2019: 属于BERT预训练语言模型之年
【导读】2019年对NLP来说是具有里程碑意义的一年,从阅读理解到情绪分析,各种重要的NLP任务都有了新的记录。核心的研究趋势是NLP中迁移学习,即:使用大量预训练模型,并根据特定的语言相关任务对它们进行微调。迁移学习允许人们重用以前构建的模型中的知识,这可以提高具体应用模型性能和泛化能力,同时需要更少的标注样本。要论2019年最重要的预训练模型,非BERT莫属。
原文题目:
2019: The Year of BERT
原文链接:
https://towardsdatascience.com/2019-the-year-of-bert-354e8106f7ba?
翻译:
专知
先预训练模型,然后再在特定任务上进行微调,这种想法本身并不新鲜——CV领域经常使用预先在大型数据集(如ImageNet)上训练过的模型。而在NLP领域,我们多年来一直通过重用Word Embedding来进行“浅层”的迁移学习。
但是在2019年,有了像BERT这样的模型,我们看到了一个向更深层次的知识迁移的重大转变,通过将整个模型迁移到新的任务——即使用大型的预训练语言模型作为可重用的语言理解特征提取器。
这被称为去年的“NLP's ImageNet moment”。BERT在使NLP中的迁移学习变得异常容易。在这一过程中,他在11个句子级和单词级的NLP任务中得到了最先进的结果,并且具有最小的改动。从实用的角度来看,这是令人兴奋的。但是BERT和其相关模型可能更令人兴奋,因为它们促进了我们对如何向计算机表示语言的基本理解,以及哪种表示方式最适合我们的模型。
当前NLP领域已经形成了一种新的风气:为什么还要重新训练一个模型来学习语法和语义的表示,在你能快速使用BERT的时候?
直到我试图整理一份去年发表的与BERT有关的论文清单时,我才意识到自己有多受欢迎。我收集了169篇与BERT相关的论文,并将它们手工标注到几个不同的研究类别中(例如,构建BERT的特定领域版本、理解BERT的内部机制、构建多语言的BERT,等等)。
这是所有这些论文的一个图表:
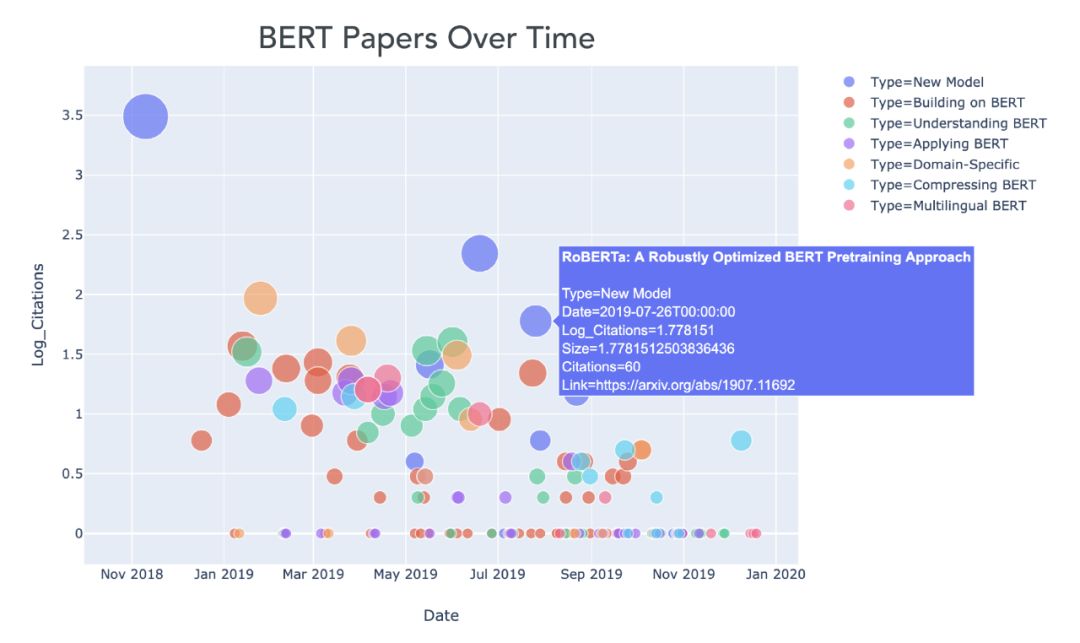
2018年11月至2019年12月期间发表的BERT相关论文。y轴是paper引用的log(由谷歌Scholar得到),这些论文中的大部分是通过在arXiv论文的标题中搜索BERT找到的。
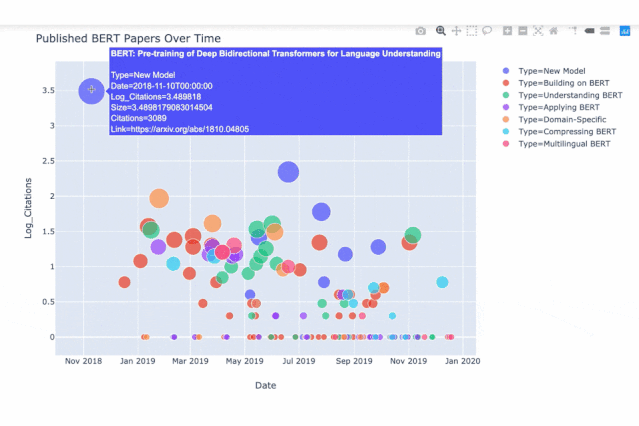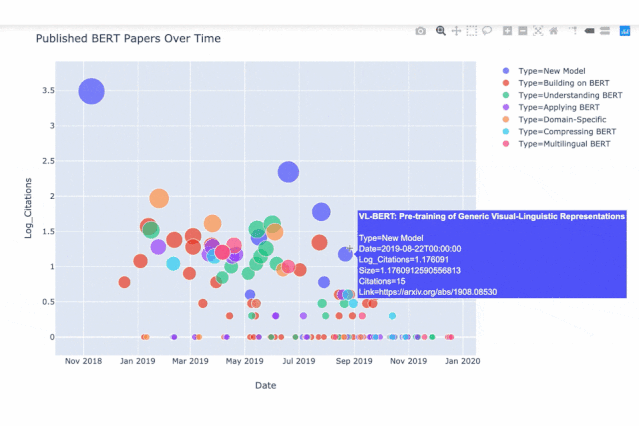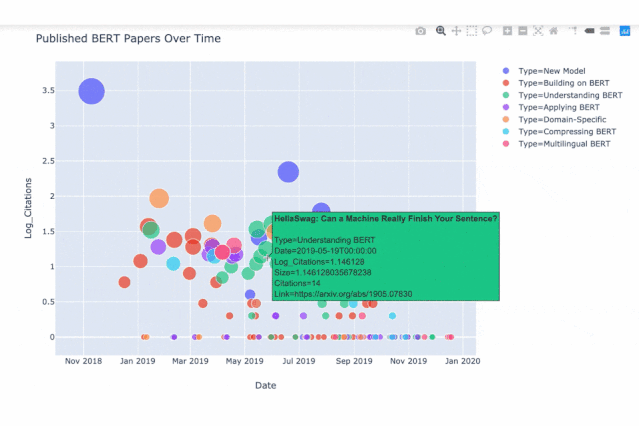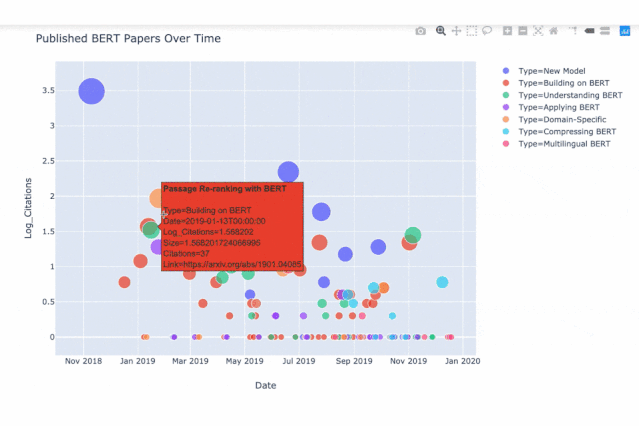
这类信息通常具有更好的交互性,所以这里是一个GIF。你也可以查看Jupyter notebook,和原始数据。
Jupyter Notebook:
https://github.com/nslatysheva/BERT_papers/blob/master/Plotting_BERT_Papers.ipynb
原始数据:
https://raw.githubusercontent.com/nslatysheva/BERT_papers/master/BERT_Papers.csv
现在有很多关于BERT的论文。观察这些文章,我们可以得到一些很有意思的结论:
我们能看到,从2018年11月BERT原始论文的发表和2019年1月左右开始的论文洪流之间有一个(相当短的)时间差。
BERT论文的最初浪潮倾向于关注核心BERT模型(红、紫、橙点)的即时扩展和应用,比如将BERT应用于推荐系统、情感分析、文本摘要和文档检索。
然后,从4月开始,一系列探究BERT内在机制的论文(绿色)发表了,比如理解BERT如何对层级语言现象建模,以及分析注意力头之间的冗余。特别有趣的是“BERT Rediscovers the Classical NLP Pipeline”这篇文章,作者发现BERT的内部计算反映了传统的NLP工作流(首先进行词性标记,然后进行依赖项解析,然后进行实体识别,等等)。
9月左右,一批专注于压缩BERT模型大小的论文(青色)发布,比如DistilBERT、ALBERT和TinyBERT的论文。例如,来自HuggingFace的DistilBERT模型是BERT的压缩版本,其参数数量只有BERT的一半(从1.1亿个减少到6600万个),但在重要的NLP任务上具有95%的性能(参见GLUE基准测试)。
这份BERT论文清单很可能是不完整的。如果与BERT相关的论文的真实数量是我的两倍,我也不会感到惊讶。作为一个粗略的上限,引用原始伯特论文的论文数量目前超过3100篇。
如果你对这些模型的名字感到好奇——本质上,NLP的研究人员对芝麻街的角色非常着迷。我们可以把这一切的开始归咎于ELMo的论文,这使得后来的模型如BERT和ERNIE成为必然。我急切地等待一个BIGBIRD模型-然后我们还可以称他叫压缩版为SMALLBIRD。。。
Lessons from BERT
我们可以从BERT文章中学到一些东西,比如:
开源机器学习模型的价值。作者免费提供了BERT模型和相关代码,并提供了一个简单的、可重用的调优过程。这种开放性对加速研究至关重要,我怀疑,如果作者不那么直率,BERT也不会如此受欢迎。
认真对待超参数调优的重要性。RoBERTa的论文提出了一种训练BERT的更有效的方法,通过优化设计选择(比如改变训练任务)和更广泛的超参数调优,引起了轰动。这种更新的训练机制,加上仅仅对模型进行更长时间的更多数据的训练,再一次将各种NLP基准的性能推到破纪录的水平。
关于模型大小的思考。BERT论文的作者发现,简单地增加模型的大小就可以显著地提高性能,即使是在非常小的数据集上。也许这意味着在某种意义上,您“需要”数亿个参数来表示人类语言。2019年的其他几篇论文发现,简单地扩大NLP模型的规模就会带来改进(著名的OpenAI的GPT-2模型)。还有一些新的技巧来训练大得离谱的NLP模型,比如NVIDIA的80亿个参数巨兽。但也有证据表明,随着模型尺寸的增大,收益会递减,这与计算机视觉研究人员在增加卷积层时遇到的困难类似。
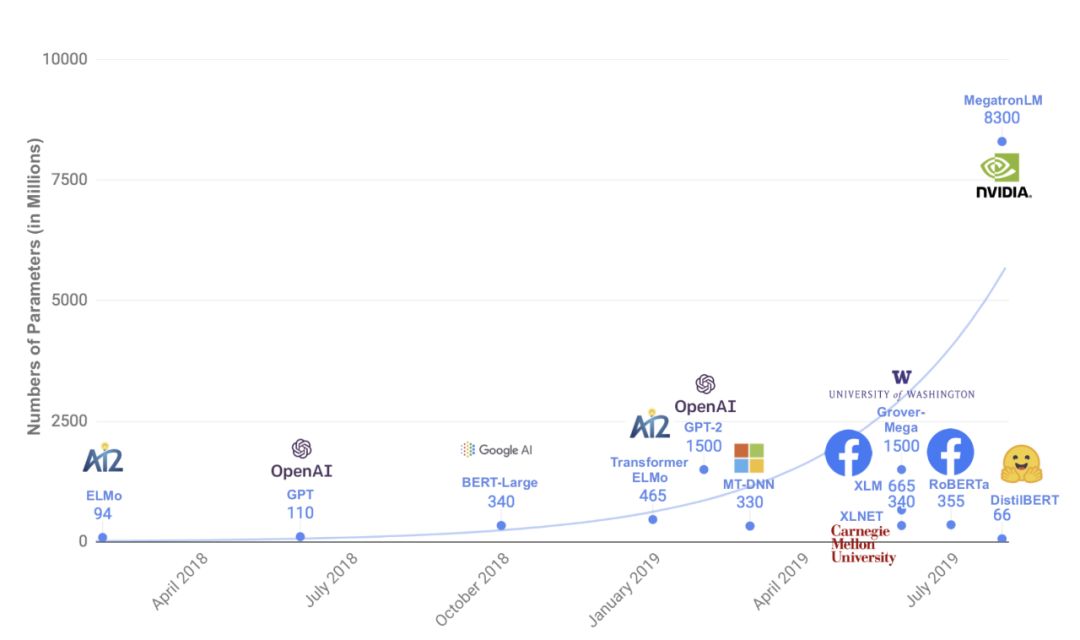
预训练语言模型正在变得越来越大
到底什么是BERT?
让我们退一步来讨论一下BERT到底是什么。BERT(Bidirectional Encoder Representations from Transformers)是谷歌研究人员建立的一个预训练语言模型(LM)。语言模型被训练在能够激励模型深入理解语言的任务上; LMs的一个常见训练任务是预测一句话的下一个单词(“the cat sat on the ___”)。
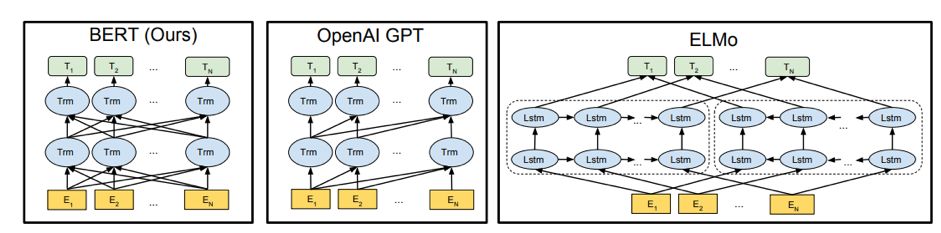
BERT基于一种相对较新的神经网络结构——Transformers,它使用一种叫做“Self-attention”的机制来捕捉单词之间的关系。Transformers中没有卷积(如CNNs)或递归操作(如RNNs)(“Attention is all you need”)。网上已经发布了许多优秀的教程来解释Transformer和self-attention了,所以在这里我就不多讲了。这里我只简单的介绍一下:
Self-attention是一个sequence-to-sequence的操作,它通过将每个单词的上下文嵌入到其表示中来更新输入Token的嵌入。这使得它可以同时对所有输入单词之间的关系建模——这与RNNs形成了对比,在RNNs中,输入Token被读入并按顺序处理。Self-attention使用点积计算词向量之间的相似度,由此得到的注意权重通常被可视化为一个注意权重矩阵。
注意力权重捕捉单词之间的关系强度,我们允许模型通过使用多个注意力头来学习不同类型的关系。每个注意力头通常捕捉单词之间的一种特定类型的关系(带有一些冗余)。其中一些关系是可以直观地解释的(如主-客体关系,或跟踪邻近的词),而另一些关系则相当难以理解。你可以把注意力头部想象成卷积网络中的过滤器,在卷积网络中,每个过滤器从数据中提取特定类型的特征——无论哪种特征都能帮助神经网络的其余部分做出更好的预测。
Self-attention机制是Transformer的核心操作,但让我们把它放在上下文中:Transformer最初是为机器翻译而开发的,它们有一个编码器和解码器结构。Transformer编码器和解码器的组成部分是一个Transformer块,它本身通常由一个自注意层、一定量的正则化和一个标准前馈层组成。每个块对输入向量执行这个操作序列,并将输出传递给下一个块。在Transformer中,深度是指Transformer块的数量。
根据以上的Transformer设置,BERT模型被训练在2个无监督语言任务上。BERT训练最重要的一点是它只需要无标注的数据——任何文本语料库都可以使用,你不需要任何特殊的标注数据集。BERT的论文使用了Wikipedia和一个图书语料库来训练模型。与“普通”语言模型一样,数据的成本很低,这是一个巨大的优势。
BERT是怎么训练的?
但是,是什么任务训练了BERT,使得它学习出这么好的,泛化的的语言理解? 最初的论文使用了以下两个任务:
掩码语言模型(MLM)任务。这个任务鼓励模型学习单词级和句子级的良好表示(因为句子是单词表示的整体)。简单地说,句子中15%的单词是随机选择的,并使用<MASK>来隐藏(或替代)。该模型的工作是预测这些隐藏单词的身份,利用之前和之后的单词——因此,我们试图从损坏的输入重建文本,并使用左右上下文进行预测。这使得我们能够根据上下文构建单词的表示。与ELMo(一种用于生成上下文感知的单词嵌入的基于rnn-based的语言模型)等方法不同,BERT同时学习它的双向表示,在ELMo方法中,从左到右和从右到左的表示由两个语言模型独立学习,然后连接起来。我们可以说ELMo是一个“浅层双向”模型,而BERT是一个“深层双向”模型。
下一个句子预测(NSP)任务。如果我们的模型将被用作语言理解的基础,那么它最好具备一些句子间连贯的知识。为了鼓励模型学习句子之间的关系,我们添加了下一个句子预测任务,在这个任务中,模型必须预测一对句子是否相关,也就是一个句子是否可能出现在另一个句子之后。正训练对是语料库中真实的相邻句子;从语料库中随机抽取负训练对。它不是一个完美的系统,因为随机抽样的配对可能是相关的,但它已经足够好了。
模型必须学会同时完成两项任务,因为实际的训练损失是两项任务损失的组合(MLM和NSP加权平均)。
Fine-tuning BERT
一旦训练了基本的BERT模型,你通常会在两个步骤中进行调整:首先,对未标注的数据继续进行“无监督”的训练,然后通过添加额外的层和对新目标的训练(使用很少标记的示例)来学习实际任务。这种方法起源于Dai & Le在2015年发表于的LSTM LM论文。
BERT微调实际上会更新模型的所有参数,而不仅仅是新任务特定层中的参数,因此这种方法与完全冻结传输的层参数的技术不同。
在实践中,使用BERT进行迁移学习,通常只重用经过训练的编码器堆栈—将模型的decoder扔了,只使用编码器作为特征提取器。因此,我们并不关心Transformer的decoder部分对它最初训练的语言任务所做的预测,我们感兴趣的只是模型学会在内部表示文本输入的方式。
根据任务、数据大小和TPU/GPU资源,BERT调优可能需要几分钟或几个小时。如果您有兴趣尽快尝试BERT微调,您可以在谷歌Colab上使用这个现成的代码,它提供了对免费TPU的访问。
BERT微调地址:
https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/bert_finetuning_with_cloud_tpus.ipynb
总结
我希望这篇文章对BERT现象进行了合理的概括,并展示了这个模型在NLP中是多么的流行和强大。这一领域正在迅速发展,我们现在从最先进的模型中看到的结果甚至在5年前都是不可信的(例如,回答问题时的超人表现)。最近NLP进展的两个主要趋势是转移学习和transformer的兴起,我很想知道这些在2020年将如何发展。
延伸:关于BERT进展2019几篇必读论文
1、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT论文)
谷歌BERT斩获最佳长论文!自然语言顶会NAACL2019最佳论文5篇出炉
Google NAACL2019 最佳论文
作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
摘要:本文介绍一种称为BERT的新语言表征模型,意为来自变换器的双向编码器表征量(BidirectionalEncoder Representations from Transformers)。不同于最近的语言表征模型(Peters等,2018; Radford等,2018),BERT旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的BERT表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推理)创建当前最优模型,无需对任务特定架构做出大量修改。BERT的概念很简单,但实验效果很强大。它刷新了11个NLP任务的当前最优结果,包括将GLUE基准提升至80.4%(7.6%的绝对改进)、将MultiNLI的准确率提高到86.7%(5.6%的绝对改进),以及将SQuADv1.1问答测试F1的得分提高至93.2分(1.5分绝对提高)——比人类性能还高出2.0分。
网址:
https://www.zhuanzhi.ai/paper/7acdc843627c496a2ad7fb2785357dec
BERT的slides: BERT一作Jacob Devlin斯坦福演讲PPT:BERT介绍与答疑
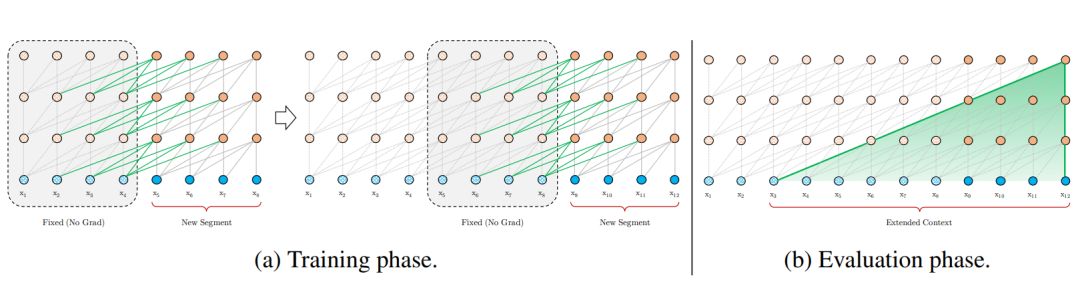
2、Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Google CMU
作者:Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov
摘要:Transformer 网络具有学习更长期依赖性的潜力,但这种潜力往往会受到语言建模中上下文长度固定的限制。因此,我们提出了一种叫做 Transformer-XL 的新神经架构来解决这一问题,它可以在不破坏时间一致性的情况下,让 Transformer 超越固定长度学习依赖性。具体来说,它是由片段级的循环机制和全新的位置编码策略组成的。我们的方法不仅可以捕获更长的依赖关系,还可以解决上下文碎片化的问题。Transformer-XL 学习到的依赖性比 RNN 学习到的长 80%,比标准 Transformer 学到的长 450%,无论在长序列还是短序列中都得到了更好的结果,而且在评估时比标准 Transformer 快 1800+ 倍。此外,我们还提升了 bpc 和困惑度的当前最佳结果,在 enwiki8 上 bpc 从 1.06 提升至 0.99,在 text8 上从 1.13 提升至 1.08,在 WikiText-103 上困惑度从 20.5 提升到 18.3,在 One Billion Word 上从 23.7 提升到 21.8,在宾州树库(不经过微调的情况下)上从 55.3 提升到 54.5。我们的代码、预训练模型以及超参数在 TensorFlow 和 PyTorch 中都可以使用。。
网址:
https://www.zhuanzhi.ai/paper/5c1ec941e06a20e4966a3db298b45211
3、XLNet: Generalized Autoregressive Pretraining for Language Understanding
Google CMU
作者:Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
摘要:由于上下文双向建模的表达能力更强,降噪自编码类型中的典型代表BERT能够比自回归语言模型取得更好的结果。即,上下文建模获得双向的信息在Language Understanding中是很重要的。但是BERT存在以下不足:(1)在输入端依赖mask的掩模的方式,遮蔽部分的输入信息。(2)忽略了被mask位置之间的依赖性。这两点在预训练-微调两个阶段存在不符。即,上述2个方面在预训练和微调这2个阶段之间都是有差异的。在正视了上述优缺点之后,本文提出一种通用(或者广义,英语原文是generalized)的自回归预训练方法:XLNet。XLNet的贡献在于(1)新的双向上下文学习方法:分解输入的顺序,对其进行排列组合,并遍历所有的排列组合,获得最大似然期望。(2)克服BERT自回归中的缺陷。XLNet在预训练中融合Transformer-XL和state-of-the-art自回归模型的优点。实验结果:XLNet在20个任务中超出了BERT,且很多是碾压式地超越。XLNet在其中18个任务中取得了目前最优结果,包括问答、自然语言推理、情感分析和文档排序。

网址:
https://www.zhuanzhi.ai/paper/74979afe231290d0c1ad43d4fab17b09
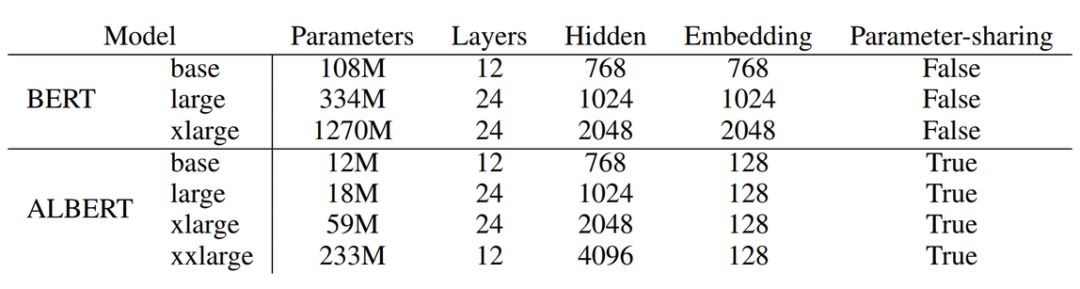
4、ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
作者:Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut
摘要:通常而言,在预训练自然语言表征时增加模型大小可以提升模型在下游任务中的性能。但在某些情况下,由于 GPU/TPU 内存限制、训练时间延长以及意外的模型退化等原因,进一步增加模型大小的难度也随之增加。所以,为了解决这些问题,来自谷歌的研究者提出通过两种参数削减(parameter-reduction)技术来降低内存消耗,加快 BERT 的训练速度。综合实验表明,ALBERT 的扩展效果要优于原始 BERT。此外,他们还使用了聚焦于句间连贯性建模的自监督损失,并证明这种损失对下游任务中的多语句输入有持续帮助。ALBERT 模型在 GLUE、RACE 和 SQuAD 基准测试上都取得了新的 SOTA 效果,并且参数量少于 BERT-large。
网址:
https://www.zhuanzhi.ai/paper/a0067ac863579c6268b0751e12decd04
更多预训练语言模型的论文请上:
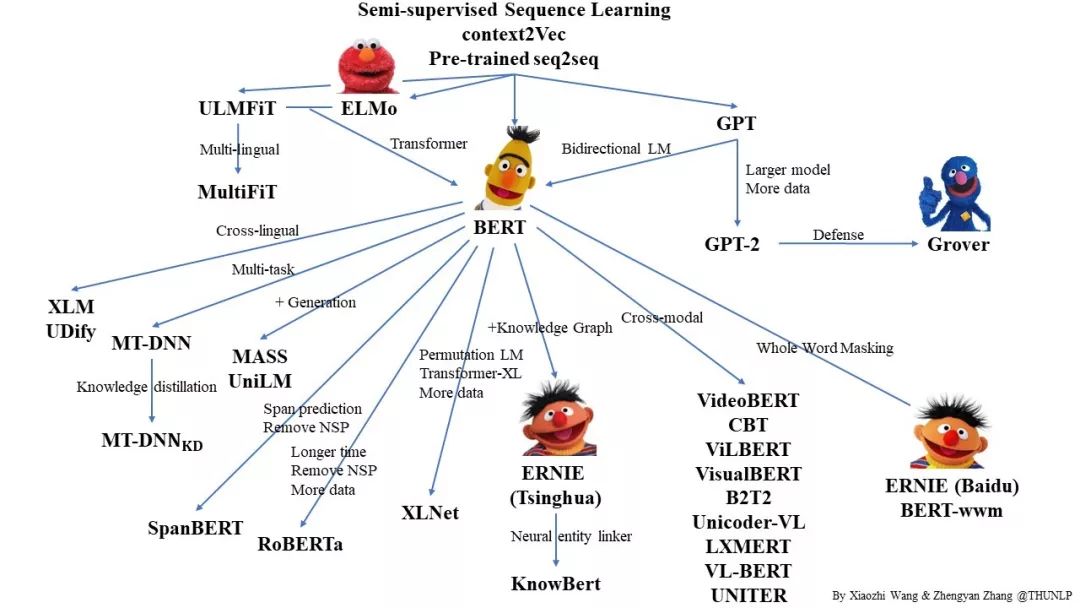
https://github.com/thunlp/PLMpapers
论文便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“BERT4” 就可以获取4篇《BERT预训练语言模型》论文专知下载链接索引


点击“阅读原文”,了解使用专知,查看5000+AI主题知识资料
展开全文



