【AlphaGo Zero 核心技术-深度强化学习教程代码实战02】理解gym的建模思想
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第五讲 不基于模型的控制
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践二 理解gym的建模思想
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
David Silver的强化学习公开课有几个特点,个人感觉首要的一个特点是偏重于讲解理论,而且有时候为了讲清楚一个理论的来龙去脉,也顺带讲了很多不常用的理论;还有一个特点是小例子很多,这些例子有时候不仅是为了讲清楚一个复杂的算法,而且通过例子会加深对一些概念的理解。同样我们在学习他的课程时,也应该注重实践,因为只有通过实践,才会对理论有更深的认识,有时候会在实践中纠正自己曾经一直自己以为正确其实是错误的认识。
本篇我们先简单尝试下怎么对强化学习中的个体、环境等进行建模,借此加深对一些概念的认识。随后我们简单介绍下热门强化学习库gym是怎么对环境及相关对象进行建模的。由于gym提供了许多强化学习经典的环境,学习者只需熟悉gym提供的接口,可以将主要精力放在个体解决强化学习问题的算法实现上,而不需自己搭建一个环境。
有了今天的基础,今后为了能够紧密贴合David的公开课,我们将模仿gym中环境类编写一个格子世界环境,来模拟其公开课中提到的一些示例,比如有风格子世界、随机行走、悬崖行走等小例子。通过这些贴合公开课的例子,相信对于初学者会相当直观。
一、强化学习问题需要描述那些内容
强化学习中最主要的两类对象是“个体”和“环境”,其次还有一些像“即时奖励”、“收获”、“状态”、“行为”、“价值”、“策略”、“学习”、“控制”等概念。这些概念把个体和环境联系起来。通过理论学习,我们知道:
1. 环境响应个体的行为。当个体执行一个行为时,它需要根据环境本身的动力学来更新环境,也包括更新个体状态,同时给以个体一个反馈信息:即时奖励。
2. 对于个体来说,它并不掌握整个环境信息,它只能通过观测来获得其可以获得的信息,它能观测到哪些信息取决于问题的难度;同样个体需要一定的行为与环境进行交互,哪些行为是被允许的,也要由个体和环境协商好。因此环境要确定个体的观测空间和行为空间。
3. 个体还应该有一个决策功能,该功能根据当前观测来判断下一时刻该采取什么行为,也就是决策过程。
4. 个体具有执行一个确定行为的功能。
5. 智能的个体应能从与环境的交互中学习到知识,进而在与环境交互时尽可能多的获取奖励,最终达到最大化累积奖励的目的。
6. 环境应该给个体设置一个(些)终止条件,即当个体处在这个状态或这些状态之一时,约定交互结束,即产生一个完整的Episode。随后重新开始一个Episode或者退出交互。
把上面的过程提炼成伪代码可以是下面这样:
class Environment():
self.states # 所有可能的状态集合
self.agent_cur_state # 记录个体当前的状态
self.observation_space # 个体的观测空间
self.action_space # 个体的行为空间
def reward(self) -> reward # 根据状态确定个体的即时奖励
def dynamics(self, action) -> None # 根据当前状态和个体的行为确定个体的新状态
def is_episode_end(self) -> Bool # 判断是否一个Episode结束
def obs_for_agent() -> obs # 环境把个体当前状态做一定变换,作为个体的观测class Agent(env: Environment):
self.env = env # 个体依附于一个环境存在
self.obs # 个体的观测
self.reward # 个体获得的即时奖励
def performPolicy(self, obs) -> action # 个体执行一个策略产生一个行为
def performAction(self, action) -> None # 个体与环境交互,执行行为
action = self.performPolicy(self.obs)
self.env.dynamics(action)
def observe(self) -> next_obs, reward # 个体得到从环境反馈来的观测和奖励
self.obs = self.env.obs_for_agent()
self.reward = self.env.reward()按照上面的设计,可以写出一个不错的个体与环境的类。但是我们不打算按照这个写下去,我们看看gym库是如何描述环境,以及个体通过什么方式与环境进行交互。
二、gym库介绍
gym的官方网址在:这里,其库代码托管地址在:这里
gym库的在设计环境以及个体的交互时基本上也是解决上述问题,但是它有它的规范和接口。gym库的核心在文件core.py里,这里定义了两个最基本的类Env和Space。前者是所有环境类的基类,后者是所有空间类的基类。从Space基类衍生出几个常用的空间类,其中最主要的是Discrete类和Box类。通过其__init__方法的参数以及其它方法的实现可以看出前者对应于一维离散空间,后者对应于多维连续空间。它们既可以应用在行为空间中,也可以用来描述状态空间,具体怎么用看问题本身。例如如果我要描述上篇提到的一个4*4的格子世界,其一共有16个状态,每一个状态只需要用一个数字来描述,这样我可以把这个问题的状态空间用Discrete(16)对象来描述就可以了。对于另外一个经典的小车爬山的问题(如下图),小车的状态是用两个变量来描述的,一个是小车对应目标旗杆的水平距离,另一个是小车的速度(是沿坡度切线方向的速率还是速度在水平方向的分量这个没仔细研究),因此环境要描述小车的状态需要2个连续的变量。由于描述小车的状态数据对个体完全可见,因此小车的状态空间即是小车的观测空间,此时再用Discrete来描述就不行了,要用Box类,Box空间可以定义多维空间,每一个维度可以用一个最低值和最大值来约束。同时小车作为个体可以执行的行为只有3个:左侧加速、不加速、右侧加速。因此行为空间可以用Discrete来描述。最终,该环境类的观测空间和行为空间描述如下:

self.min_position = -1.2self.max_position = 0.6self.max_speed = 0.07self.goal_position = 0.5 self.low = np.array([self.min_position, -self.max_speed])self.high = np.array([self.max_position, self.max_speed])self.action_space = spaces.Discrete(3)self.observation_space = spaces.Box(self.low, self.high)从这段代码可以看出,要定义一个Discrete类的空间只需要一个参数n就可以了,而定义一个多维的Box空间需要知道每一个维度的最小最大值,当然也要知道维数。
有了描述空间的对象,再来看环境类如何声明就简单的多了。先来看看代码中关于环境基类的一段解释:
class Env(object):
"""The main OpenAI Gym class. It encapsulates an environment with arbitrary behind-the-scenes dynamics. An environment can be partially or fully observed. The main API methods that users of this class need to know are: step reset render close seed When implementing an environment, override the following methods in your subclass: _step _reset _render _close _seed And set the following attributes: action_space: The Space object corresponding to valid actions observation_space: The Space object corresponding to valid observations reward_range: A tuple corresponding to the min and max possible rewards Note: a default reward range set to [-inf,+inf] already exists. Set it if you want a narrower range. The methods are accessed publicly as "step", "reset", etc.. The non-underscored versions are wrapper methods to which we may add functionality over time. """
# Override in SOME subclasses
def _close(self):
pass
# Set these in ALL subclasses
action_space = None
observation_space = None
# Override in ALL subclasses
def _step(self, action): raise NotImplementedError
def _reset(self): raise NotImplementedError
def _render(self, mode='human', close=False): return
def _seed(self, seed=None): return []看得出,个体主要通过环境的一下几个方法进行交互:step,reset,render,close,seed,而这几个都是公用方法,具体每一个方法实际调用的都是其内部方法:_step,_reset,_render,_close,_seed。此外这段描述还指出,如果你要编写自己的环境类,也主要是重写这些私有方法,同时指定该环境的观测和行为空间。_close方法可以不用重写。这几个方法主要完成的个性化功能如下:
_step: 最核心的方法,定义环境的动力学,确定个体的下一个状态、奖励信息、是否Episode终止,以及一些额外的信息,按约定,额外的信息不被允许用来训练个体。
_reset: 开启个体与环境交互前调用该方法,确定个体的初始状态以及其他可能的一些初始化设置。
_seed: 设置一些随机数的种子。
_render: 如果需要将个体与环境的交互以动画的形式展示出来的话,需要重写该方法。简单的UI设计可以用gym包装好了的pyglet方法来实现,这些方法在rendering.py文件里定义。具体使用这些方法进行UI绘制需要了解基本的OpenGL编程思想和接口,这里暂时不做细说。
可以看出,使用gym编写自己的Agent代码,需要在你的Agent类中声明一个env变量,指向对应的环境类,个体使用自己的代码产生一个行为,将该行为送入env的step方法中,同时得到观测状态、奖励值、Episode是否终止以及调试信息等四项信息组成的元组:
state, reward, is_done, info = env.step(a)state 是一个元组或numpy数组,其提供的信息维度应与观测空间的维度一样、每一个维度的具体指在制定的low与high之间,保证state信息符合这些条件是env类的_step方法负责的事情。
reward 则是根据环境的动力学给出的即时奖励,它就是一个数值。
is_done 是一个布尔变量,True或False,你可以根据具体的值来安排个体的后续动作。
info 提供的数据因环境的不同差异很大,通常它的结构是一个字典:
{"key1":data1,"key2":data2,...}获取其中的信息应该不难。
最后一点,在自己的代码中如何建立个环境类对象呢?有两种情况,一种是在gym库里注册了的对象,你只要使用下面的语句:
import gymenv = gym.make("registered_env_name")其中不同的环境类有不同的注册名,只要把make方法内的字符串改成对应的环境名就可以了。
另外一种使用自己编写的未注册的环境类,这种很简单,同一般的建立对象的语句没什么区别:
env = MyEnvClassName()相信读者已经基本清楚了如何使用gym提供的环境类了。下一步就是如何编写自己的环境类了。
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到强化学习实践三 编写通用的格子世界环境类!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
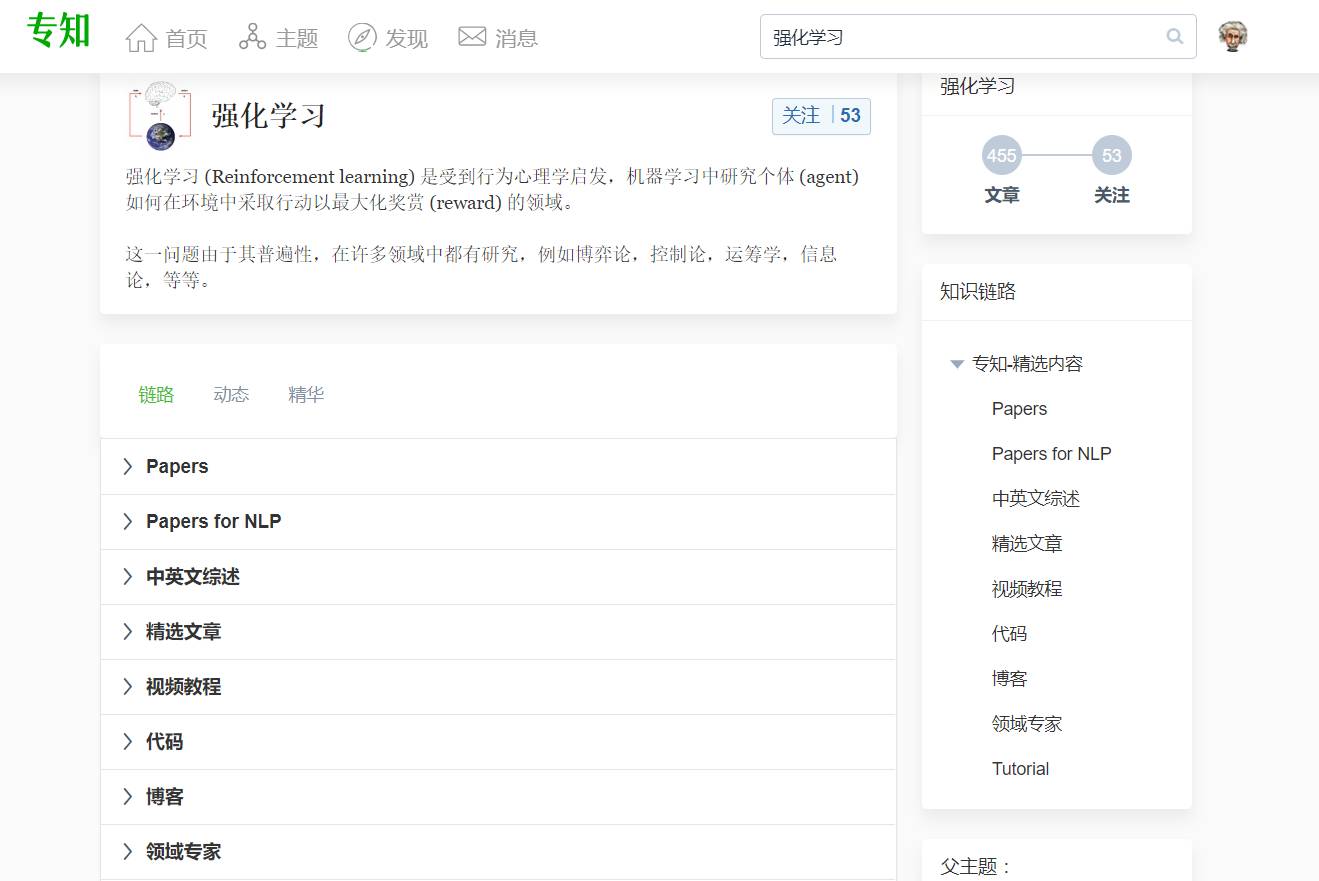
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



