强化学习的基石:DeepMind开源框架TRFL
【导读】深层强化学习已被多次归类为人工智能(AI)的未来。过去几年中一些最重要的人工智能突破,如DeepMind的AlphaGo或OpenAI的Dota Five,都基于深度强化学习。尽管它很重要,但深度强化学习模型的实现仍然是一项极具挑战性的工作,而且在大多数情况下,我们对写出高校深度强化学习的解决方案的没有任何想法。本周早些时候,DeepMind开源TRFL,这是一个编译模型的一系列有用构建块的框架。
作者|Jesus Rodriguez
编译|专知
整理|Yingying,李大囧
目前大多数深度强化学习方法都源于学术,并且尚未在实际应用使用。因此,数据科学团队经常努力重建在孤立环境中生成的深度强化学习的研究论文中声称的一些结果,而没有经过验证的框架。许多在论文或研究实施中看起来很优秀的模型在应用于实际应用程序时会遇到错误或挑战。再现深度强化学习研究结果最具挑战性的方面之一是缺乏对规范深度强化学习模型行为的指标的理解。
强化学习重要性
深度强化学习算法是最敏感的深度学习模型之一。奖励模型的小环境变化或微小变化可能会导致深度强化学习模型的行为出现大的偏差。 DRL研究论文中未准确报告的许多要素会对实施模型的运行时行为产生深远影响。了解影响此类模型的因素是构建高效深度强化学习应用程序的关键因素。 DeepMind的TRFL实现受到最近一篇论文的高度影响,该论文试图确定影响DRL模型行为的主要方面。
斯坦福大学教授彼得·亨德森(Peter Henderson)领导的这项研究评估了可能对深度强化学习模型产生影响的数十个因素。结果显示了一组离散的元素,这些元素是任何深度强化学习算法的基础。
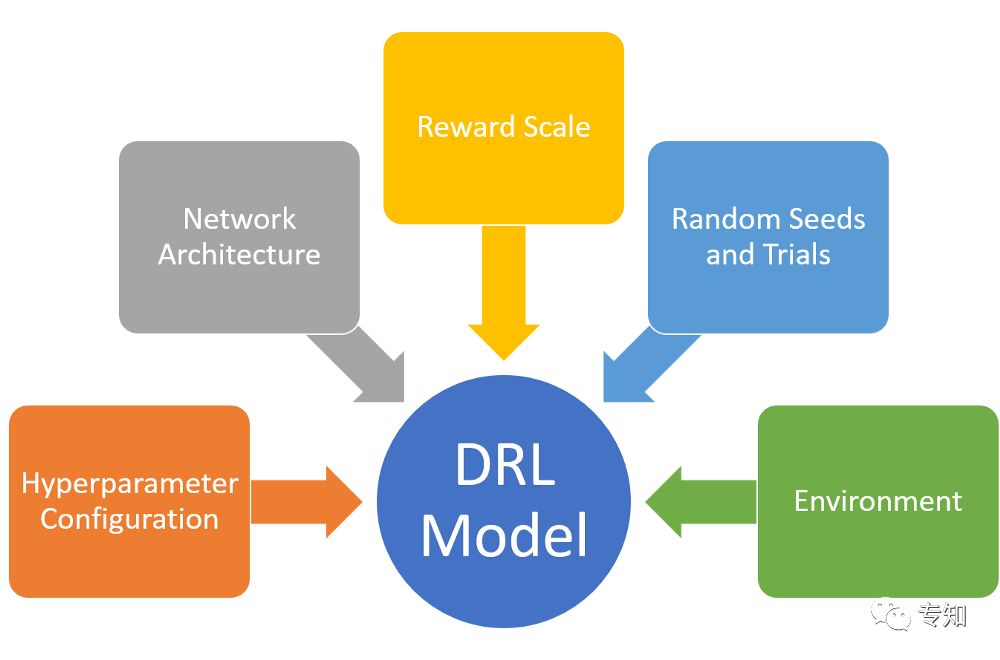
超参数配置:研究表明,超参数配置的微小变化会对深度强化学习模型产生的结果产生相关影响。
网络架构:策略和价值功能的网络架构的变化是DRL模型性能的关键因素。
奖励规模:在诸如深度确定性政策梯度的许多DRL方法中,奖励量表被用作改善训练结果的机制。亨德森的研究表明,奖励扩展操作可以改变DRL模型的行为,但不同类别的DRL算法的变化是不一致的。
随机种子和试验:该研究进行了一系列实验,运行具有相同超参数配置但改变随机种子的DRL模型。结果表明,不同的随机种子可以在DRL方法中产生统计学上显着的变化。
环境:事实证明,选择OpenAI Gym或Hopper-v1等训练环境可以使DRL方法发挥重要作用。亨德森的研究表明,一些DRL方法往往在动态稳定的环境中表现更好,但随着环境变得更加不稳定,它们的行为会迅速减弱。
像亨德森研究这样的研究工作有助于掩盖一些调节DRL模型性能的方面。但是,大多数这些组件不仅记录不完整,而且还不与大多数深度学习框架兼容。
TRFL
TRFL是一个建立在TensorFlow之上的框架,它抽象了几个构建块,用于实现高效的深度强化学习(DRL)代理。 TRFL将深度学习算法的结果表示为可以探索和优化的可区分损失函数。以下代码说明了如何使用简单的Q-Learning方法使用TRFL。
import tensorflow as tf
import trfl
# Q-values for the previous and next timesteps, shape [batch_size, num_actions].
q_tm1 = tf.constant([[1, 1, 0], [1, 2, 0]], dtype=tf.float32)
q_t = tf.constant([[0, 1, 0], [1, 2, 0]], dtype=tf.float32)
# Action indices, pcontinue and rewards, shape [batch_size].
a_tm1 = tf.constant([0, 1], dtype=tf.int32)
pcont_t = tf.constant([0, 1], dtype=tf.float32)
r_t = tf.constant([1, 1], dtype=tf.float32)
loss, q_learning = trfl.qlearning(q_tm1, a_tm1, r_t, pcont_t, q_t)
#optimize loss
loss, _ = trfl.qlearning(q_tm1, a_tm1, r_t, pcont_t, q_t)
# You can also do this, which returns the identical `loss` tensor:
loss = trfl.qlearning(q_tm1, a_tm1, r_t, pcont_t, q_t).loss
reduced_loss = tf.reduce_mean(loss)
TRFL实现了一大批深度强化学习构建模块,包括状态-值学习,分布-值学习,持续行动政策梯度,确定性策略梯度等等。
TRFL代表了指导实现有效深度强化学习方法的首批尝试之一。 而TRFL与TensorFlow无缝衔接有助于其在深度学习社区中的广泛应用。 当然,像TRFL这样的努力将有助于重现和验证研究环境中产生的深度强化学习方法的一些“壮观结果”。
原文链接:
https://medium.com/@jrodthoughts/the-building-blocks-of-reinforcement-learning-deep-open-sources-trfl-1bcdb1b5c591
-END-
专 · 知
欢迎微信扫描下方二维码加入专知人工智能知识星球群,获取更多人工智能领域专业知识教程视频资料和与专家交流咨询!

登录www.zhuanzhi.ai或者点击阅读原文,使用专知,可获取更多AI知识资料!

专知运用有多个深度学习主题群,欢迎各位添加专知小助手微信(下方二维码)进群交流(请备注主题类型:AI、NLP、CV、 KG等)

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



