【斯坦福大学吴恩达博士生Ziang Xie】深度文本生成最佳实战指南(附指南下载)
点击上方“专知”关注获取专业AI知识!

【导读】人们期待未来有一天计算机能够像人类一样会写作,能够撰写出高质量的自然语言文本。文本自动生成就是实现这一目的的关键技术。按照不同的输入划分,文本自动生成可包括文本 到文本的生成、意义到文本的生成、数据到文本的生成以及图像到文本的生成等。上述每项技术均极具挑战性,专知内容组整理一份关于深度文本生成最佳实践指南,这篇指南对上述前沿技术在应用中可能遇到的问题给出了参考的实践解决方案,对我们实际系统的开发很具参考意义。

▌作者
Ziang Xie 斯坦福大学Phd在读,导师Andrew Ng, 同时也是Ng著名的CS229 2017 《机器学习》课程的助教主管。http://cs229.stanford.edu/#
▌背景
文本自动生成是自然语言处理领域的一个重要研究方向,实现文本自动生成也是人工智 能走向成熟的一个重要标志。简单来说,我们期待未来有一天计算机能够像人类一样会写作, 能够撰写出高质量的自然语言文本。文本自动生成技术极具应用前景。例如,文本自动生成 技术可以应用于智能问答与对话、机器翻译等系统,实现更加智能和自然的人机交互;我们 也可以通过文本自动生成系统替代编辑实现新闻的自动撰写与发布,最终将有可能颠覆新闻 出版行业;该项技术甚至可以用来帮助学者进行学术论文撰写,进而改变科研创作模式。
按照不同的输入划分,文本自动生成可包括文本到文本的生成(text-to-text generation)、意义到文本的生成(meaning-to-textgeneration)、数据到文本的生成(data-to-text generation) 以及图像到文本的生成(image-to-text generation)等。上述每项技术均极具挑战性,在自然语 言处理与人工智能领域均有相当多的前沿研究,近几年业界已产生了若干具有国际影响力的 成果与应用。最值得一提的是,美联社自 2014 年 7 月开始已采用新闻写作软件自动撰写新 闻稿件来报道公司业绩,这大大减少了记者的工作量。美国洛杉矶时报也有一种用来撰写突 发新闻的应用软件。美国已有多家公司能够提供新闻写作软件与服务,比如美国“自动洞察 力”公司(Automated Insights)已采用“语言专家”软件撰写了 3 亿篇报道,包括橄榄球、财经报 道。这些进展标志着文本自动生成不再属于纸上谈兵的技术,而是已经对人类工作和生活产生了重大影响。
▌目录

目录:
1. 序言
1.1该指南的重点
1.1.1本文的局限:本文不涉及的内容
2. 背景
2.1设置
2.2编码器-解码器模型
2.3训练概述
2.4解码概述
2.5注意力
2.6评估
3. 预处理
4. 训练
5. 解码
5.1诊断
5.2一般问题
5.2.1稀有词和非登录词
5.2.2解码输出的短部分、截断部分或忽略输入部分
5.2.3重复解码输出
5.2.4多样化缺失
5.3部署
6. 结论
7. 致谢
▌序言
神经网络最近在机器学习的许多任务中取得了最先进的效果,包括自然语言处理,如情感理解和机器翻译。在NLP领域,一些核心任务,包括生成文本,以一些输入信息作为条件。在前几年,文本生成的主要技术是基于模板或以规则为基础的系统,或是易于理解的概率模型,如N-gram或对数线性模型。然而,这些规则和统计模型具有良好的解释性且效果不错,但是,在规则或基于模板的模型的情况下,要求大量的人工工作来扩大规模,并随着训练数据的增加而趋于饱和。另一方面,尽管文本的神经网络模型取得了广泛的成功,但其可解释性不强且有时表现不佳。图1描述了在这两种系统之间的权衡。
为了方便其他使用神经文本生成系统采用,我们详细地介绍NTG系统开发一些实用的建议。其中包括我们对训练和解码程序的简要概述,以及训练NTG模型的一些建议。主要介绍在解码过程中诊断问题和解决问题方法的建议。训练模型往往需要很长的时间来训练模型,比较好的方法是调整解码程序,因此,我们有必要了解如何在重新训练之前快速调整解程序。图2演示了改进模型训练和解码过程中,不同组件的反馈回路(feedback loops)。
尽管研究领域越来越多,关于如何进行最佳实践的方法变得分散,往往依赖于特定的模型体系结构。同时,本文提出了启动参数,本指南的目的是为那些刚开始不可知的体系结构提供实践指导,与误差分析的方法是相反的。首先阅读背景部分可能会有所帮助,剩下的部分读者可以单独阅读。
▌本指南的重点
本指南着重于对文本生成任务中神经编码器和解码器模型(带有注意机制)的训练和解码过程给出意见。大致来说,源和目标被假定为几十个符号序列。本指南的重点是解码过程。除了提出改进模型训练和解码算法的建议外,我们还简单地介绍了预处理(第3节)和部署(第5.3节)。
▌本文的局限:本文不涉及的内容
在讲解之前,我们将描述本指南不涉及的内容,以及当前神经文本生成模型的一些局限性。本指南不考虑以下几点:
自然语言理解和语义。虽然word embedding工作已经取得了很好的效果,但是如何学习句子的“想要的向量”依然是令人难以捉摸的。正如前面我们也不考虑序列标签或分类任务。
如何捕获长期依赖关系或维持全局共性。这仍然是一个挑战,因为维数灾难以及神经网络无法从下一步预测训练目标中学习更多抽象概念。
如何将模型与知识库或其他结构化数据结合起来,这些知识数据都不能在短文本中提供。最近的一些工作为利用知识库使用了指针机制。
因此,虽然我们专注于自然语言,但准确的说,本指南并不包括需要生成文件或更长的描述结构化数据的自然语言生成(NLG)任务。我们主要关注的是那些目标是一个单一的句子的任务,因此是“文本生成”而不是“语言生成”。
尽管这个领域发展很快,仍有基于规则或模板的方法往往是唯一合理技术。例如,ELIZA中的开创性工作Weizenbaum, 1966,该工作是一个效仿心理治疗师计算机程序,仍然是基于模式匹配和生成响应规则。一般来说,基于神经的系统无法执行此类系统所需的对话状态管理。或者考虑生成大量文档集摘要的任务,由于神经系统中使用的软注意力机制,目前还没有直接的方法来处理这种规模的文本。
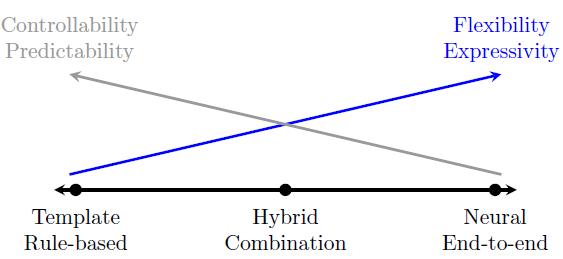
图1:描述了在神经文本生成系统和基于规则的系统两者之间的权衡
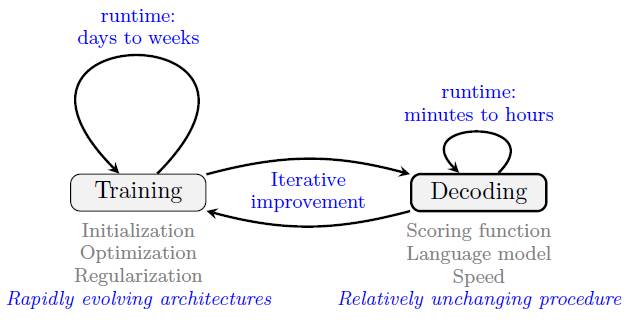
图2:NTG系统的开发周期
引用:文本自动生成研究进展与趋势 万小军 冯岩松孙薇薇
http://www.icst.pku.edu.cn/lcwm/wanxj/files/TextGenerationSurvey.pdf
为了方便其他使用神经文本生成系统采用,我们详细地介绍NTG系统开发一些实用的建议。其中包括我们对训练和解码程序的简要概述,以及训练NTG模型的一些建议。主要介绍在解码过程中诊断问题和解决问题方法的建议。训练模型往往需要很长的时间来训练模型,比较好的方法是调整解码程序,因此,我们有必要了解如何在重新训练之前快速调整解程序。图2演示了改进模型训练和解码过程中,不同组件的反馈回路(feedback loops)。
尽管研究领域越来越多,关于如何进行最佳实践的方法变得分散,往往依赖于特定的模型体系结构。同时,本文提出了启动参数,本指南的目的是为那些刚开始不可知的体系结构提供实践指导,与误差分析的方法是相反的。首先阅读背景部分可能会有所帮助,剩下的部分读者可以单独阅读。
引用:文本自动生成研究进展与趋势 万小军 冯岩松孙薇薇http://www.icst.pku.edu.cn/lcwm/wanxj/files/TextGenerationSurvey.pdf
参考文献:
Neural Text Generation: A Practical Guide, Ziang Xie
http://cs.stanford.edu/~zxie/textgen.pdf
特别提示-深度文本生成最佳实践指南下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“NTGAPG” 就可以获取深度文本生成最佳实践指南pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域22个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。

请加专知小助手微信(Rancho_Fang),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~

点击“阅读原文”,使用专知!
展开全文



