【干货】主题模型如何帮助法律部门提取PDF摘要及可视化(附代码)
【导读】本文是Oguejiofor Chibueze于1月25日发布的一篇实用向博文,详细介绍了如何将主题模型应用于法律部门。文章中,作者分析了律师在浏览大量的法律文件的时候可以通过文档摘要进行快速了解。基于此需求,作者提出一系列步骤:将从PDF文档中提取文本、清洗文本、对文本进行主题建模、主题摘要及可视化。本文简洁、实用,如果你想基于主题模型做点实用的东西,那你就来对地方了!专知内容组进行编辑整理。

NLP For Topic Modeling & Summarization Of Legal Documents
你有没有想过律师如何有效地管理一系列的法庭陈述文件。 他们如何绕过法律文件的背景,从而能够快捷地找到要查找的内容。 这看起来很容易,但是如果有一个3000页的文件并且有很多重要的细节,我们该怎么办? 这是本文的动机,也就是如何从法律文件的pdf中自动建模主题,并总结关键的上下文信息。
本项目的目标是对双方的商标和域名协议进行自动化主题建模,以提取赞同或不赞同任何一方的话题。 这种方法包括:从文档的pdf副本中提取文本,清洗提取的文本,对文档中的主题进行建模并对摘要进行可视化。 请注意,这里采用的方法可以扩展到任何以pdf格式的文档。
▌从PDF文档中提取文本
双方之间的法律协议是作为pdf文件提供的(也就是我们必须首先从PDF文档中提取文本)。 首先使用下面的函数提取pdf文档中的文本。 这个函数使用python库pdf-miner,从PDF文档中提取除了图像以外(当然也可以修改这个函数,使之能处理图像)的所有字符。 该函数简单地取得主目录中pdf文档的名称,从中提取所有字符,并将提取的文本作为python字符串列表输出。
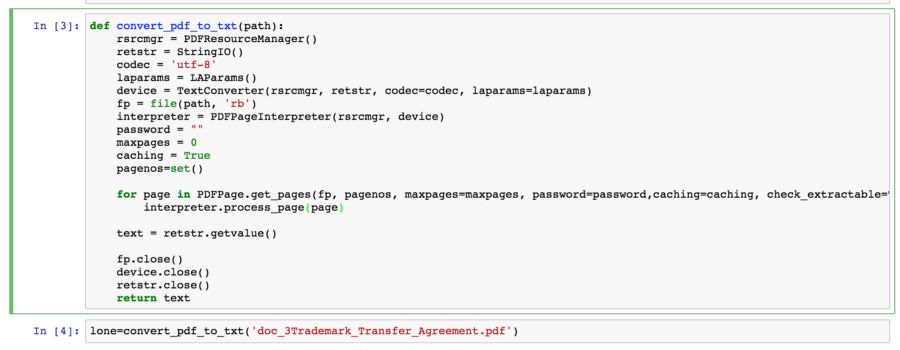
上图显示从pdf文档中提取文本的函数。
▌对提取的文本进行清洗
从pdf文档中提取的文本包含无用的字符,需要将其删除。 这些字符会降低我们的模型的有效性,因为模型会将无用的字符也进行计数。下面的函数使用一系列的正则表达式和替换函数以及列表解析,将这些无用个字符替换成空格。我们通过下面的函数进行处理,结果文档只包含字母和数字字符。

上图显示了用空格代替文档中无用字符的代码。

上图显示用空格代替非字母字符的代码。
▌主题建模
使用scikit-learn中的CountVectorizer只需要调整最少的参数,就能将已经清理好的文档表示为DocumentTermMatrix(文档术语矩阵)。 CountVectorizer显示停用词被删除后单词出现在列表中的次数。
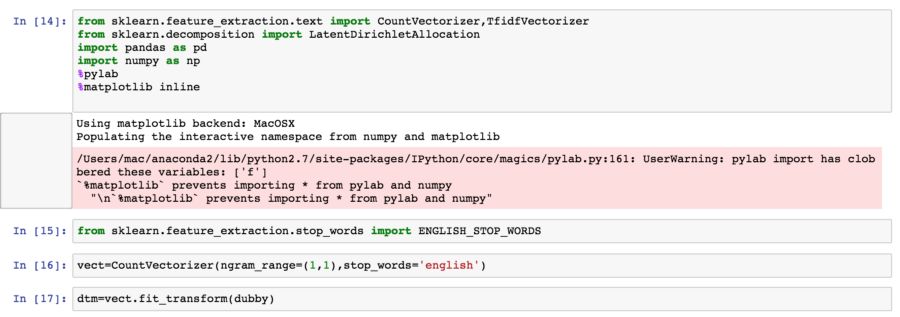
上图显示了CountVectorizer是如何在文档上使用的。
文档术语矩阵(document term matrix)被格式化为黑白数据框,从而可以浏览数据集,如下所示。 该数据框显示文档中每个主题的词出现次数。 如果没有格式化为数据框,文档主题矩阵是以Scipy稀疏矩阵的形式存在的,应该使用todense()或toarray()将其转换为稠密矩阵。
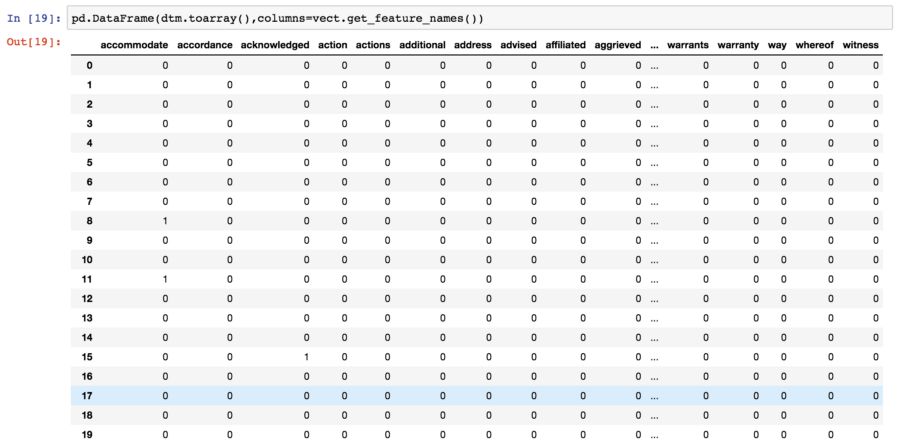
上图是从CountVectorizer的输出截取的。
该文档术语矩阵被用作LDA(潜在狄利克雷分布Latent Dirichlet Allocation)算法的输入。 现在有一些LDA算法的不同实现,但是对于本项目,我将使用scikit-learn实现。 另一个非常有名的LDA实现是Radim Rehurek的gensim。 这适用于将CountVectorizer输出的文档术语矩阵作为输入。 该算法适用于提取五个不同的主题上下文,如下面的代码所示。当然,这个主题数量也可以改变,这取决于模型的粒度级别。
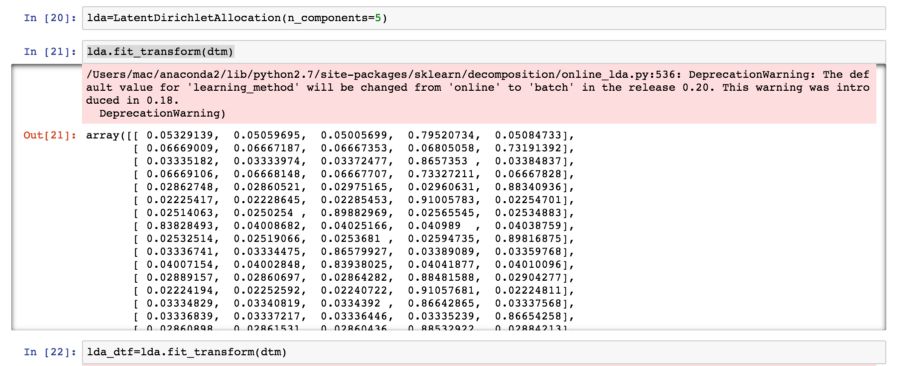
图中显示LDA模型如何用5个主题建模DocumentTermMatrix。
下面的代码使用mglearn库来显示每个特定主题模型中的前10个单词。 人们可以很容易从提取的单词中得到每个主题的摘要。
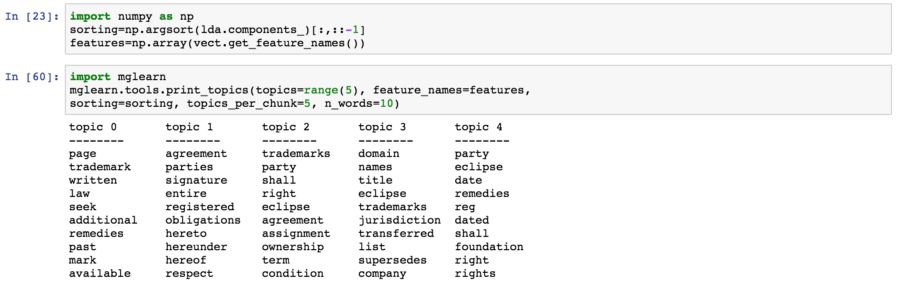
图中显示了LDA的5个主题和每个主题中最常用的单词。
从上面的结果可以看出,Topic-2与商标所有权协议的条款和条件有很大关系。 Topic -1讨论了签字方和当事方之间的协议。 ECLIPSE这个词似乎在所有五个主题中都很流行,这说明它在整个文档中是相关的。
这个结果与文档(商标和域名协议)非常一致。
为了更加直观地观察每个主题,我们用每个主题模型提取句子进行简洁的总结。 下面的代码从主题1和4中提取前4个句子。
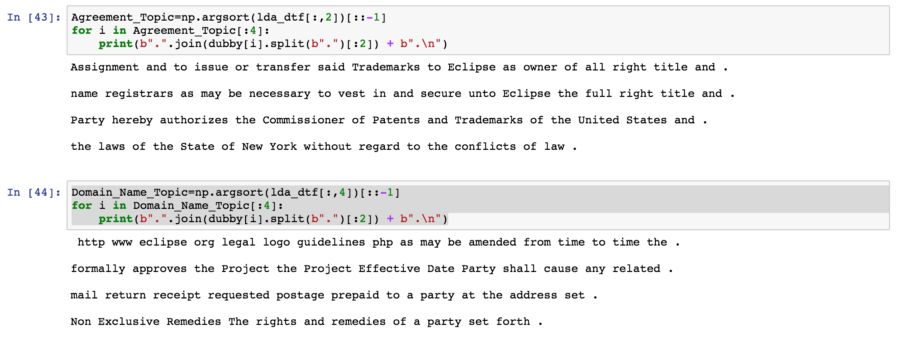
上图显示了从主题模型1和4中提取的句子。
Topic-1的句子是指,根据纽约市的法律将商标转让给eclipse。
Moreso,主题4的句子清楚地显示了商标协议的域名和生效日期。
▌结果可视化
PyldaVis库被用来对主题模型进行可视化。 请注意,Topic 1和Topic 4之间有非常紧密的联系,Topic 2,3和5主题是相互区分开的。 这些主题(2,3和5)在法律文件中包含了相对独特的主题,并且应该进行更细致的观察,因为它们在合并时提供了更宽的文档视图:
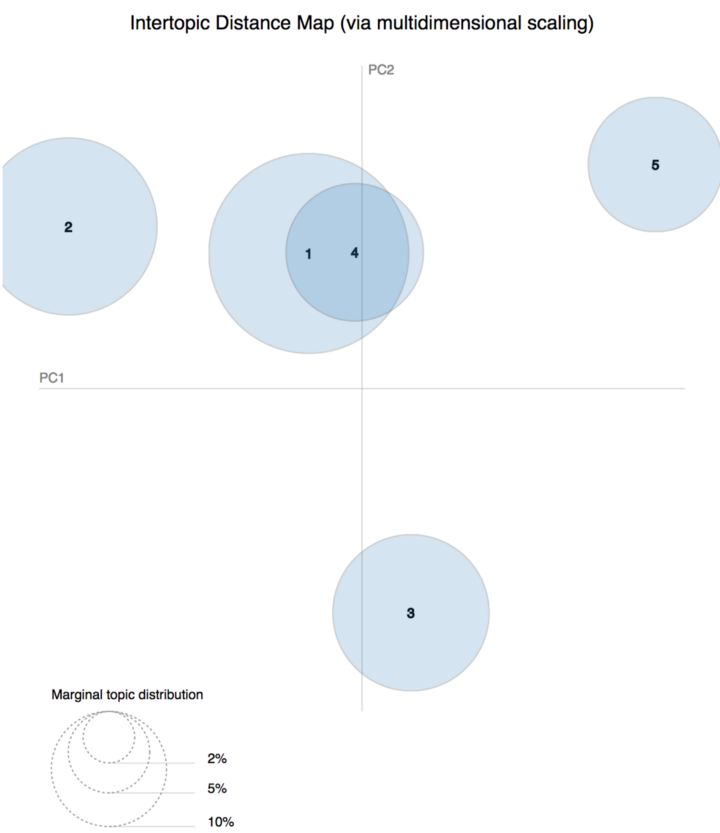
上图显示每个主题之间的区别。
从下面的图表来看,Topic-5是关于双方的协议、义务和签名的主题,而Topic-3则是关于域名、标题和商标的讨论。
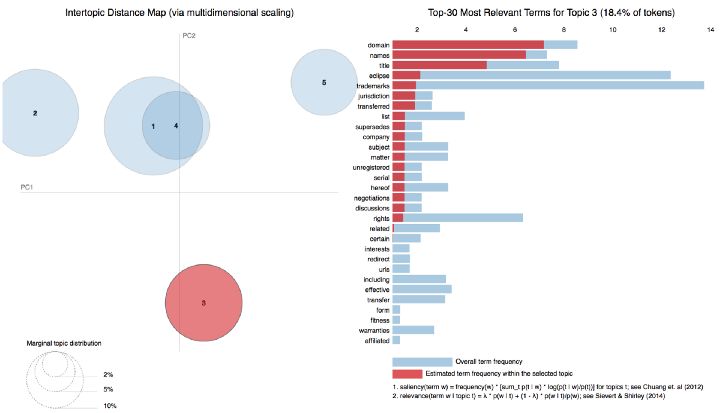
图中显示了Topic-3中最常见的单词。
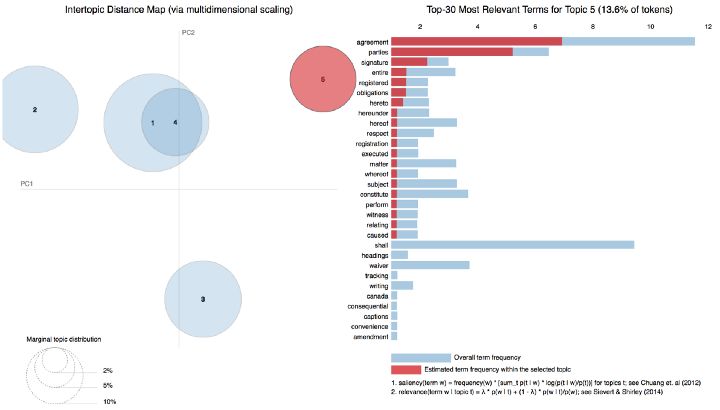
图中显示了Topic-5中最常见的单词。
还为整个法律文件生成了一个wordcloud,以便观察文档中最常用的术语,如下图所示。 这通常与主题的结果一致,如商标,协议,域名,eclipse等词语是最常见的。
在法律文件中显示最常见的单词/短语的单词云(wordcloud)。

▌结论
通过将LDA建模获得的主题2,3和5与为文档生成的wordcloud集成,我们可以比较确定地推断出,“这个文档是双方之间进行商标域名转让的简单法律约束”。
这个项目利用一个简单的方法从pdf中的文档中提取文本,这个项目也可以被修改和扩展,如从图像文件(.jpeg .png)中提取文本,可以在文档的快照上进行主题建模和摘要。 该项目展示了如何将机器学习应用于法律部门,如本文所述,可以在处理文档之前提取文档的主题和摘要。
这个项目更实际的用途是对小说、教科书等章节提取摘要,并且已经证明该方法是有效的。
本文的代码可以在GitHub上找到:
https://github.com/chibueze07/Machine-Learning-In-Law/tree/master
▌相关链接:
CountVectorizer:
http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
LDA:
http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.LatentDirichletAllocation.html
scikit-learn:
http://scikit-learn.org/stable/
参考链接:
https://towardsdatascience.com/nlp-for-topic-modeling-summarization-of-legal-documents-8c89393b1534
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



