【论文推荐】最新5篇图像分割相关论文—条件随机场和深度特征学习、移动端网络、长期视觉定位、主动学习、主动轮廓模型、生成对抗性网络
【导读】专知内容组整理了最近五篇视觉图像分割(Image Segmentation)相关文章,为大家进行介绍,欢迎查看!
1. Conditional Random Field and Deep Feature Learning for Hyperspectral Image Segmentation(基于条件随机场和深度特征学习的高光谱图像分割)
作者:Fahim Irfan Alam,Jun Zhou,Alan Wee-Chung Liew,Xiuping Jia,Jocelyn Chanussot,Yongsheng Gao
摘要:Image segmentation is considered to be one of the critical tasks in hyperspectral remote sensing image processing. Recently, convolutional neural network (CNN) has established itself as a powerful model in segmentation and classification by demonstrating excellent performances. The use of a graphical model such as a conditional random field (CRF) contributes further in capturing contextual information and thus improving the segmentation performance. In this paper, we propose a method to segment hyperspectral images by considering both spectral and spatial information via a combined framework consisting of CNN and CRF. We use multiple spectral cubes to learn deep features using CNN, and then formulate deep CRF with CNN-based unary and pairwise potential functions to effectively extract the semantic correlations between patches consisting of three-dimensional data cubes. Effective piecewise training is applied in order to avoid the computationally expensive iterative CRF inference. Furthermore, we introduce a deep deconvolution network that improves the segmentation masks. We also introduce a new dataset and experimented our proposed method on it along with several widely adopted benchmark datasets to evaluate the effectiveness of our method. By comparing our results with those from several state-of-the-art models, we show the promising potential of our method.
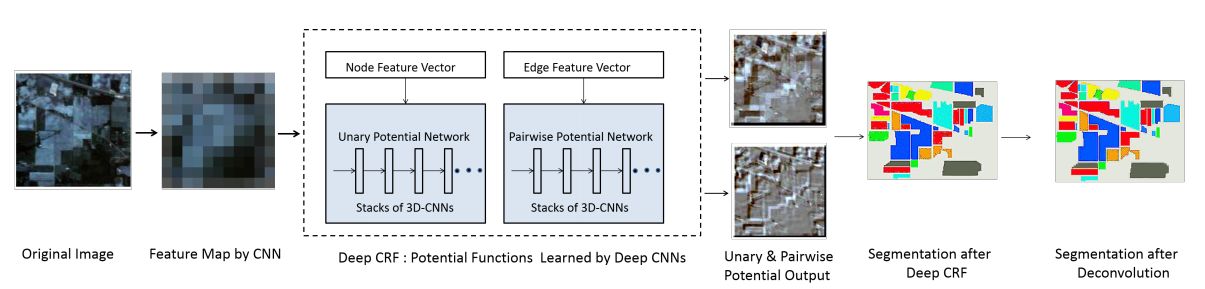
期刊:arXiv, 2017年12月27日
网址:
http://www.zhuanzhi.ai/document/0d0b73aec22f09677393117c0e5af8d9
2. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation(反向残差和线性瓶颈:用于分类、检测和分割的移动端网络)
作者:Mark Sandler,Andrew Howard,Menglong Zhu,Andrey Zhmoginov,Liang-Chieh Chen
摘要:In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
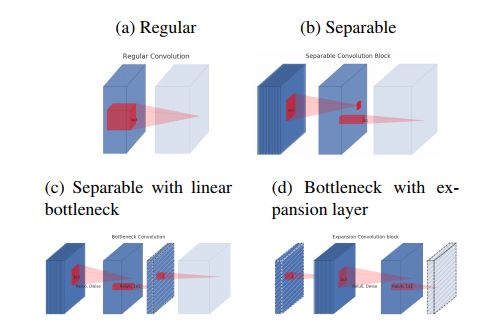
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/2826d6b1ed70d86a9735a8217f2a93d8
3. Long-term Visual Localization using Semantically Segmented Images(基于用语义分割图像的长期视觉定位)
作者:Erik Stenborg,Carl Toft,Lars Hammarstrand
摘要:Robust cross-seasonal localization is one of the major challenges in long-term visual navigation of autonomous vehicles. In this paper, we exploit recent advances in semantic segmentation of images, i.e., where each pixel is assigned a label related to the type of object it represents, to solve the problem of long-term visual localization. We show that semantically labeled 3D point maps of the environment, together with semantically segmented images, can be efficiently used for vehicle localization without the need for detailed feature descriptors (SIFT, SURF, etc.). Thus, instead of depending on hand-crafted feature descriptors, we rely on the training of an image segmenter. The resulting map takes up much less storage space compared to a traditional descriptor based map. A particle filter based semantic localization solution is compared to one based on SIFT-features, and even with large seasonal variations over the year we perform on par with the larger and more descriptive SIFT-features, and are able to localize with an error below 1 m most of the time.

期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/2fb9a8783cdec3cf3d23cd730912d49b
4. Geometry in Active Learning for Binary and Multi-class Image Segmentation(基于主动学习中几何知识的二元和多类图像分割)
作者:Ksenia Konyushkova,Raphael Sznitman,Pascal Fua
摘要:We propose an Active Learning approach to image segmentation that exploits geometric priors to streamline the annotation process. We demonstrate this for both background-foreground and multi-class segmentation tasks in 2D images and 3D image volumes. Our approach combines geometric smoothness priors in the image space with more traditional uncertainty measures to estimate which pixels or voxels are most in need of annotation. For multi-class settings, we additionally introduce two novel criteria for uncertainty. In the 3D case, we use the resulting uncertainty measure to show the annotator voxels lying on the same planar patch, which makes batch annotation much easier than if they were randomly distributed in the volume. The planar patch is found using a branch-and-bound algorithm that finds a patch with the most informative instances. We evaluate our approach on Electron Microscopy and Magnetic Resonance image volumes, as well as on regular images of horses and faces. We demonstrate a substantial performance increase over state-of-the-art approaches.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/a53ced6fa7639528fa3913a8a9bf9c65
5. IEOPF: An Active Contour Model for Image Segmentation with Inhomogeneities Estimated by Orthogonal Primary Functions(利用正交主要函数进行不均匀性图像分割的主动轮廓模型估计)
作者:Chaolu Feng
摘要:Image segmentation is still an open problem especially when intensities of the interested objects are overlapped due to the presence of intensity inhomogeneity (also known as bias field). To segment images with intensity inhomogeneities, a bias correction embedded level set model is proposed where Inhomogeneities are Estimated by Orthogonal Primary Functions (IEOPF). In the proposed model, the smoothly varying bias is estimated by a linear combination of a given set of orthogonal primary functions. An inhomogeneous intensity clustering energy is then defined and membership functions of the clusters described by the level set function are introduced to rewrite the energy as a data term of the proposed model. Similar to popular level set methods, a regularization term and an arc length term are also included to regularize and smooth the level set function, respectively. The proposed model is then extended to multichannel and multiphase patterns to segment colourful images and images with multiple objects, respectively. It has been extensively tested on both synthetic and real images that are widely used in the literature and public BrainWeb and IBSR datasets. Experimental results and comparison with state-of-the-art methods demonstrate that advantages of the proposed model in terms of bias correction and segmentation accuracy.
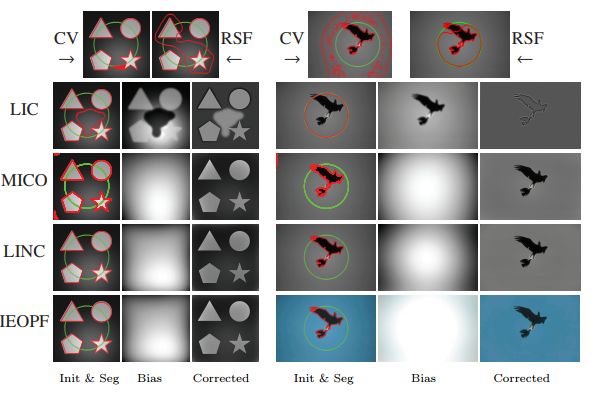
期刊:arXiv, 2018年1月20日
网址:
http://www.zhuanzhi.ai/document/11cd79ce6bba739baa1a98b2d4a0564c
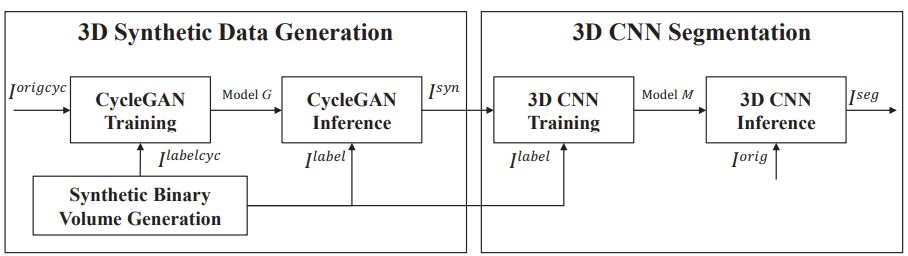
6. Fluorescence Microscopy Image Segmentation Using Convolutional Neural Network With Generative Adversarial Networks(基于卷积神经网络与生成的对抗性网络的荧光显微图像分割)
作者:Chichen Fu,Soonam Lee,David Joon Ho,Shuo Han,Paul Salama,Kenneth W. Dunn,Edward J. Delp
摘要:Recent advance in fluorescence microscopy enables acquisition of 3D image volumes with better quality and deeper penetration into tissue. Segmentation is a required step to characterize and analyze biological structures in the images. 3D segmentation using deep learning has achieved promising results in microscopy images. One issue is that deep learning techniques require a large set of groundtruth data which is impractical to annotate manually for microscopy volumes. This paper describes a 3D nuclei segmentation method using 3D convolutional neural networks. A set of synthetic volumes and the corresponding groundtruth volumes are generated automatically using a generative adversarial network. Segmentation results demonstrate that our proposed method is capable of segmenting nuclei successfully in 3D for various data sets.
期刊:arXiv, 2018年1月23日
网址:
http://www.zhuanzhi.ai/document/9fdb6962bd4223b7ad1e6d818a0a304c
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



