【观点】AlphaGo Zero再掀波澜,看各位AI业界大拿如何点评
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文AlphaGo Zero,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。来看一看AI业界大拿如何点评。
David Silver,AlphaGo之父
David Silver DeepMind首席研究员、AlphaGo项目负责人David Silver 和Julian Schrittwieser(AlphaGo Zero论文的第一作者之一)在Reddit回答网友提问。Silver从AlphaGo诞生前起(这个后面会说),到现在的最强版本AlphaGo Zero,一直在用深度强化学习攻克围棋,用“AlphaGo之父”来形容他一点也不为过.
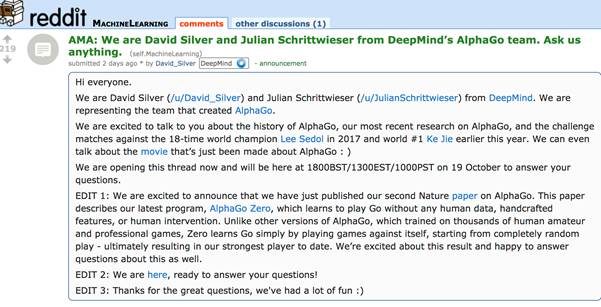
Reddit在前天发布了预告,DeepMind的David Silver和Julian Schrittwieser(见头图)会举行一场AMA——“Ask Me Anything”.
问:为什么 AlphaGoZero 的训练这么稳定?这是如何做到的?当DeepMind宣布它在尝试纯self-play训练时,这是每个人都想问的问题。因为深度强化学习是出了名的不稳定和容易遗忘,如果没有一个好的(基于模拟的)初始设定和大量的历史checkpoint,这两点加在一起会是灾难。但是如果我没有理解错的话,Zero是从零开始的,你们没有使用任何历史checkpoint来作为防止遗忘或循环的对抗。但是这篇论文根本没有讨论这个问题,你们是怎么做到的?
DavidSilver:AlphaGoZero没有使用典型的(model-free的)算法,例如策略梯度或Q-learning,而是使用了一种完全不同的方法。通过使用 AlphaGosearch,我们极大地改进了策略和自我对弈的结果,然后我们应用简单的、基于梯度的更新来训练下一个策略+价值网络(policy+value network)。这比渐进的、基于梯度的策略改进(policyimprovement)更稳定,而那样的策略改进可能会遗忘先前的改进。
问:你觉得AlphaGo能够解决被称为“史上最难死活题”的《围棋发阳论》第120题吗?(http://igohatsuyoron120.de/2015/0039.htm)
DavidSilver:我问了Fan Hui这个问题,他说,AlphaGo能够解决这个死活题,但更有趣的是问题,AlphaGo会找到书里的解决方法,还是得到没有任何人想到过的另一种解决方法?在AlphaGo下过的棋局中,我们已经看到过许多这种没有人想到过的新下法。
问:为什么在40天时就停止了训练呢?它的性能还可以更强,不是吗?如果你让它运行3个月,会发生什么?
DavidSilver:我想这是一个事关人力、资源和优先事项的问题。如果我们跑了3个月,我猜你还是会问,训练6个月的话会发生什么?
问:不读研也能在人工智能领域里取得成功吗?
JulianSchrittwieser:绝对没问题,我自己就只有计算机科学的学士学位。AI领域发展非常迅速,你能从读论文、做实验中学到很多。进入一家在机器学习领域有业务经验的公司也有很大帮助。
问:鉴于你们(DeepMind)和Facebook几乎在同一时间开始研究围棋的问题,你认为是什么优势让你们的系统能够在如此短的时间内达到大师级的标准?
DavidSilver:Facebook更侧重监督学习,他们的程序在当时是最强大的之一。我们选择更多地关注强化学习,因为我们认为这最终能带领我们超越人类的知识。我们最近的研究结果实际上表明,仅使用监督式的方法能够获得令人惊讶的高性能表现,但是,如果要远超人类水平,强化学习绝对是关键。
问:AlphaGo有开源的计划吗?
DavidSilver:我们在过去已经开源了许多代码,但这始终是一个复杂的过程。在AlphaGo情况下,不幸的是,它是一个非常非常复杂的代码库。
Demis Hassabis, Google DeepMind CEO
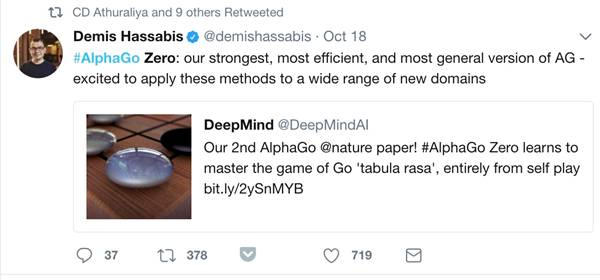
DemisHassabis: 表示以后会将AlphaGoZero中的新技术应用到更多的领域。
Karpathy, 特斯拉AI主管
拥有斯坦福大学计算机视觉博士学位,读博期间师从李飞飞,研究神经网络在计算机视觉、自然语言处理上的应用,以及在这两个领域的交叉应用。 读博期间,他在Google Research实习了两个暑假,还曾在DeepMind实习。

PedroDomingos, 华盛顿大学计算机科学与工程学教授
华盛顿大学计算机科学与工程学教授,也是国际机器学习协会的联合创始人之一。他曾在ISTLisbon获得电子工程和计算科学的硕士学位,在加州大学Irvine分校获得信息与计算科学博士学位。而后在IST作为助理教授工作了两年,于1999年加入华盛顿大学。他还是SIGKDD创新奖获得者(数据科学领域中最高奖项),也是AAAI Fellow之一。

周志华,南京大学计算机系教授

花半小时看了下文章,说点个人浅见,未必正确仅供批评:
1. 别幻想什么无监督学习,监督信息来自精准规则,非常强的监督信息。
2. 不再把围棋当作从数据中学习的问题,回归到启发式搜索这个传统棋类解决思路。这里机器学习实质在解决搜索树启发式评分函数问题。
3. 如果说深度学习能在模式识别应用中取代人工设计特征,那么这里显示出强化学习能在启发式搜索中取代人工设计评分函数。这个意义重大。启发式搜索这个人工智能传统领域可能因此巨变,或许不亚于模式识别计算机视觉领域因深度学习而产生的巨变。机器学习进一步蚕食其他人工智能技术领域。
4. 类似想法以往有,但常见于小规模问题。没想到围棋这种状态空间巨大的问题其假设空间竟有强烈的结构,存在统一适用于任意多子局面的评价函数。巨大的状态空间诱使我们自然放弃此等假设,所以这个尝试相当大胆。
5. 工程实现能力超级强,别人即便跳出盲点,以启发式搜索界的工程能力也多半做不出来。
6. 目前并非普适,只适用于状态空间探索几乎零成本且探索过程不影响假设空间的任务。
周志华教授现任南京大学计算机系副主任、软件新技术国家重点实验室常务副主任,主要从事人工智能、机器学习与数据挖掘领域的研究,著有《Ensemble Methods: Foundations and Algorithms》《机器学习》等,是在人工智能相关的五大主流国际学会(ACM、AAAI、IEEE、AAAS、IAPR)均入选Fellow的首位华人学者,也是被人工智能领域两大顶级国际学术会议AAAI、IJCAI均聘任为程序委员会主席的首位华人学者,在该领域有重要影响力。
孙剑,ResNet作者,

田渊栋, Facebook AI 研究员
老实说这篇Nature要比上一篇好很多,方法非常干净标准,结果非常好,以后肯定是经典文章了。
Policy network和value network放在一起共享参数不是什么新鲜事了,基本上现在的强化学习算法都这样做了,包括我们这边拿了去年第一名的Doom Bot,还有ELF里面为了训练微缩版星际而使用的网络设计。另外我记得之前他们已经反复提到用Value network对局面进行估值会更加稳定,所以最后用完全不用人工设计的defaultpolicy rollout也在情理之中。
让我非常吃惊的是仅仅用了四百九十万的自我对局,每步仅用1600的MCTS rollout,Zero就超过了去年三月份的水平。并且这些自我对局里有很大一部分是完全瞎走的。这个数字相当有意思。想一想围棋所有合法状态的数量级是10^170(见Counting Legal Positions in Go),五百万局棋所能覆盖的状态数目也就是10^9这个数量级,这两个数之间的比例比宇宙中所有原子的总数还要多得多。仅仅用这些样本就能学得非常好,只能说明卷积神经网络(CNN)的结构非常顺应围棋的走法,说句形象的话,这就相当于看了大英百科全书的第一个字母就能猜出其所有的内容。用ML的语言来说,CNN的inductivebias(模型的适用范围)极其适合围棋漂亮精致的规则,所以稍微给点样本水平就上去了。反观人类棋谱有很多不自然的地方,CNN学得反而不快了。我们经常看见跑KGS或者GoGoD的时候,最后一两个百分点费老大的劲,也许最后那点时间完全是花费在过拟合奇怪的招法上。
如果这个推理是对的话,那么就有几点推断。一是对这个结果不能过分乐观。我们假设换一个问题(比如说protein folding),神经网络不能很好拟合它而只能采用死记硬背的方法,那泛化能力就很弱,Self-play就不会有效果。事实上这也正是以前围棋即使用Self-play都没有太大进展的原因,大家用手调特征加上线性分类器,模型不对路,就学不到太好的东西。一句话,重点不在左右互搏,重点在模型对路。
二是或许卷积神经网络(CNN)系列算法在围棋上的成功,不是因为它达到了围棋之神的水平,而是因为人类棋手也是用CNN的方式去学棋去下棋,于是在同样的道路上,或者说同样的inductive bias下,计算机跑得比人类全体都快得多。假设有某种外星生物用RNN的方式学棋,换一种inductive bias,那它可能找到另一种(可能更强的)下棋方式。Zero用CNN及ResNet的框架在自学习过程中和人类世界中围棋的演化有大量的相似点,在侧面上印证了这个思路。在这点上来说,说穷尽了围棋肯定是还早。
三就是更证明了在理论上理解深度学习算法的重要性。对于人类直觉能触及到的问题,机器通过采用有相同或者相似的inductive bias结构的模型,可以去解决。但是人不知道它是如何做到的,所以除了反复尝试之外,人并不知道如何针对新问题的关键特性去改进它。如果能在理论上定量地理解深度学习在不同的数据分布上如何工作,那么我相信到那时我们回头看来,针对什么问题,什么数据,用什么结构的模型会是很容易的事情。我坚信数据的结构是解开深度学习神奇效果的钥匙。
另外推测一下为什么要用MCTS而不用强化学习的其它方法(我不是DM的人,所以肯定只能推测了)。MCTS其实是在线规划(online planning)的一种,从当前局面出发,以非参数方式估计局部Q函数,然后用局部Q函数估计去决定下一次rollout要怎么走。既然是规划,MCTS的限制就是得要知道环境的全部信息,及有完美的前向模型(forward model),这样才能知道走完一步后是什么状态。围棋因为规则固定,状态清晰,有完美快速的前向模型,所以MCTS是个好的选择。但要是用在Atari上的话,就得要在训练算法中内置一个Atari模拟器,或者去学习一个前向模型(forward model),相比actor-critic或者policy gradient可以用当前状态路径就地取材,要麻烦得多。但如果能放进去那一定是好的,像Atari这样的游戏,要是大家用MCTS我觉得可能不用学policy直接当场planning就会有很好的效果。很多文章都没比,因为比了就不好玩了。
另外,这篇文章看起来实现的难度和所需要的计算资源都比上一篇少很多,我相信过不了多久就会有人重复出来,到时候应该会有更多的insight。大家期待一下吧。
田渊栋,Facebook 人工智能研究院研究员,Facebook 围棋 AI程序 DarkForest 首席工程师及第一作者,卡耐基梅隆大学机器人研究所博士,曾担任 Google 无人驾驶团队软件工程师,并获得国际计算机视觉大会(ICCV)马尔奖荣誉提名。
马少平:清华大学计算机学院教授
http://blog.sina.com.cn/s/blog_73040b820102x2j6.html
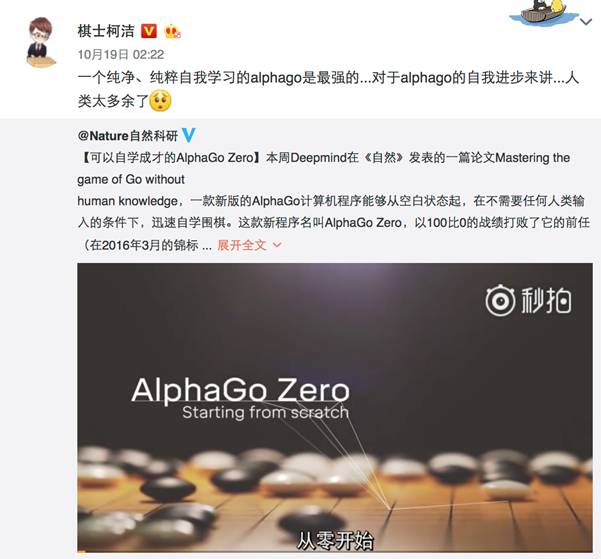
从早上开始,就被AlphaGoZero的消息刷屏了,DeepMind公司最新的论文显示,最新版本的AlphaGo,完全抛弃了人类棋谱,实现了从零开始学习。
对于棋类问题来说,在蒙特卡洛树搜索的框架下,实现从零开始学习,我一直认为是可行的,也多次与别人讨论这个问题,当今年初Master推出时,就曾预测这个新系统可能实现了从零开始学习,可惜根据DeepMind后来透露的消息,Master并没有完全抛弃人类棋谱,而是在以前系统的基础上,通过强化学习提高系统的水平,虽然人类棋谱的作用越来越弱,但是启动还是学习了人类棋谱,并没有实现“冷”启动。
根据DeepMind透露的消息,AlphaGo Zero不但抛弃了人类棋谱,实现了从零开始学习,连以前使用的人类设计的特征也抛弃了,直接用棋盘上的黑白棋作为输入,可以说是把人类抛弃的彻彻底底,除了围棋规则外,不使用人类的任何数据和知识了。仅通过3天训练,就可以战胜和李世石下棋时的AlphaGo,而经过40天的训练后,则可以打败与柯洁下棋时的AlphaGo了。
真是佩服DeepMind的这种“把革命进行到底”的作风,可以说是把计算机围棋做到了极致。
那么AlphaGo Zero与AlphaGo(用AlphaGo表示以前的版本)都有哪些主要的差别呢?
1,在训练中不再依靠人类棋谱。AlphaGo在训练中,先用人类棋谱进行训练,然后再通过自我互博的方法自我提高。而AlphaGo Zero直接就采用自我互博的方式进行学习,在蒙特卡洛树搜索的框架下,一点点提高自己的水平。
2,不再使用人工设计的特征作为输入。在AlphaGo中,输入的是经过人工设计的特征,每个落子位置,根据该点及其周围的棋的类型(黑棋、白棋、空白等)组成不同的输入模式。而AlphaGo Zero则直接把棋盘上的黑白棋作为输入。这一点得益于后边介绍的神经网络结构的变化,使得神经网络层数更深,提取特征的能力更强。
3,将策略网络和价值网络合二为一。在AlphaGo中,使用的策略网络和价值网络是分开训练的,但是两个网络的大部分结构是一样的,只是输出不同。在AlphaGo Zero中将这两个网络合并为一个,从输入到中间几层是共用的,只是后边几层到输出层是分开的。并在损失函数中同时考虑了策略和价值两个部分。这样训练起来应该会更快吧?
4,网络结构采用残差网络,网络深度更深。AlphaGo Zero在特征提取层采用了多个残差模块,每个模块包含2个卷积层,比之前用了12个卷积层的AlphaGo深度明显增加,从而可以实现更好的特征提取。
5,不再使用随机模拟。在AlphaGo中,在蒙特卡洛树搜索的过程中,要采用随机模拟的方法计算棋局的胜率,而在AlphaGo Zero中不再使用随机模拟的方法,完全依靠神经网络的结果代替随机模拟。这应该完全得益于价值网络估值的准确性,也有效加快了搜索速度。
6,只用了4块TPU训练72小时就可以战胜与李世石交手的AlphaGo。训练40天后可以战胜与柯洁交手的AlphaGo。
对于计算机围棋来说,以上改进无疑是个重要的突破,但也要正确认识这些突破。比如,之所以可以实现从零开始学习,是因为棋类问题的特点所决定的,是个水到渠成的结果。因为棋类问题一个重要的特性就是可以让机器自动判别最终结果的胜负,这样才可以不用人类数据,自己实现产生数据,自我训练,自我提高下棋水平。但是这种方式很难推广到其他领域,不能认为人工智能的数据问题就解决了。
马毅

马毅,1995年获清华大学自动化系与数学系双学位,后赴美国加利福尼亚大学伯克利分校求学。毕业后在美国伊利诺伊大学香槟分校任教,并成为该校电气与计算机工程系历史上最年轻的副教授。2009年任微软亚洲研究院视觉计算组高级研究员。2014年全职加入上海科技大学信息科学与技术学院。2017年10月15日,在个人微博上表示,已正式决定接受美国加州大学伯克利分校电子工程与计算机系的教职,“年初入职”。
柯洁
2014年8月,柯洁在gorating世界围棋等级分排名中首次排名第一,截至2017年8月,已连续三年排名人类围棋世界第一。
王小川

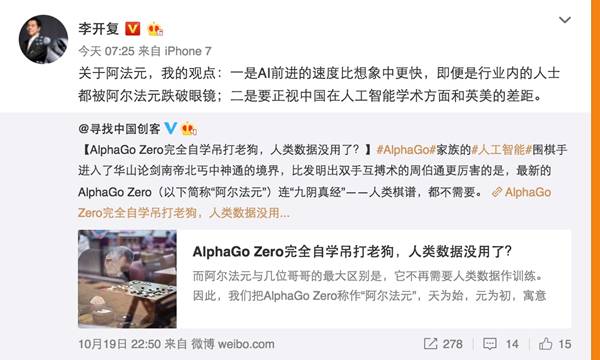
李开复
周鸿祎

扫一扫小助手,加入专知AI群,讨论交流!~

欢迎转发分享到微信群和朋友圈!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



