Tensorflow 2.0图片分类入门实战
【导读】从房价预测,音乐识别到人脸检测,神经网络正在渗透数据科学领域,成为现代数据科学家工具箱中的必备工具。神经网络不仅可用于解决高度复杂的问题,在处理较大的数据集时,它们还具有比普通算法更高的计算能力和更高的性能。此外,最近发布的Tensorflow 2.0能够帮助初学者轻松学习如何构建模型。
作者|Jagerynn Ting Verano
我们将通过猫/狗数据集分类任务,建立深度学习模型。好模型的标准是高精度,还有多类分类,例如区分不同的狗种,感兴趣的学习者可以在覆盖基础后深入研究。但为简单起见,我们将解决二进制分类问题。
对深层模型的需求
虽然深度学习和神经网络可以互换使用,但它们并不相同。与浅模型相反,深度模型在网络中隐藏了更多层。
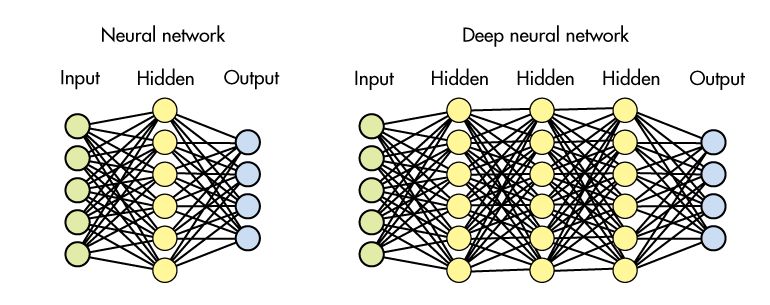
通常,更多层意味着可以从数据中提取更多信息。 在语音识别的情况下,第一层可以拾取诸如白噪声之类的简单事物,而第三层或第四层拾取诸如单词之类的更精细的细节,并且最终机器能够组合短语和完整句子。
与浅而大的网络相比,具有较小隐藏层的更大深度也被认为在计算上更不昂贵。 随着我们的进展,我们将更多地涉及这些问题。
猫 vs 狗数据集简介

训练、验证数据集下载地址:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
由于数据帧很好用,我将训练和验证数据集转换为数据帧。 这可以通过创建两个列表来完成:一个是文件名,另一个是猫和狗的相应标签。
animal = []train_cat_fnames2 = []for cat in train_cat_fnames: #do the same for dog file namesanimal.append(“cat”)cat2 = train_cats_dir + "/" + cat #create absolute pathtrain_cat_fnames2.append(cat2)train_df = pd.DataFrame() #create dataframetrain_df[“filename”] = test_dog_fnames2+test_cat_fnames2train_df[“animal”] = animal
通过matplotlib进行绘图还可以可视化每个样例,如下所示:
#pass absolute file through load_imgimage = load_img(train_df[“filename”][0])plt.imshow(image)
预处理
图像数据生成器将图像转换为数字阵列,这些数组将被馈送到模型。 对于彩色图像的数据集,必须考虑RGB系数。 这些系数的范围为0-255,通过将它们除以255,数据被重新调整为0到1之间的范围。
数据通过批次馈送到神经网络。 可以使用flow_from_dataframe()创建批量的增强数据。 在这里,我指定批量大小为20,类模式为二进制。
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale = 1/255)train_generator = train_datagen.flow_from_dataframe(train_df, x_col='filename', y_col='animal', target_size=(100,100), #images resizedbatch_size=20,class_mode='binary')构建我们的第一个模型

卷积和池化层
当使用神经网络(NN)时,必然会遇到像1-D,2-D甚至3-D卷积层这样的术语。 1-D NN用于自然语言处理和音频信号处理等情况,而2-D NN通常用于图像识别问题。 但是,人们可以自由地打破这些习俗。
我将卷积层比作人类感知,或者我们看到世界的镜头:它们是小方形滤镜,可以滑过数据(以矩阵的形式)并在其中寻找图案。 对于数组的每个区域,返回一个值。
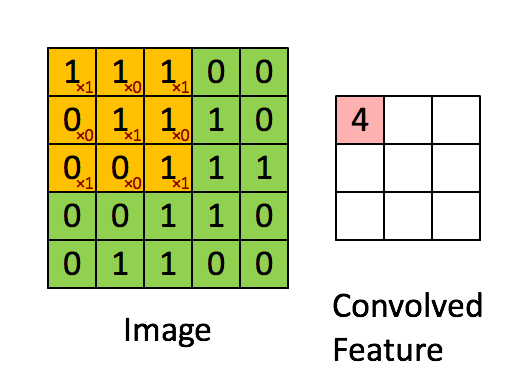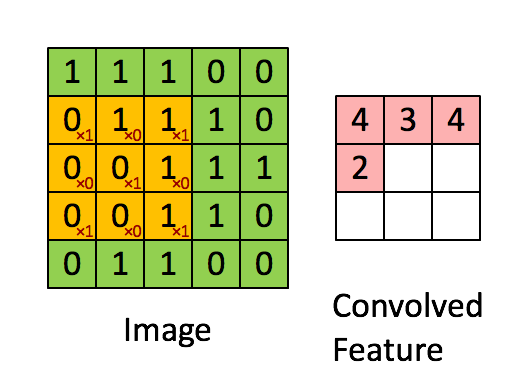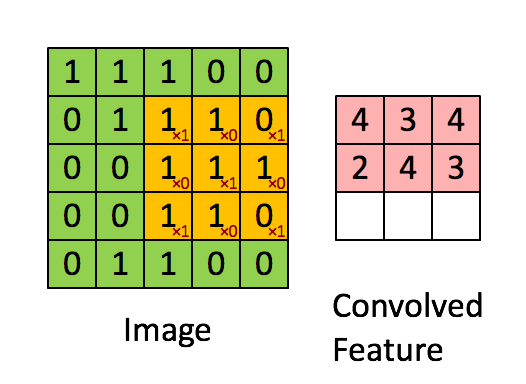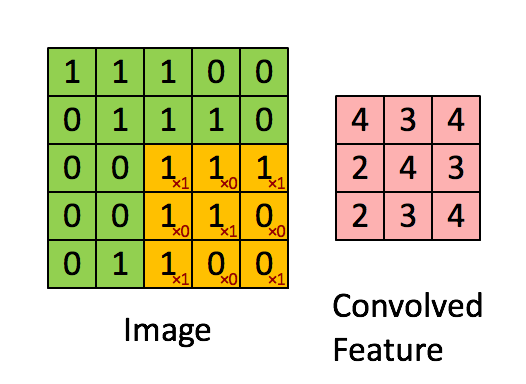
最大和平均池化层以减少总体维度。 它们通常插在卷积层之间。 如果卷积层返回的值高于某个阈值,则池化层将指示卷积层的该区域存在模式(例如,角落)。
为了更容易开始构建,Keras在Sequential模型指南下生成了示例代码片段。 我使用类似VGG的小行星作为我的起点,并对其进行了调整。 我的模型中的代码块看起来像这样:
model = tf.keras.models.Sequential()model.add(tf.keras.layers.Conv2D(16, (3, 3), strides = 1, activation='relu', input_shape=(100, 100, 3)))model.add(tf.keras.layers.BatchNormalization())model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides = 2))model.add(tf.keras.layers.Dropout(0.25))
从上面的代码可以看出,调用Sequential模型,添加卷积层,然后添加批量标准化层,然后汇集,最后指定丢失率。
在第二行中,16个尺寸为3 x 3的小方形滤镜或透镜贯穿每个图像寻找图案。
“ReLU”激活功能是应用于输入的函数,该输入在调用它的层处变换输入。它是迄今为止最常用的激活功能,如果您遇到困难并想知道选择哪一个,那么这是一个很好的选择。
激活函数
Keras提供了许多线性和非线性激活功能。
ReLU代表整流学习单元,将任何负值转换为0,同时保留之前的非负值。因此,ReLU功能的任何输出范围将从0到1.
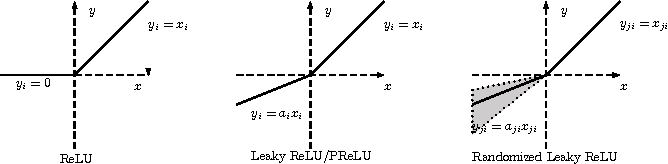
另一个有用的非线性函数是tanh。 通过tanh函数运行输入数据将其重新定义为0并允许其y值整齐地落在-1和1之间。因此,它也优于sigmoid函数。
sigmoid函数输出0到1之间的值,因此通常堆叠为二进制分类问题中的最后一层。
批量标准化
在深度神经网络中,在应用多个激活函数后,我们的输入范围会发生显着变化。 因此,在卷积层之后添加归一化层通常是个好主意。 批量标准化已被证明可以提高神经网络的效率并减少训练成功模型所需的时期数量。
Dropout
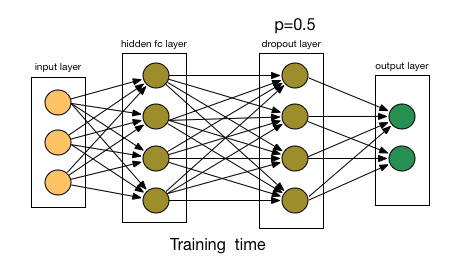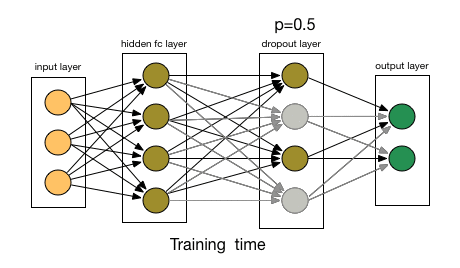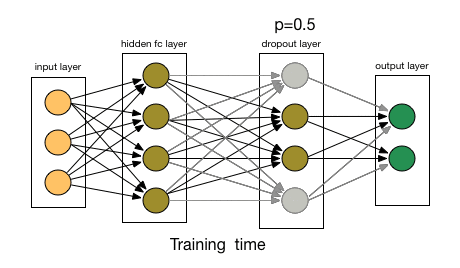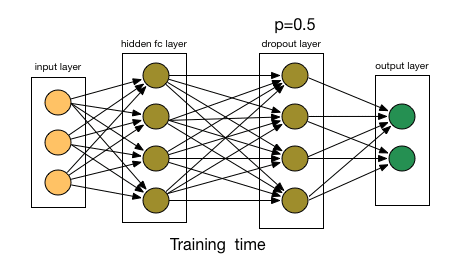
dropout表示图层中忽略的节点的百分比,因此表示未应用于输入的权重百分比。 指定dropout可降低过度拟合的可能性。
模型编译
添加完所有图层后,所有图层都会粘合在一起,并通过编译指定损失和优化程序。 还指定了度量标准,但仅用于我们的查看目的。 它们不会影响模型的结果。
=’binary_crossentropy’,optimizer=‘rmsprop’,metrics=[‘accuracy’])调整参数
Model.summary()逐层返回输出形状和参数数量可训练参数的数量。 参数数量越多,运行该模型的计算成本就越高。
由于图像数据生成器用于创建我们的数组,因此仅适合将生成器拟合到模型(而不是拟合数组本身)。
model_performance = model.fit_generator(train_generator,steps_per_epoch=100,epochs=10,validation_data=val_generator,validation_steps=50)
步骤数(steps_per_epoch和validation_steps)通过将数据集中的样本数除以批量大小来计算。
Epochs,如上面代码片段的第四行所示,是数据集上的迭代次数。 迭代次数越多,模型就越准确。
将发生器拟合到模型允许我们在每个时期的训练和验证集中获得模型的损失和准确性。
观察结果
尝试#1:将epoch设定为10
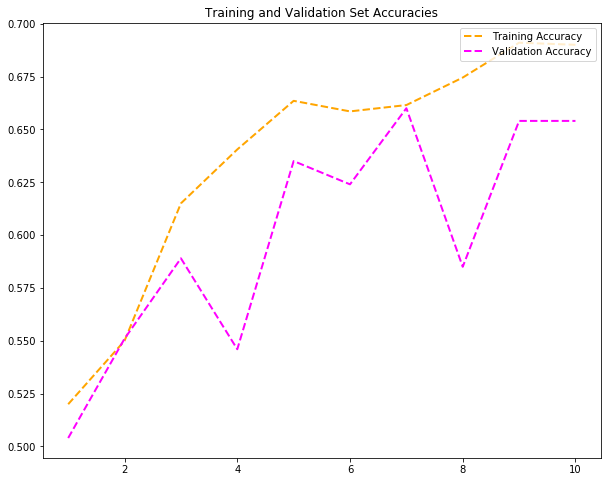
我获得了69%的训练准确率和65%的验证准确度。 第一次尝试还不错! 让我们看看当我将epoch加倍并添加卷积,批量标准化,汇集和丢失层的另一个组合时会发生什么。
尝试#2:加倍epoch
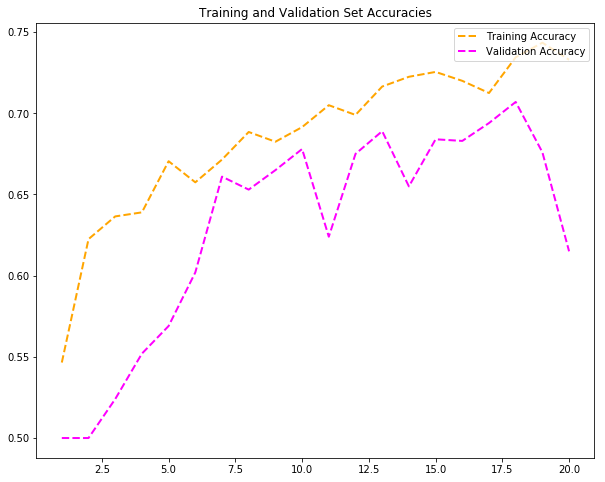
训练此模型的计算成本明显较高。 从上面的模型可以看出,过度拟合已经发生。 早期停止和数据增加等策略有助于防止模型过度拟合。
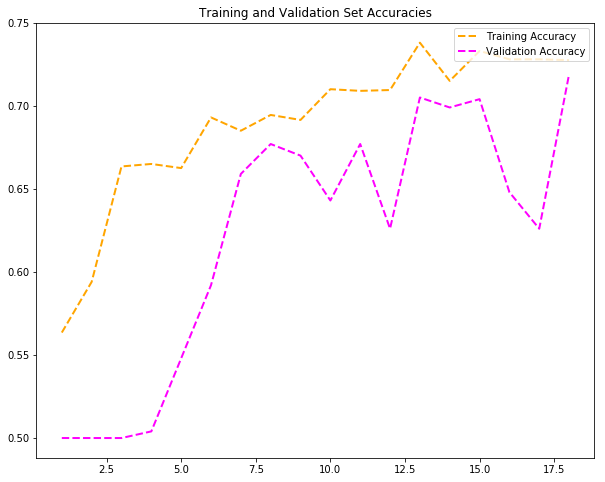
最终尝试:最佳时代计数
经过多次训练,这个相当小的数据集的理想epoch设置为18。 在不改变损耗和优化器参数的情况下,我能够获得72%的验证准确度。
https://medium.com/@jagerynnv/neural-networks-a-simple-image-classification-walkthrough-a0bca500f836
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



