【导读】专知内容组近期将会推出自然语言处理、计算机视觉等国外经典课程笔记系列。我们将首先介绍基于深度学习的自然语言处理的相关知识及应用。本系列博文基于斯坦福CS224n 2018最新课程进行总结,希望大家喜欢。
上一次我们介绍了自然语言处理相关概念、自然语言处理的应用,以及深度学习相关概念,并且引入了使用深度学习的方法来进行处理自然语言处理许多应用问题。这节课主要给大家讲解一下词向量的概念,详细说了WordNet、one-hot vectors和Word vectors 这三种方式的优劣,并且介绍了Word2vec目标函数梯度计算和其优化方法。感兴趣的读者可以详细阅读一下。
【NLP专题】斯坦福CS224n课程笔记01:自然语言处理与深度学习简介
2018CS224n官网:
http://web.stanford.edu/class/cs224n/index.html
2017CS224n官方笔记:
https://github.com/stanfordnlp/cs224n-winter17-notes
2017CS224n视频地址:
https://www.youtube.com/watch?v=OQQ-W_63UgQ&list=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6
2017CS224n国内在线观看:
https://www.bilibili.com/video/av13383754
cs224n深度学习与NLP课程详细信息可以参见专知以前的内容:
【最新】2018斯坦福cs224n深度学习与NLP课程又开课了(附ppt下载)
Lecture 02 Word Vectors(1)
本节课计划
词的意义(word meaning) (15 mins)
介绍Word2vec (20 mins)
Word2vec目标函数梯度计算 (25mins)
优化(optimize)复习(10 mins)
一. 我们如何表达一个单词的意思?
1. meaning的定义(在字典中的含义)
• 用一个词,短语等表示
• 一个人想用文字、符号等来表达
• 在书法,艺术等作品中表现出来的
• 最常见的语言学的思维认为“meaning”是:

2. 如何在计算机中表达可用的词义
• 常见的解决方案:使用WordNet,一个包含同义词集(synonym sets)和hypernyms(“is a” 关系)的列表的资源。如下图python代码所示:

• WordNet存在的问题
是很好的资源,但是缺少单词之间的一些细微差别(nuance),比如说,“精通(proficient)”被列为“好(good)”的同义词。但这只有在某些情况下是正确的。
缺少一些新词的含义,比如:wicked, badass, nifty, wizard, genius, ninja, bombest。从而导致WordNet无法与时俱进。
这个数据集单词的挑选是比较主观的
需要人力来创造和修改
难以精准地计算词的相似度(word similarity);
因此我们需要更好的方法来表达词意!
• 将单词表示为离散的符号(discrete symbols),使用one-hot vectors 来表示单词,单词向量的维度由词库中所拥有的单词数量来决定,如下图所示:

• 但是,这种用one-hot将单词表示为离散符号的做法是有问题的:
(举例说明)在网络搜索中,如果用户搜索“Seattle motel”,我们希望匹配包含“Seattle motel”的所有文档。
但是,
motel = [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0], hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0], 这两个向量是正交的(orthogonal)。他们之间没有相似度(cos90°=0)。 所以对于one-hot vectors,没有相似(similarity)的概念。
可能的解决方法:
• 可以依靠WordNet的同义词列表来获得相似度吗? NO!
• 相反,是否可以在向量本身中encode similarity。
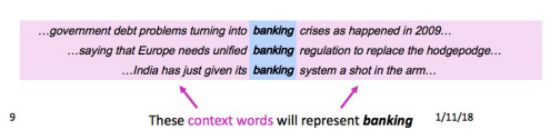
• 用上下文来表示单词(Representing words by their context)
核心思想:一个单词的意思是由经常出现在近旁的单词所给出的(A word’s meaning is given by the words that frequently appear close-by)。
• “You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
• 现代统计NLP最成功的思想之一!
当一个单词w出现在文本中时,它的上下文就是出现在附近(在一个固定大小的窗口内)的一组单词的集合。
使用w的众多的上下文(context)来建立w的表示,如下图所示:
词向量 (Wordvectors) 我们将为每个单词构建一个密集的向量,这样它就与出现在类似上下文中的单词的向量相似。比如:
注意:词向量(word vectors)有时也被称为词嵌入(word embeddings)或词表示(word representations)。

二. Word2vec概述
• 概述:Word2vec (Mikolov et al. 2013)是一个学习词向量表示的框架。其主要思想是:
我们有一个大型文本语料库
一个固定词汇表中的每个词都用一个向量表示
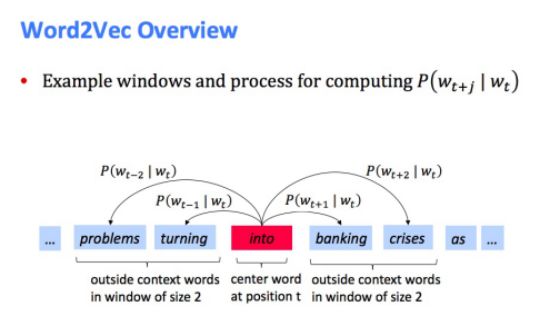
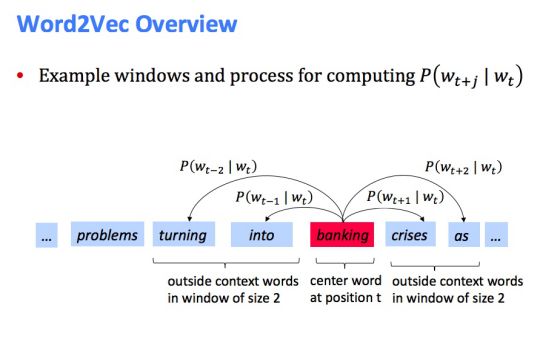
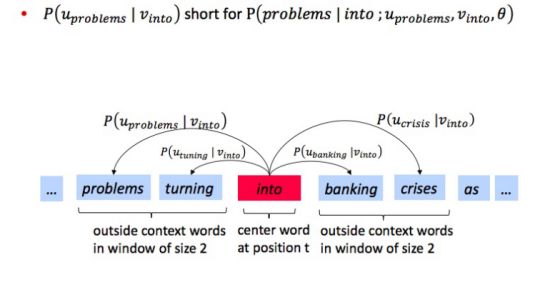
遍历文本中的每个位置t,它有一个中心词和上下文(“outside”)词
使用和之间词向量的相似度(similarity of the word vectors for and )来计算在已知的情况下,的概率(或者相反,已知计算)
不断调整这个词向量以使得这个概率最大化
见下图两个例子:
• Word2vec:目标函数(objective function) 对于每个位置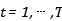
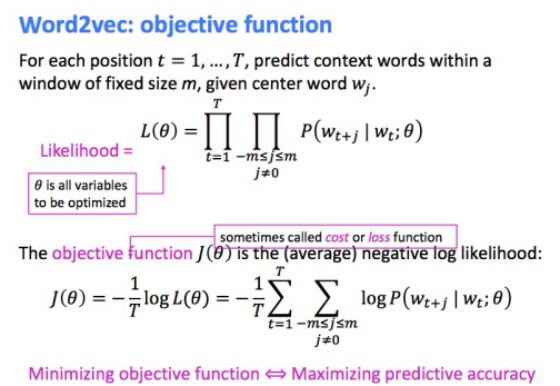
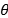
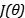
• 我们希望最小化(minimize)目标函数:
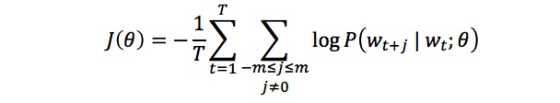
现在问题是,如何计算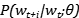
表示当w是中心词时候的向量
表示当w是上下文词时候的向量,
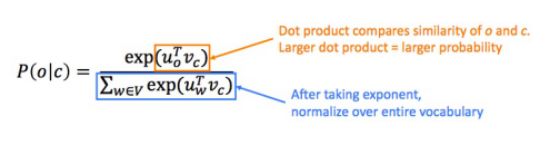
之后,对于中心词c和上下文词o我们可以通过如下公式计算到:
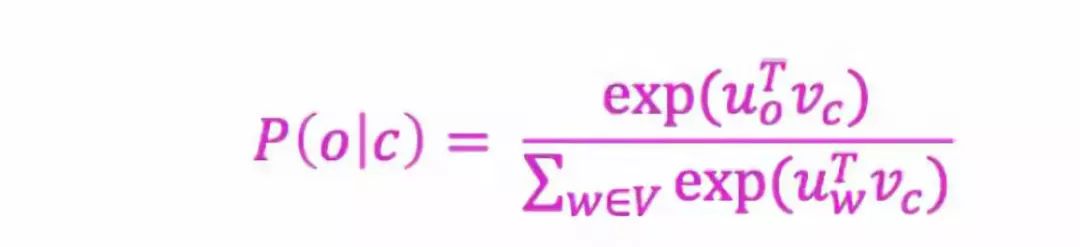
本质上,这是一个Softmax公式。 例子如下图所示:
• Word2vec:预测函数(prediction function)
为什么要用Softmax函数?因为Softmax函数可以将任意值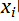
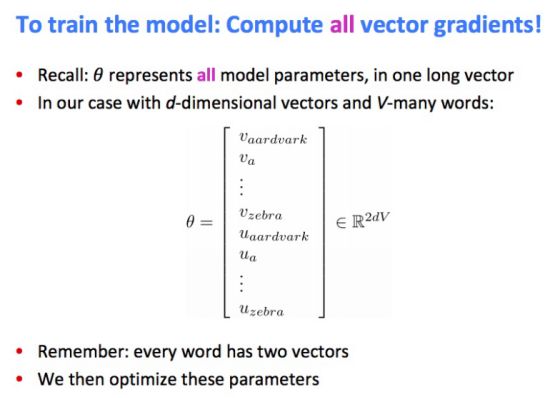
• 训练模型:计算所有的向量梯度!
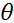
三. 梯度(gradient)的计算
• Chain Rule
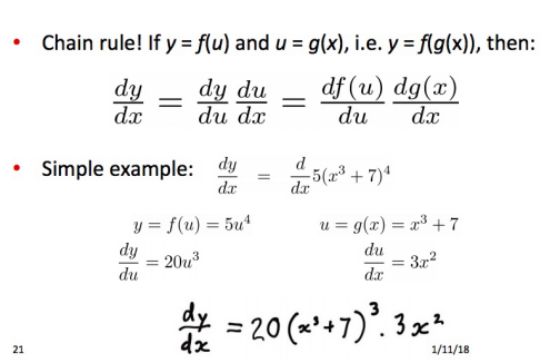
• 举例:计算所有中心词的梯度(留作homework)

• 计算所有的梯度
三. 一些补充知识
1. 关于Word2vec的补充知识
• 为什么每个单词需要两个向量来表示? 更容易优化。最后求两者的平均值。
• Word2vec的两种变体
Skip-grams(SG):给出中心词,预测上下文词
Continuous Bag of Words(CBOW):给出上下文词,预测中心词
• 为了在训练中进一步提高效率:使用Negative sampling的方法
补充:Theskip-gram model and negative sampling


• 补充:The continuous bag of words model

2. 关于梯度(gradient)的补充知识
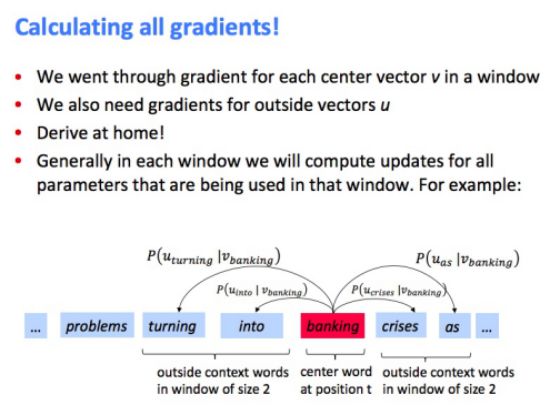
• 关于梯度下降(Gradient Descent)
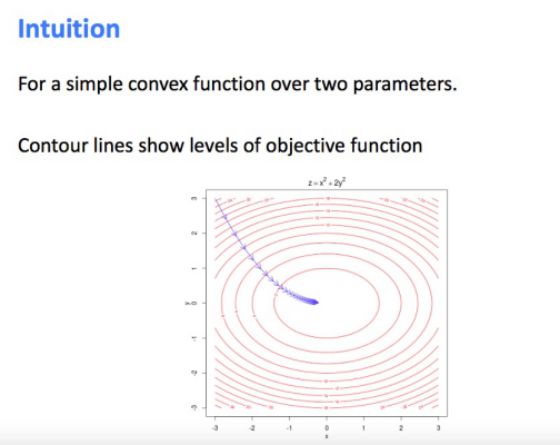

• 随机梯度下降(Stochastic Gradient Descent)

下节课将继续讲解。
建议阅读资料:
Word2Vec 教程 - The Skip-Gram Model
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
论文:Distributed Representations of Words and Phrases and their Compositionality
http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
论文:Efficient Estimation of Word Representations in Vector Space
https://arxiv.org/pdf/1301.3781.pdf
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“NLPS” 就可以获取 2018年斯坦福CS224n课程PPT下载链接~
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



