【论文笔记】对话模型新方法,条件DialogWAE生成多模态回答
【导读】变分自动编码器(VAEs)的研究已经在问答系统中生成回答这个任务中卓有成效。然而,大多数VAE对话模型将潜在变量的近似后验分布假设成简单的分布,如标准正态分布。因此生成的回答时单模态的。本文提出了DialogWAE,一种建模了对话模型的条件Wasserstein自动编码器(WAE)。
Dialog-WAE用GAN训练潜在的分布,它通过使用神经网络生成上下文相关的随机“噪声”,从潜在变量的先验和后验分布中抽样,并最小化两个分布之间的Wasserstein距离。然后,使用高斯混合先验网络来丰富潜在空间。在广泛使用的数据集进行的实验表明,DialogWAE在产生更连贯,信息丰富和多样化的响应方面超越了最先进的方法。
DialogWAE: Multimodal Response Generation with Conditional Wasserstein Auto-Encoder

论文链接:https://arxiv.org/abs/1805.12352
动机
许多基于VAE的对话模型都用一个简单的先验分布,如高斯分布近似后验分布,这样会出现“后验崩溃(posterior collapse)”的问题,即在生成过程中忽略了隐变量。因此,生成回答的过程会被限制。而作者设计的模型为了解决这个问题,在生成后验分布时,采用了混合高斯分布,并使用对抗学习的方法训练模型。
问题定义
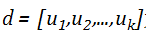
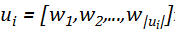
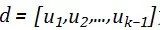
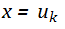
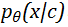
模型
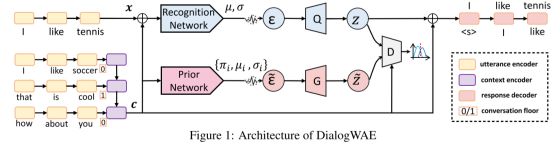
模型的结构如上所示。
Utterance 编码器
将对话中的所有内容(包括生成目标x)编码成实值向量的格式。在图中表示为黄色的框,是一个RNN(GRU)网络。
Context编码器
将上下文信息(不包括生成目标x)编码成实值向量的格式。图上句子后面的0/1表示对话中双方的编号。在图中表示为紫色的框,也是一个RNN(GRU)网络,网络最后的输出即为上下文向量。
训练的过程
在图中表示为中间部分蓝色之路。Recognition Net(RecNET)是一个前馈网络,首先接受由Utterance编码器和Context编码器拼接而成的向量作为输入,输出噪声的分布:和.然后根据分布取样得到噪声. 生成器Q根据取样得到的噪声,由一个前馈网络生成隐变量Z。
预测的过程
在图中表示为中间部分粉红之路。Prior Network(PriorNet)是一个前馈网络,仅接受Context编码器的输出作为输入,输出服从的分布的参数。为了解决一般VAE的参数的问题,这里使用了混合高斯分布,参数为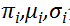
判别器
判别器Z的目标是区分隐变量z的先验分布和后验分布,判别器D接受c和z的拼接作为输入,输出一个实值。判别器的训练目标是最小化从分别从先验分布和后验分布取样来的Z的Wasserstein距离。
实验结果
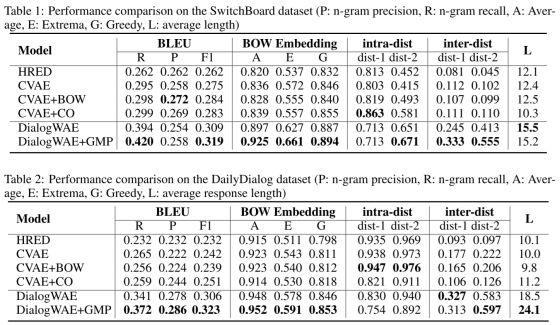
作者在两个开放域数据集Daliy Dialog(英语学习者使用的日常对话,13118组对话)和 Switchboard(2400组,70个话题,两人对话)上进行了实验,使用BLEU、BOW Embedding、intra-dist等作为衡量指标,结果表明在大多数情况下比现有的方法好的多。
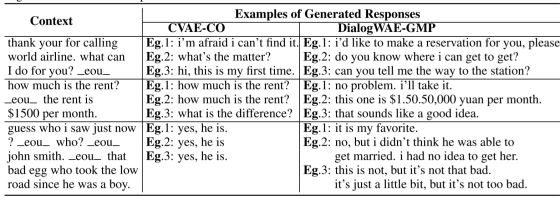
一些生成的例子如下所示:
原文链接:https://arxiv.org/abs/1805.12352
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能知识星球服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



