「AI扶贫」贵州河南量产数据标注师傅,却成为中国AI获胜的秘密武器!

新智元原创
【新智元导读】AI技术的发展依赖大量手工标记数据,在无人驾驶汽车、计算机视觉等领域手工标记数据都非常重要。手工标记费时费力,在国外是一项成本很高的工作,但中国在贵州等劳动力廉价的地区建立了很多数据标签公司,成本低样本大的手工标记数据,将成为中国在AI竞争中的秘密武器。
人工智能行业流传着一句古老的讖言:有多少智能,就有多少人工。
中国人工智能崛起速度如此的迅猛,引起了老牌智能强国美国越来越紧密的关注。就在不到一个月前,中科院院士、中国科学技术大学教授潘建伟等人与德国、荷兰的科学家合作,在国际上首次实现了20光子输入60×60模式干涉线路的玻色取样量子计算,在四大关键指标上均大幅刷新国际记录,逼近实现量子计算研究的重要目标“量子霸权”!
还没有完全脱离对中国“山寨”“抄袭”印象的外国人,难以理解为什么中国在人工智能这样的高尖端技术方面,走的这么快、这么远?速度远远自己国家?
他们观察中国的人工智能发展,分析其中的原因,预测未来的走势。他们意识到,并非所有国家有能力以及魄力,像中国这样投入如此大量资金去扶持一个产业。
AI发展的三大支柱:数据、算法、算力,算法和算力差距显然没有那么大。于是他们盯上了AI的基石:数据。
谷歌AI和谷歌大脑负责人Jeff Dean曾在公开场合这样强调数据对于人工智能算法的重要性:
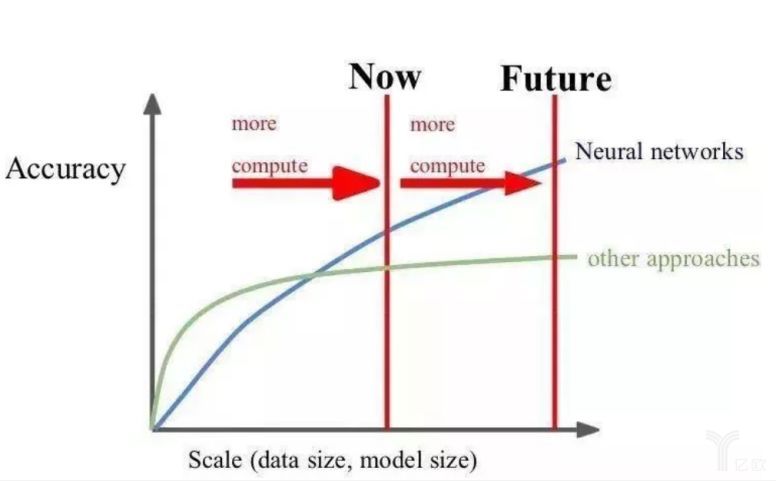
可以看到,深度学习算法精度的提升严重依赖于数据,也就是说,谁掌握了更多的数据、更精准的数据,那么谁的算法精度也就会更领先一步,谁的AI发展速度自然就更快一些。
数据是人工智能赖以发展的基石,可他偏偏又是劳动密集型的。如果说算法和算力体现的是人工智能的“智能”部分,那么数据标注就体现了“人工”。
数据标注没有什么神秘性,很多时候一个训练有素的技工可以非常出色的完成数据标注任务。
Vice曾有记者实地探访河南AI村,考察那些给人工智能贴标的新“富士康工人”;支付宝公益基金会、阿里巴巴人工智能实验室联合中国妇女发展基金会在贵州铜仁万山区启动了“AI豆计划”,作为一种 “AI+扶贫”的公益新模式。
像河南、贵州这些从业者不需要背井离乡,培训后即可上岗。
这就导致数据标注一直以来存在感极低。从下图我们可以看出,数据标注占据了一个机器学习任务25%的时间。
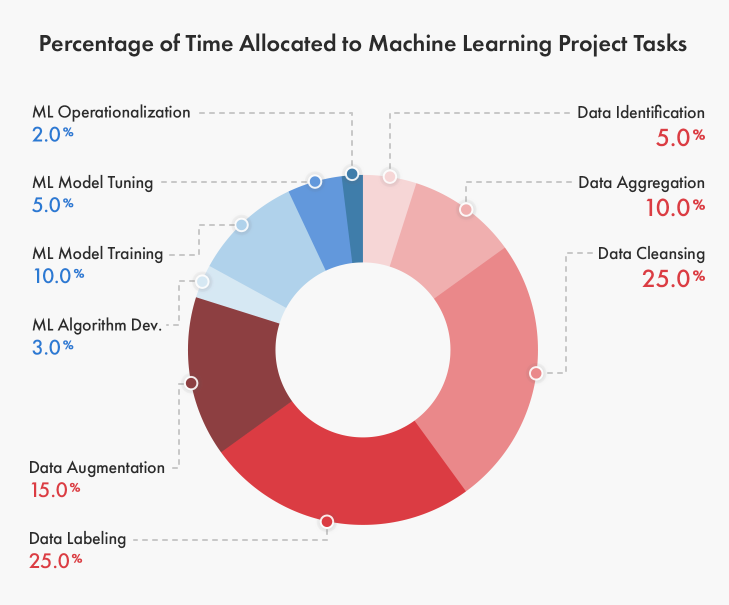
实际上,虽然表面上看起来数据标注毫无技术含量可言,实际上却是人工智能成功的关键制约因素之一。只有给算法投喂足够精准的数据,才有可能将其落地用于实际场景中。
数据标注是如此的不显眼,又如此的重要,称其为军备竞赛并不为过。
实际上,中国人工智能的迅猛发展,和当年中国经济发展颇有些相似之处。开局都是用劳动密集型项目,用低成本迅速扩大规模占领市场。
相比欧美等国而言,我们海量的劳动力资源以及相对低廉的劳动力成本,成为克敌制胜的攻坚利器。人工数据标注弥补了我们在算法和算力上的差距,加速了我们赶超对手的步伐。
虽然现在各种自监督学习、半监督学习等方法的提出,试图不断的降低对人工标注数据的依赖,然而就该目的实现尚有很长一段路要走。
根据智研发布的《2019-2025年中国数据标注与审核行业市场专项分析研究及投资前景预测报告》显示:中国数据标注与审核行业快速发展,2018年市场规模已达到52.55亿元,其中,有三分之一是AI公司内部的标注部门消化,
人工智能外包公司、人工智能企业部门、第三方数据标注与审核公司三分市场。报告预测至少在未来的5年内,数据标注行业的增长空间还很大,数据标注的市场才刚打开,数据需求将紧随人工智能的大规模落地引来一波爆发式增长。
经济学人一篇文章认为,中国虽然依旧缓慢,却在不断缩短和美国之间的差距。精美的美国人自然早就嗅到了危机,将数据标注是为是一场结结实实、实实在在的军备竞赛。
随着人工智能技术的不断发展,技术含量低的数据标注基础性的工作也在趋于减少。取而代之的是更偏情绪判断、考验理解能力甚至推理能力的数据标注任务。
而数据标注服务也从通用、开源、免费、集中走向细分、定制、收费、众包,可以想象未来将会有出现经过严格培训、更专业化的数据标注师,数据标注行业的进入门槛也开始拉大差,专业化、场景化、定制化将成为行业趋势。
数据标注,AI的基石,正在越砌越厚、越垒越高。
展开全文



