网络学习到可区别性的视觉特征。然而,收集并标注这样的数据集通常需要庞大的人力成本,而所标注的信息也具有一定的局限性。作为替代,使用完全自监督方式学习并设计辅助任务来学习视觉特征的方式,已逐渐成为计算机视觉社区的热点研究方向。
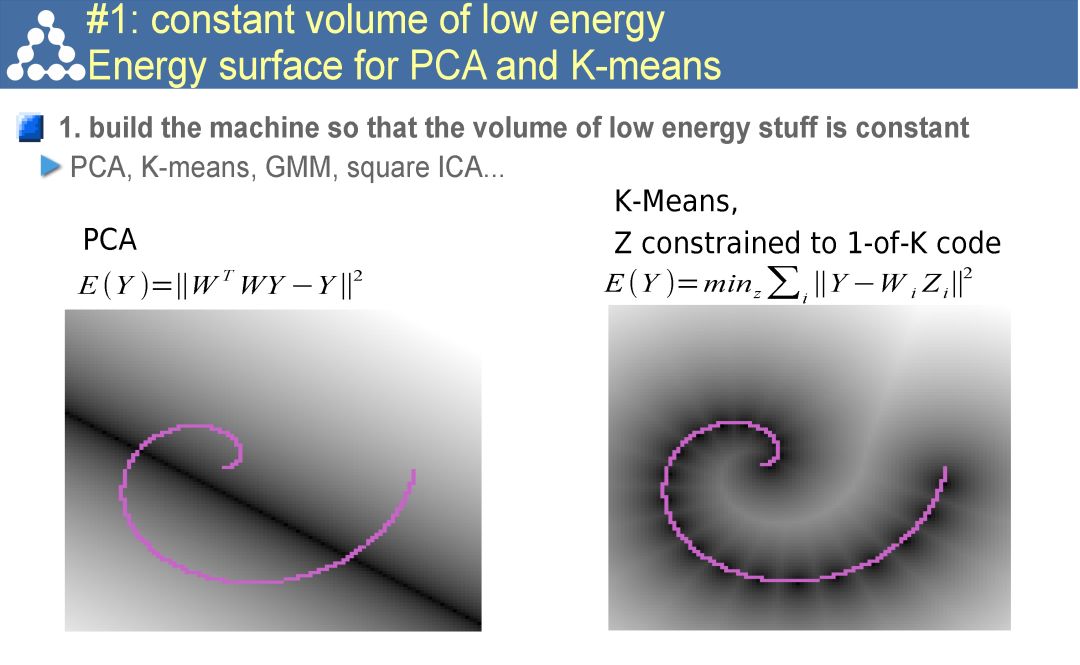
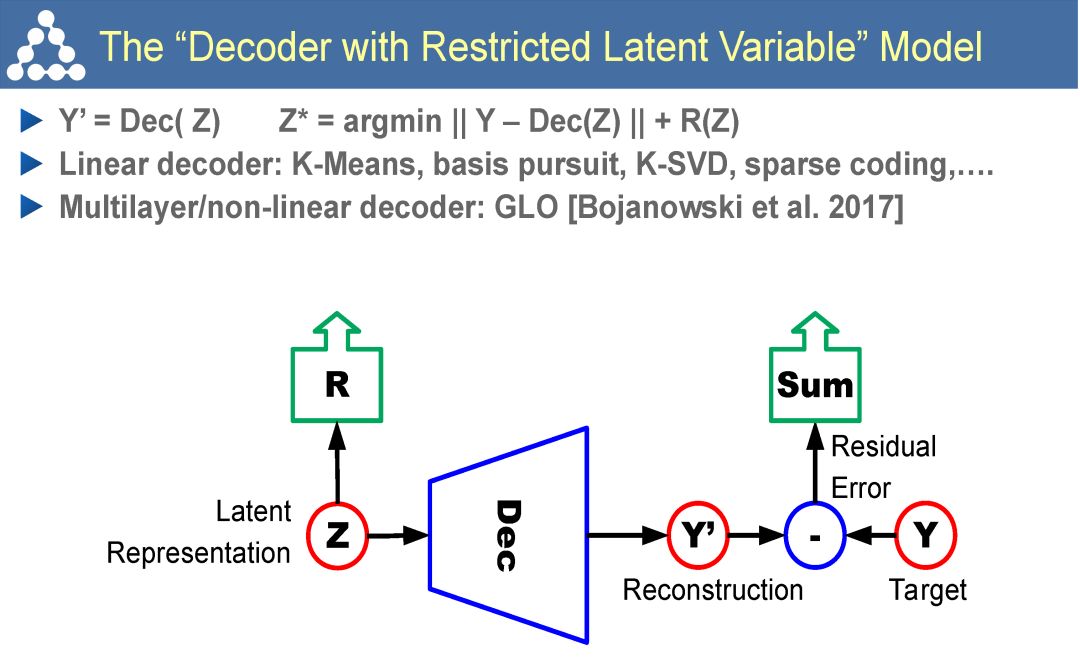
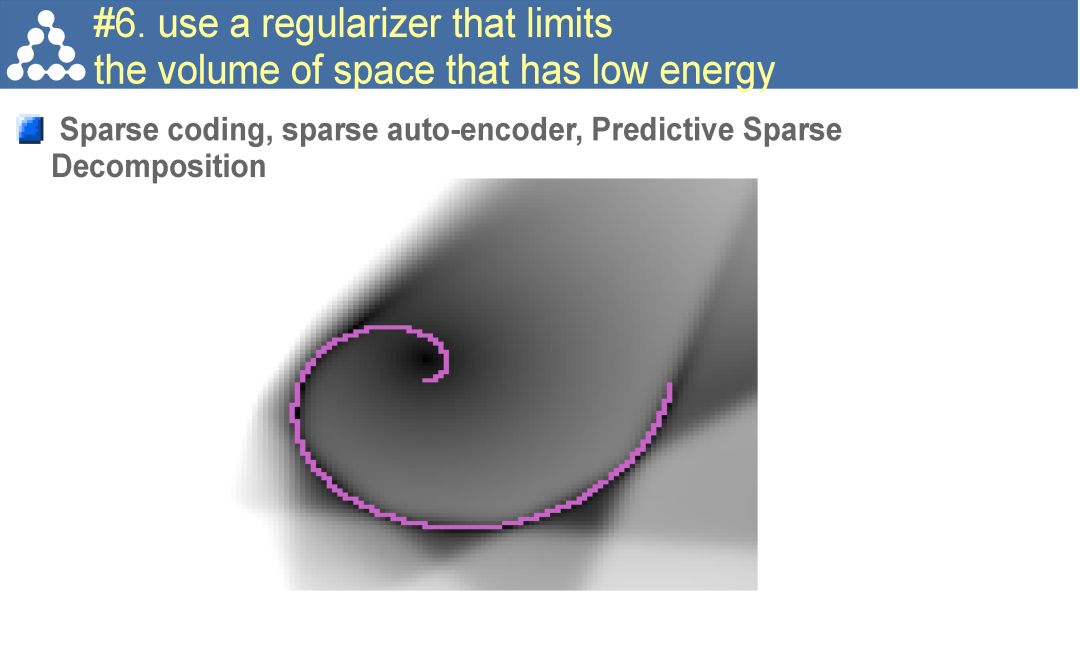
简言之,自监督学习是一种特殊目的的无监督学习。不同于传统的AutoEncoder等方法,仅仅以重构输入为目的,而是希望通过surrogate task学习到和高层语义信息相关联的特征。

请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知)
后台回复“SSL” 就可以获取全文报告 PPT下载链接~
参考文献:
1. The Presentation given by Yann LeCun in theOpening of IJCAI 2018: We Need a World Model
http://ir.hit.edu.cn/~zyli/papers/lecun_ijcai18.pdf
2. 自监督学习近期进展
https://zhuanlan.zhihu.com/p/30265894
3. 报告链接:
https://memento.epfl.ch/event/self-supervised-learning-could-machines-learn-like/
报告视频
个人主页:
http://yann.lecun.com
报告PPT




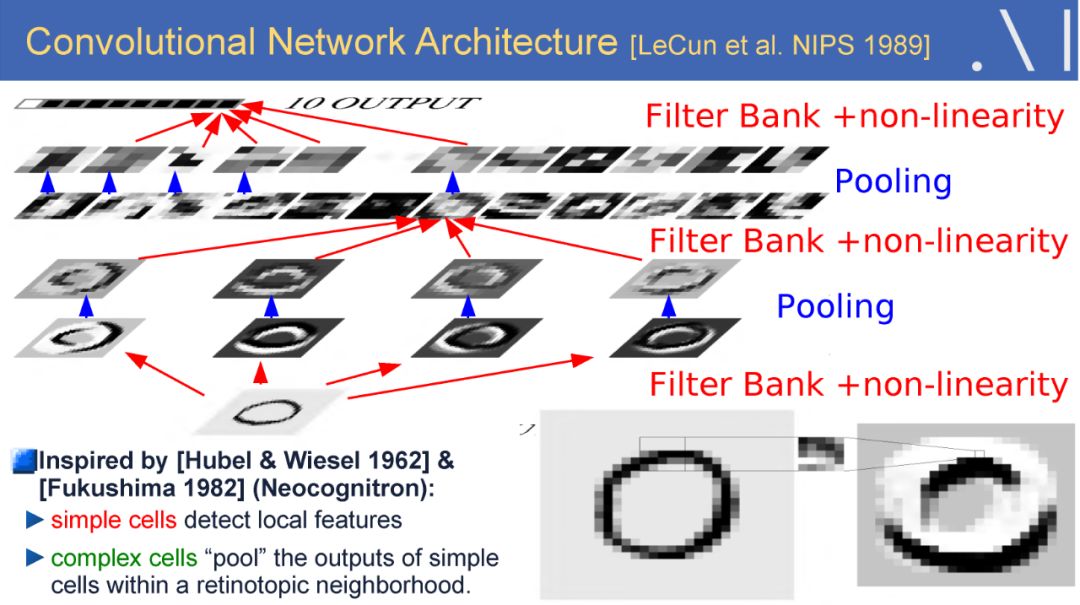
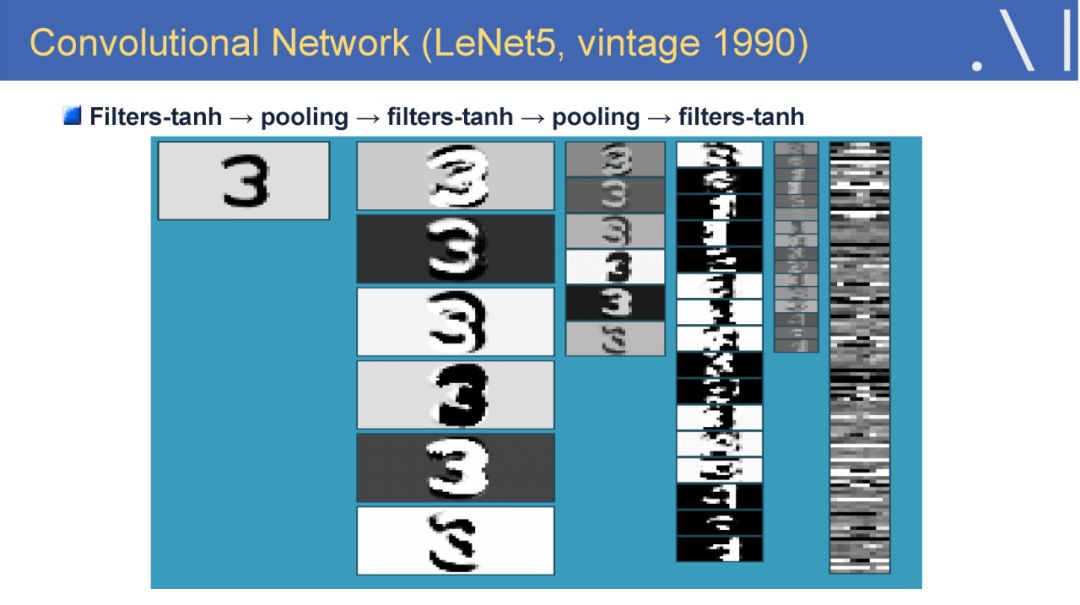

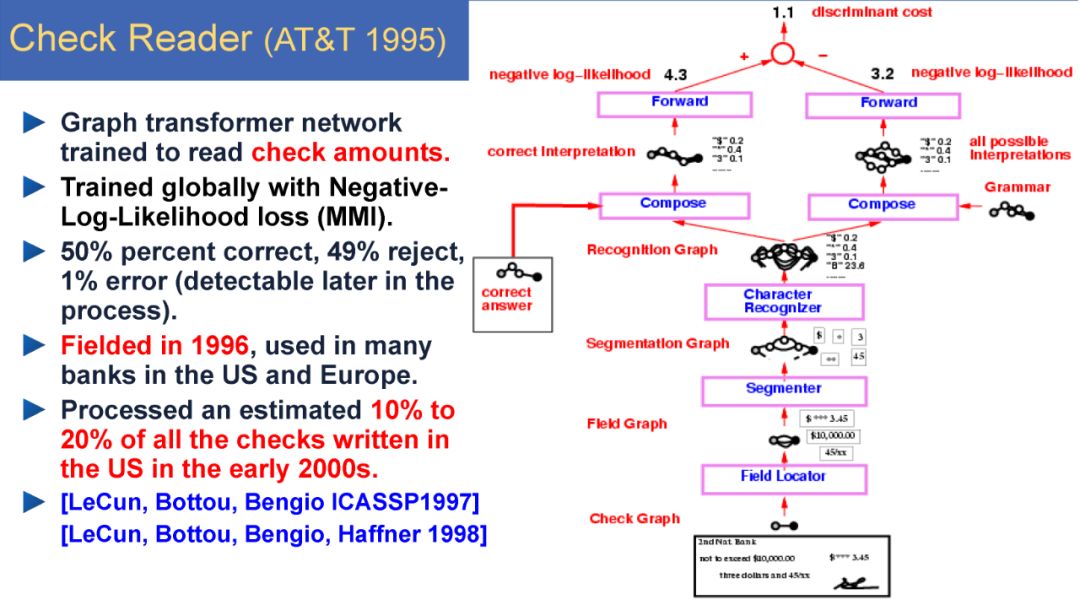







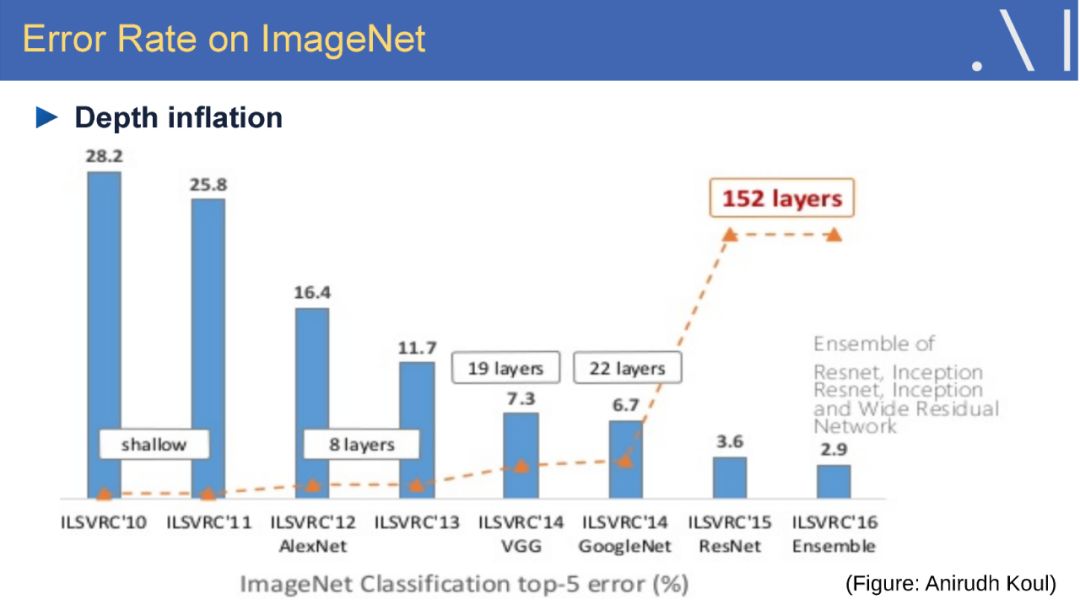































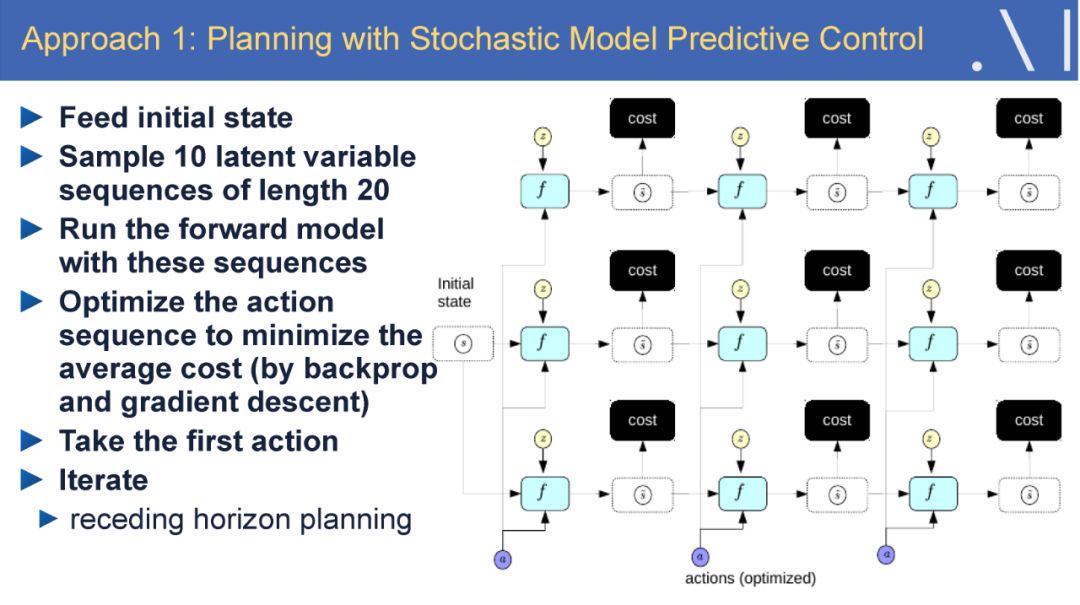
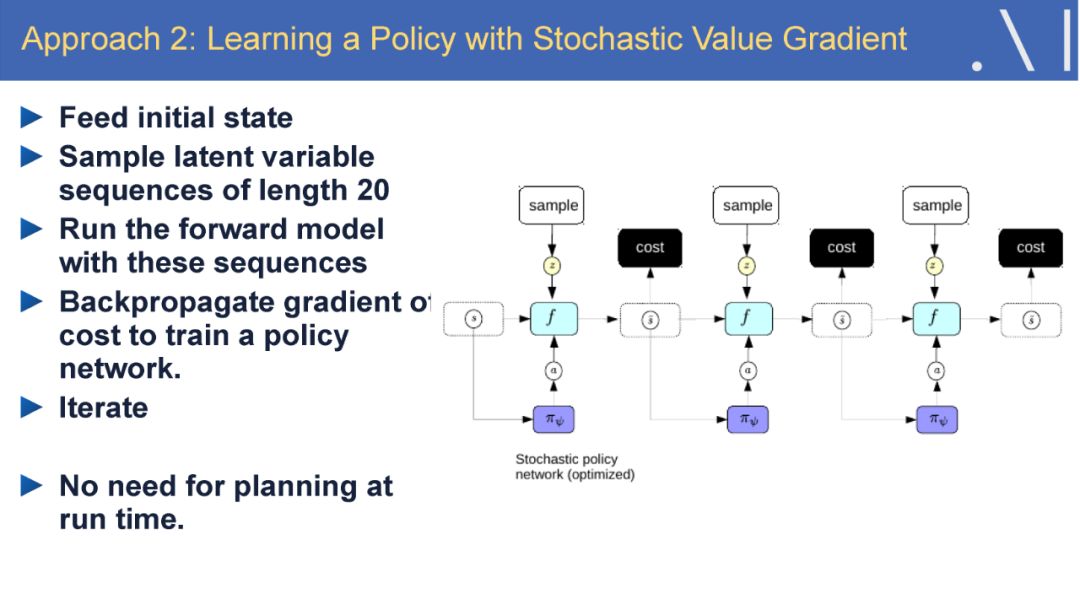
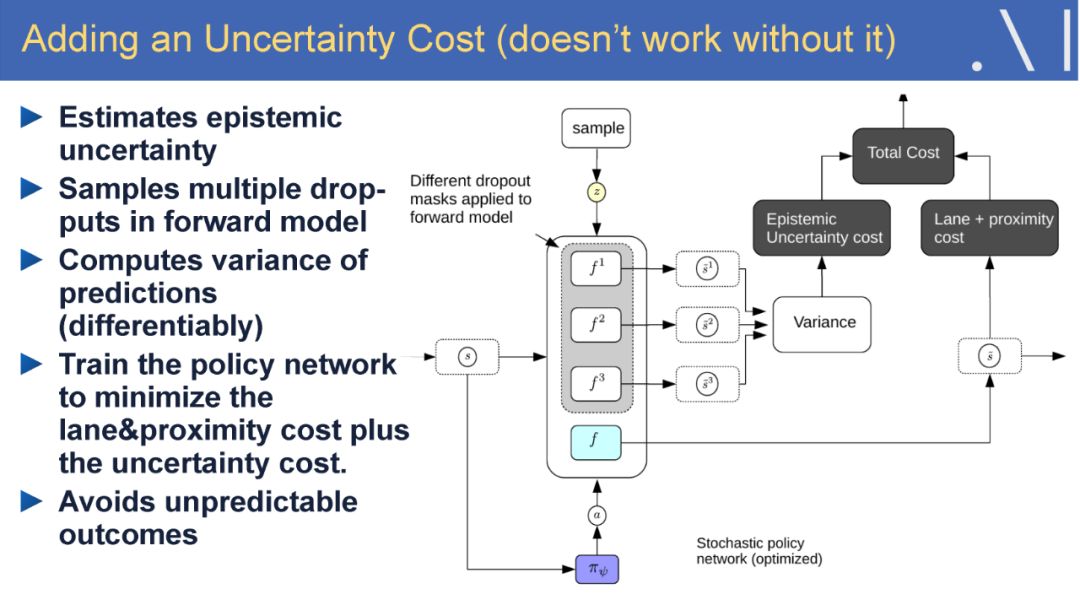






-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



