【论文推荐】最新六篇机器翻译相关论文—综述、卷积Encoder-Decoder神经网络、字翻译、自编码器、神经短语、RNNs
【导读】专知内容组整理了最近六篇机器翻译(Machine Translation)相关文章,为大家进行介绍,欢迎查看!
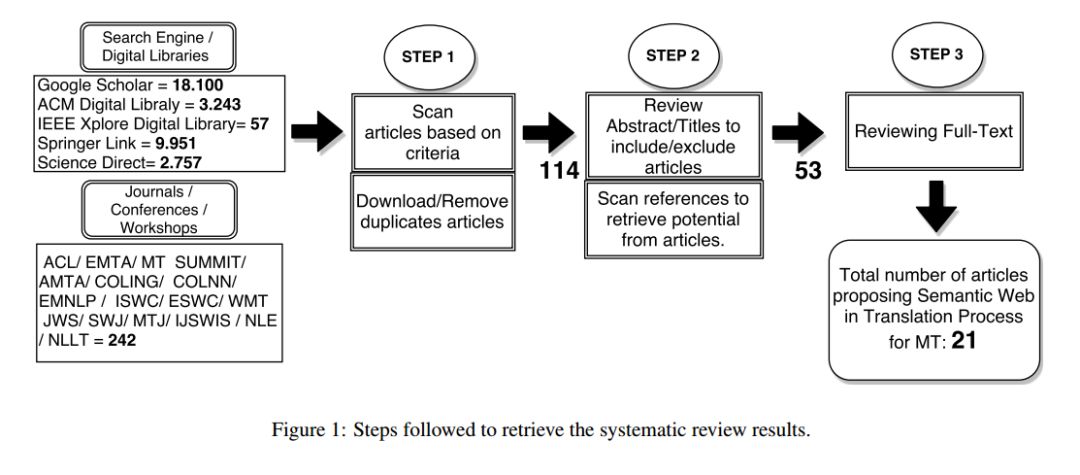
1. Machine Translation Using Semantic Web Technologies: A Survey(使用语义Web技术的机器翻译:综述)
作者:Diego Moussallem,Matthias Wauer,Axel-Cyrille Ngonga Ngomo
摘要:A large number of machine translation approaches have been developed recently with the aim of migrating content easily across languages. However, the literature suggests that many obstacles must be dealt with to achieve better automatic translations. A central issue that machine translation systems must handle is ambiguity. A promising way of overcoming this problem is using semantic web technologies. This article presents the results of a systematic review of approaches that rely on semantic web technologies within machine translation approaches for translating texts. Overall, our survey suggests that while semantic web technologies can enhance the quality of machine translation outputs for various problems, the combination of both is still in its infancy.
期刊:arXiv, 2018年2月1日
网址:
http://www.zhuanzhi.ai/document/bcd6dafe31ab36a787f959b78e6b2368
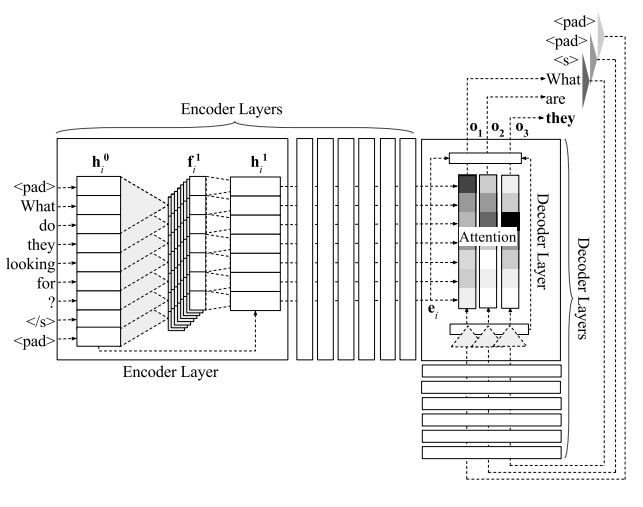
2. A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction(多层卷积Encoder-Decoder神经网络的语法错误校正)
作者:Shamil Chollampatt,Hwee Tou Ng
摘要:We improve automatic correction of grammatical, orthographic, and collocation errors in text using a multilayer convolutional encoder-decoder neural network. The network is initialized with embeddings that make use of character N-gram information to better suit this task. When evaluated on common benchmark test data sets (CoNLL-2014 and JFLEG), our model substantially outperforms all prior neural approaches on this task as well as strong statistical machine translation-based systems with neural and task-specific features trained on the same data. Our analysis shows the superiority of convolutional neural networks over recurrent neural networks such as long short-term memory (LSTM) networks in capturing the local context via attention, and thereby improving the coverage in correcting grammatical errors. By ensembling multiple models, and incorporating an N-gram language model and edit features via rescoring, our novel method becomes the first neural approach to outperform the current state-of-the-art statistical machine translation-based approach, both in terms of grammaticality and fluency.
期刊:arXiv, 2018年1月26日
网址:
http://www.zhuanzhi.ai/document/caa822579b312238bc527d955ddabf16
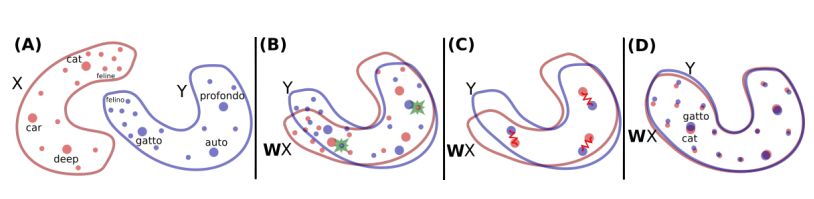
3. Word Translation Without Parallel Data(无并行数据的字翻译)
作者:Alexis Conneau,Guillaume Lample,Marc'Aurelio Ranzato,Ludovic Denoyer,Hervé Jégou
摘要:State-of-the-art methods for learning cross-lingual word embeddings have relied on bilingual dictionaries or parallel corpora. Recent studies showed that the need for parallel data supervision can be alleviated with character-level information. While these methods showed encouraging results, they are not on par with their supervised counterparts and are limited to pairs of languages sharing a common alphabet. In this work, we show that we can build a bilingual dictionary between two languages without using any parallel corpora, by aligning monolingual word embedding spaces in an unsupervised way. Without using any character information, our model even outperforms existing supervised methods on cross-lingual tasks for some language pairs. Our experiments demonstrate that our method works very well also for distant language pairs, like English-Russian or English-Chinese. We finally describe experiments on the English-Esperanto low-resource language pair, on which there only exists a limited amount of parallel data, to show the potential impact of our method in fully unsupervised machine translation. Our code, embeddings and dictionaries are publicly available.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/3cb1a972758f75404747b1fd4288bd57
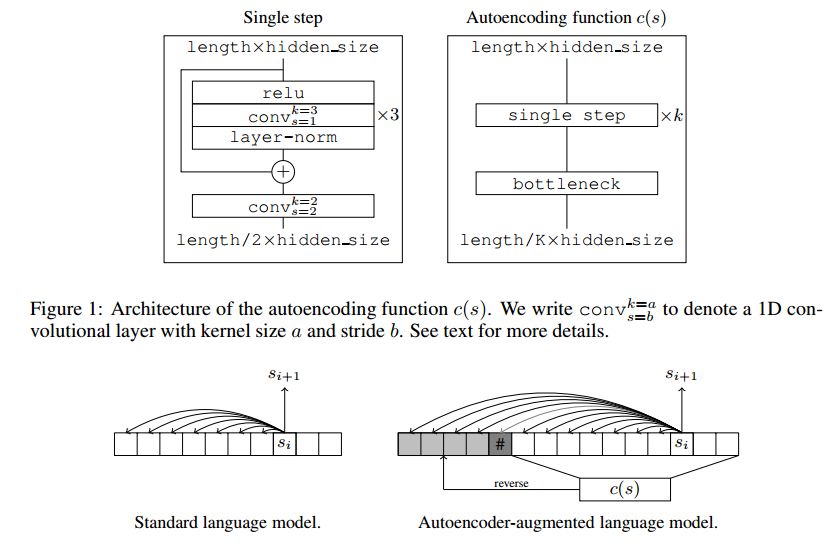
4. Discrete Autoencoders for Sequence Models(离散自编码器的序列模型)
作者:Łukasz Kaiser,Samy Bengio
摘要:Recurrent models for sequences have been recently successful at many tasks, especially for language modeling and machine translation. Nevertheless, it remains challenging to extract good representations from these models. For instance, even though language has a clear hierarchical structure going from characters through words to sentences, it is not apparent in current language models. We propose to improve the representation in sequence models by augmenting current approaches with an autoencoder that is forced to compress the sequence through an intermediate discrete latent space. In order to propagate gradients though this discrete representation we introduce an improved semantic hashing technique. We show that this technique performs well on a newly proposed quantitative efficiency measure. We also analyze latent codes produced by the model showing how they correspond to words and phrases. Finally, we present an application of the autoencoder-augmented model to generating diverse translations.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/fe80983b18aca3bb2c492a10e9287c36
5. Towards Neural Phrase-based Machine Translation(基于神经短语的机器翻译)
作者:Po-Sen Huang,Chong Wang,Sitao Huang,Dengyong Zhou,Li Deng
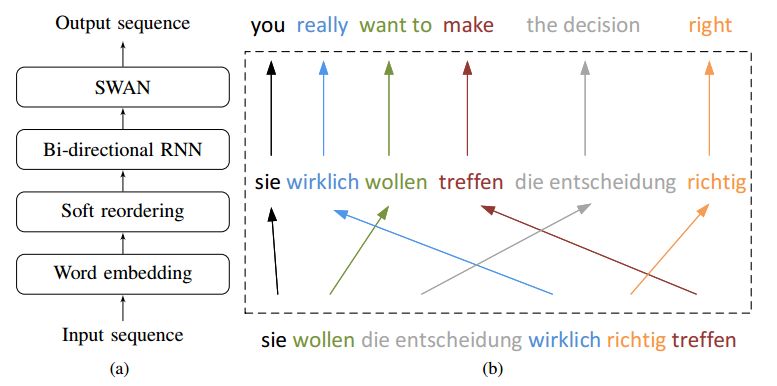
摘要:In this paper, we present Neural Phrase-based Machine Translation (NPMT). Our method explicitly models the phrase structures in output sequences using Sleep-WAke Networks (SWAN), a recently proposed segmentation-based sequence modeling method. To mitigate the monotonic alignment requirement of SWAN, we introduce a new layer to perform (soft) local reordering of input sequences. Different from existing neural machine translation (NMT) approaches, NPMT does not use attention-based decoding mechanisms. Instead, it directly outputs phrases in a sequential order and can decode in linear time. Our experiments show that NPMT achieves superior performances on IWSLT 2014 German-English/English-German and IWSLT 2015 English-Vietnamese machine translation tasks compared with strong NMT baselines. We also observe that our method produces meaningful phrases in output languages.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/9440528ac5ff943a94076c8f0c44e5fe
6. SEARNN: Training RNNs with Global-Local Losses(SEARNN: 全局-局部损失的RNNs训练)
作者:Rémi Leblond,Jean-Baptiste Alayrac,Anton Osokin,Simon Lacoste-Julien
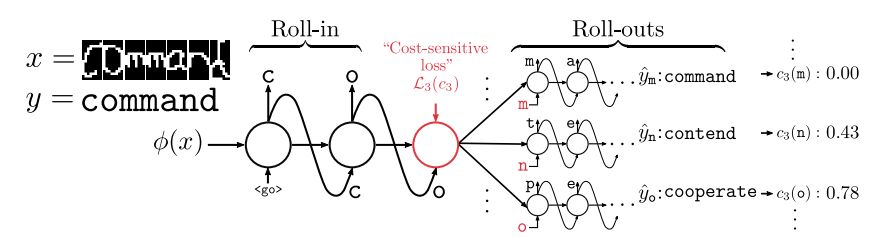
摘要:We propose SEARNN, a novel training algorithm for recurrent neural networks (RNNs) inspired by the "learning to search" (L2S) approach to structured prediction. RNNs have been widely successful in structured prediction applications such as machine translation or parsing, and are commonly trained using maximum likelihood estimation (MLE). Unfortunately, this training loss is not always an appropriate surrogate for the test error: by only maximizing the ground truth probability, it fails to exploit the wealth of information offered by structured losses. Further, it introduces discrepancies between training and predicting (such as exposure bias) that may hurt test performance. Instead, SEARNN leverages test-alike search space exploration to introduce global-local losses that are closer to the test error. We first demonstrate improved performance over MLE on two different tasks: OCR and spelling correction. Then, we propose a subsampling strategy to enable SEARNN to scale to large vocabulary sizes. This allows us to validate the benefits of our approach on a machine translation task.
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/34ff9ebef7e6d6cd6f887ab10588bec1
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



