【干货】Python机器学习机器学习项目实战3——模型解释与结果分析(附代码)
【导读】机器学习模型经常被批评是技术黑箱:只要输入数据就能得到正确答案,但却无法对其进行解释,在本系列的第三部分,作者展示一个完整的机器学习解决方案,并试图解释模型。
这是一篇完全手把手进行机器学习项目构建的教程,包含:1. 数据清理和格式化 2. 探索性数据分析 3. 特征工程和特征选择 4. 在性能指标上比较几种机器学习模型 5. 对最佳模型执行超参数调整 6. 在测试集合中评估最佳模型 7. 解释模型结果 8. 得出结论。在第一篇文章中,我们对数据进行了清理和结构化,进行了探索性的数据分析,开发了一组用于我们模型的特征,并建立了一个基准(baseline)来衡量性能。第二篇中,我们将讨论如何实现和比较Python中的几种机器学习模型,执行超参数优化,对最佳模型进行优选,并对测试集上的最终模型进行评估。
【干货】Python机器学习项目实战2——模型选择,超参数调整和评估(附代码)
作者 | William Koehrsen
编译 | 专知
参与 | Yongxi, Yingying

用python完成一个完整的机器学习项目:第三部分
——Interpreting a machine learning model and presenting results
本系列的第一部分【1】中,讨论了数据清理、数据分析、特征工程和特征选择。第二部分【2】讨论了不同机器学习模型的比较,使用了交叉验证进行随机搜索的超参数优化,并对模型进行了评估。
项目的所有代码都在Github【3】上。对应的Jupyter文本链接可跳转查看【4】,希望大家能够分享、使用和构建这一系列代码。
注意,我们正在研究的是一个有监督的机器学习回归问题。利用纽约市建筑能源数据【5】,构建了一个模型,预测建筑物的能源星级得分。最终构建了梯度增强回归模型【6】,在测试数据的误差在9.1以内(1-100范围内)。
模型理解
模型由数百个决策树组成,通过梯度增强了回归的效果,虽然每个决策树都是可解释的,但这仍然是一个复杂的模型。我们将通过三种方式来了解我们的模型是如何预测的。
1、 特征重要性【7】
2、 单一决策树可视化
3、 LIME:Local Interpretable Model-Agnostic Explainations【8】
前两种方法是决策树特有的,而第三种方法可以广泛应用于任何机器学习模型。LIME是一个相对较新的包,目的是对机器学习预测进行解释【9】。
特征重要性
特征重要性分析是为了显示特征与预测目标任务的相关性。特征的重要性分析过程是相当复杂的,但我们可以使用相对值来比较哪些特征是最相关的,使用Scikit-Learn,可以从任意基于树结构的学习器中分析出特征的重要性程度。
我们的训练模型,可以使用model.feature_importances_方法来找出关键特征。并且可以将他们输入到pandas的数据帧中,并将前十位的关键特征显示出来。
import pandas as pd
# model is the trained model
importances = model.feature_importances_
# train_features is the dataframe of training features
feature_list = list(train_features.columns)
# Extract the feature importances into a dataframe
feature_results = pd.DataFrame({'feature': feature_list,
'importance': importances})
# Show the top 10 most important
feature_results = feature_results.sort_values('importance',
ascending = False).reset_index(drop=True)
feature_results.head(10)
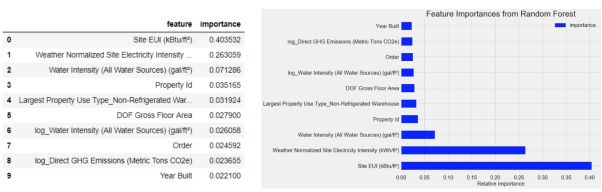
可以看出,EUI(能量使用强度)和归一化的天气电力强度( Weather Normalized Site Electricity Intensity)是最重要的特征,占到重要性66%以上。从第三位特征开始,重要性明显下降,这表明我们并不需要使用所有的特征来获得更高效能。基于这些结果,我们可以回答最初的问题,建筑星级能源评分的最重要指标是EUI和归一化的天气电力强度。当我们想要读取更多的关键特征时【10】,这是种方法非常的有效,可以帮我们理解模型是如何运作的。
单一决策树的可视化
整个梯度增强回归器可能非常难以理解,但独立的决策树都非常的简单,我们可以使用Scikit-Learn函数export_graphviz【11】来可视化森林中的任意一棵决策树。
from sklearn import tree
# Extract a single tree (number 105)
single_tree = model.estimators_[105][0]
# Save the tree to a dot file
tree.export_graphviz(single_tree, out_file = 'images/tree.dot',
feature_names = feature_list)
dot -Tpng images/tree.dot -o images/tree.png

即使这棵树只有6层,但是也很难看清。 我们可以将调用修改为export_graphviz并将我们的树限制在更合理的两层
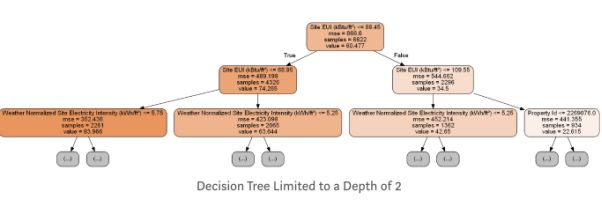
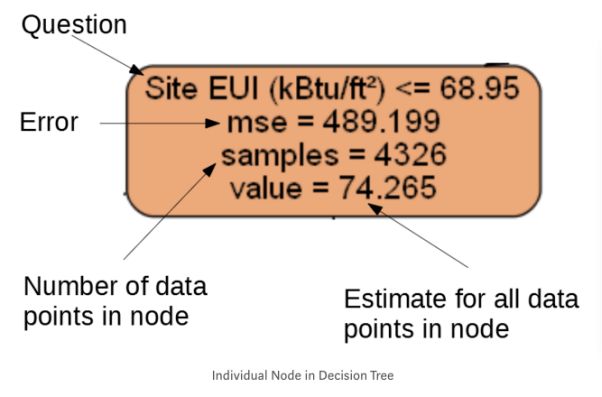
树中的每个节点都有四个属性信息:
1、 一个数值判断表达式,来决定接下来该向左还是向右走
2、 Mse代表了节点的误差
3、 Samples表示样本数量
4、 Value表示节点中所有样例的估计值
(叶子节点只有2-4个,因为这代表了最终的估计值,并且没有任何的孩子节点。)
决策树通过从根节点对数据进行预测,逐渐遍历树中各个层次。例如,上述节点问题是:该建筑是否有一个小于或等于68.95的站点EUI?如果答案是肯定的,那么将进入右子节点,否则将进入左子节点。
这个过程在树中的每一层进行重复,直到叶子节点。随着树的深度增加,训练集上的误差都会减小,因为有更多的叶子节点,可以有助于更细粒度的划分,然而,层数太深将导致训练数据不够,而无法将预测能力推广到训练数据中。
在第二篇文章中【12】,我们对一些模型超参数进行了优化,这些模型控制了每棵树的各个方面,比如树的最大深度,和叶子节点所需的最小样本数量。这两点都对过拟合有巨大影响。对此,我们可以使用可视化工具展示出决策树的配置过程。
虽然我们无法对模型的每颗树都检查一遍,但可以了解每个独立决策树是如何作出预测的,这种基于流程图的方法看起来更像是一个人在做决定的方式:一次只回答一个问题。基于决策树的集合,整合了许多决策树的预测能力,创建了一个方差较小的精准模型。决策树的组合往往非常准确,而且很容易做出解释。
LIME,Local Interpretable Model-Agnostic Explanations
最后一个工具(LIME)将帮助我们理解模型是如何思考的。LIME目标是解释任意独立的机器学习模型【13】,方法是创建一个模型局部近似的模型,如线性回归,具体细节见链接【14】。
这里我们将使用LIME来考察模型预测错误的例子,以分析为什么模型会出错。首先,需要找出模型预测错误的样例,这可以通过训练与预测模型来提取。
from sklearn.ensemble import GradientBoostingRegressor
# Create the model with the best hyperparamters
model = GradientBoostingRegressor(loss='lad', max_depth=5,
max_features=None,min_samples_leaf=6, min_samples_split=6,
n_estimators=800, random_state=42)
# Fit and test on the features
model.fit(X, y)
model_pred = model.predict(X_test)
# Find the residuals
residuals = abs(model_pred - y_test)
# Extract the most wrong prediction
wrong = X_test[np.argmax(residuals), :]
print('Prediction: %0.4f' % np.argmax(residuals))
print('Actual Value: %0.4f' % y_test[np.argmax(residuals)])
Prediction: 12.8615
Actual Value: 100.0000
接下来,我们创建LIME解释器扫描训练数据、模型、训练标签以及数据特征的名称。最后,通过解释器对错误预测作解释,扫描观测以及预测函数。
import lime
# Create a lime explainer object
explainer = lime.lime_tabular.LimeTabularExplainer(training_data = X,
mode = 'regression', training_labels = y,
feature_names = feature_list)
# Explanation for wrong prediction
exp = explainer.explain_instance(data_row = wrong,
predict_fn = model.predict)
# Plot the prediction explaination
exp.as_pyplot_figure();
结果如图所示
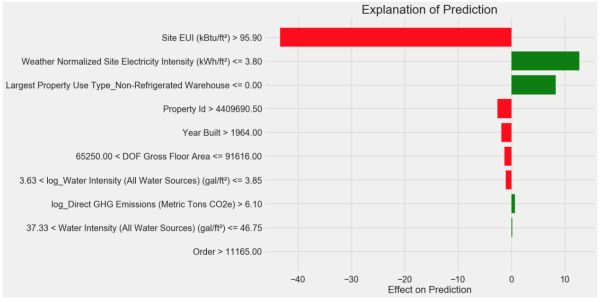
图片解释如下:y轴的每个记录展示了该特征对预测结果的影响,红色和绿色的柱状图表示每个特征对预测的影响。例如,最上面的记录表示EUI高于95.90,为预测带来了40分的负向影响。第二条记录表示电力强度低于3.8,为模型预测带来了10分的正向影响,最终预测是一个截距项加上每一个单独的贡献之和。
我们也可以通过另一个解释器(.show_in_notebook())得出相似的结论。
# Show the explanation in the Jupyter Notebook
exp.show_in_notebook()

左边的结果展示了各个特征值对预测的贡献程度,右边的表中展示了数据变量的真实值。这个例子中,模型预测结果为12,而真实值是100!最初的结果可能是令人费解的,但看着这个解释,我们可以发现这是一个合理的估计。Site EUI的值比较高,我们预计能量分数会很低(因为EUI与分数的关系非常强),我们的模型也给出了这个结论,在这种情况下,逻辑是错误的,因为该建筑的真实分数是100分。
当一个模型错误时,可能会非常令人沮丧,但是这种方法,能够帮助我们理解为什么模型是错误的。此外,基于这一解释,我们可以探究为什么这座建筑会有这样的分数。也可以从中学到些新的东西,这种工具可能并不完美,但可以帮助我们理解模型,从而帮助我们做出更好的决策。
记录工作与结果报告
技术项目经常会忽视文档和报告。即使可以做很好的分析,但是如果无法清楚的表达结果,那么就不会有任何影响!
当我们记录一个数据科学项目时,可以获取所有的数据和代码,这样项目就可以被其他的数据科学家重现。重要的是,代码比文档要更常用得多,我们应该保证他人可以清楚的理解我们的工作。这意味着在代码中加入有用的注释并解释推理过程将非常有意义。我发现Jupyter笔记本是一个很好的文档工具,因为它们可以一步一步的输入注释和代码。
Jupyter笔记本也是一个分享信息的好平台。使用Jupyter,我们可以将代码隐藏在最终报告中,因为并不是每个人都想在文档中看到一堆Python代码!
本项目的最终结果:
1、 利用纽约能源数据,可以建立一个误差在9.1以内的模型,来预测建筑物的能源星级。
2、 EUI和电力强度是预测分数的最相关因素。
结论
在整个系列文章中,我们已经完成了一个完整的端到端的机器学习项目,通过数据清洗、模型建立,最后看到了如何解释一个机器学习模型。机器学习项目的总体结构如下:
1、 数据清洗和格式
2、 探索性数据分析
3、 工程特性和选择
4、 比较机器学习模型和性能指标
5、 对最佳模型进行超参数调优
6、 评估测试集上的最佳模型
7、 解释模型的结果
8、 得出结论,并完成报告
虽然具体步骤因项目而异,机器学习通常是一个迭代过程,而不是线性的过程,这份指南可以在你日后完成机器学习项目时,帮你提供思路。希望这个系列可能让你有信息实现自己的机器学习解决方案。如果需要,有很多社区可以供你寻求建议。
在我学习的过程中,发现了一些很有用的资源
1、 学习使用scikit-Learning和Tensorflow(这本书的Jupyter笔记本电脑可以免费在线免费使用)!【15】【16】
2、 统计学习介绍【17】
3、 Kaggle:数据科学和机器学习的发源地【18】
4、 很好的入门教程,用于实践数据科学编码【19】
5、 Coursera:免费和付费课程【20】
6、 Udacity:付费编程和数据科学课程【21】
参考链接:
1.https://mp.weixin.qq.com/s/KG3Euvj0OT02IuahjhswYA
2.https://mp.weixin.qq.com/s/nA30l8avTIzA6H8p81QOmg
3.https://github.com/WillKoehrsen/machine-learning-project-walkthrough
4.https://github.com/WillKoehrsen/machine-learning-project-walkthrough/blob/master/Machine%20Learning%20Project%20Part%203.ipynb
5.http://www.nyc.gov/html/gbee/html/plan/ll84_scores.shtml
6.http://blog.kaggle.com/2017/01/23/a-kaggle-master-explains-gradient-boosting/
7.http://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html
8.https://github.com/marcotcr/lime
9.https://pdfs.semanticscholar.org/ab4a/92795ee236632e6dbbe9338ae99778b57e1e.pdf
10.http://parrt.cs.usfca.edu/doc/rf-importance/index.html
11.http://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html
12.https://towardsdatascience.com/a-complete-machine-learning-project-walk-through-in-python-part-two-300f1f8147e2
13.https://www.oreilly.com/learning/introduction-to-local-interpretable-model-agnostic-explanations-lime
14.https://arxiv.org/pdf/1602.04938.pdf
15.http://shop.oreilly.com/product/0636920052289.do
16.https://github.com/ageron/handson-ml
17.http://www-bcf.usc.edu/~gareth/ISL/
18.https://www.kaggle.com/
19.https://www.datacamp.com/
20.https://www.coursera.org/
21.https://www.udacity.com/
原文链接:
https://towardsdatascience.com/a-complete-machine-learning-walk-through-in-python-part-three-388834e8804b
代码链接:
https://github.com/WillKoehrsen/machine-learning-project-walkthrough/blob/master/Machine%20Learning%20Project%20Part%203.ipynb
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能知识星球服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



