[Google]BERT压缩到7MB!最新基于最优子词和共享投影的极限语言压缩模型
【导读】预先训练的深度神经网络语言模型,如ELMo、GPT、BERT和XLNet,最近在各种语言理解任务上取得了最先进的性能。然而,它们的大小使得它们在许多场景中的应用不合实际,尤其是在移动设备和边缘设备上。特别是,由于输入词汇量和嵌入维数较大,输入词嵌入矩阵占模型内存占用的很大比例。知识蒸馏技术在压缩大型神经网络模型方面取得了成功,但在生成词汇量与原始教师模型不同的学生模型方面效果不明显。本文介绍了一种新的知识蒸馏技术,用于训练词汇量显著减少、嵌入和隐藏状态维数较低的学生模型。具体地说,我们采用了一种双训练机制,同时训练教师和学生模型,从而为学生词汇获得最佳的单词嵌入。我们将此方法与学习共享投影矩阵相结合,共享投影矩阵将分层知识从教师模型转移到学生模型。我们的方法能够将BERT_Base模型压缩60倍以上,只是稍微降低下游任务指标,就可以得到内存不足7MB的语言模型。实验结果还表明,与其他先进的压缩技术相比,该方法具有更高的压缩效率和精度。
原文链接:
https://www.zhuanzhi.ai/paper/04680670e59b98f5305f30c7b57963e2
01
介绍
最近,上下文感知的语言模型如 ELMo,GPT和XLNet表明,在各种NLP的任务大大优于传统的词嵌入模型包括Word2Vec和GloVe。这些预先训练好的语言模型,在对下游语言理解任务进行微调时,如情感分类、自然语言推理和阅读理解取得了最先进的性能。然而,由于这些模型含有大量的参数(通常超过数亿个参数),使得其在资源受限的任务中受到极大的限制,例如在移动设备和边缘设备上进行实时推理。
除了利用模型量化技术为了降低参数的浮点精度,最近的重要研究集中在知识蒸馏技术。在这里,目标是通过借用知识(例如通过软预测标签分布),从更大的预训练教师模型中训练一个小足迹的学生模型。
然而,以往研究忽略的一个重要瓶颈是输入的词汇量及其相应的词嵌入矩阵,通常占所有模型参数的很大比例。例如, BERT_Base模型的嵌入表,包括超过30K的单词标记,占模型大小的21%以上。虽然已有关于减少NLP模型词汇量大小的工作,但蒸馏技术无法利用这些,因为它们要求学生和教师模型共享相同的词汇量和输出空间。这严重限制了他们进一步缩小模型尺寸的潜力。
我们提出了两个新的想法来提高知识蒸馏的效率,特别是对BERT来说,其重点是将模型大小降低到几兆字节。我们的模型是第一个提出使用更小的词汇量来描述学生模型的模型。此外,我们的模型并没有仅仅从教师模型的最终层输出中蒸馏,而是利用分层的教师模型参数来直接优化学生模型中相应层的参数。具体来说,我们的贡献是:
双训练:我们的教师和学生模型具有不同的词汇表和不兼容的标记,用于相同的序列。为了在蒸馏过程中解决这个问题,我们在单个序列中向教师模型提供教师词汇标记化和学生词汇标记化的混合词汇。与掩码语言建模任务相结合,这鼓励了教师和学生词嵌入的隐式对齐,因为学生词嵌入可以作为上下文来预测教师词标记的单词,反之亦然。
共享变量投影:为了减少隐藏状态维度带来的信息损失,我们引入了一个单独的损失来对齐教师和学生模型的可训练变量。这允许更直接的将知识逐层转移到学生模型中。
使用双训练和共享变量投影的组合,我们训练了一个12层的高度压缩的学生BERT模型,与教师BERT基本模型相比,最大压缩比为61.94(尺寸为48维)。我们进行了测试通用语言建模视角和下游任务的实验,证明了这两类任务都具有高压缩比的竞争性能。
02
相关工作
随着神经网络本身的普及,对神经网络模型压缩的研究也随之兴起,因为这些模型对于当时的硬件来说往往是内存密集型的。NLP应用中的模型压缩工作大致可分为四类:矩阵逼近、参数剪枝/共享、权重量化和知识蒸馏。
一系列方法试图通过低秩近似来压缩模型的矩阵参数,即使用多低秩矩阵来近似匹配满秩矩阵参数,从而减少有效模型参数的数量。另一种研究探索了基于参数剪枝和共享的方法,其中探讨了模型参数中的冗余,并尝试去除各种神经网络结构的冗余权值和神经元。
模型权重量化技术关注的是将模型权值投影到精度较低的整数和浮点数。在支持高效低精度的计算的硬件的情况下,这些方法依然有效。最近,Shen等人将量化应用于基于BERT的 transformer模型。
知识蒸馏不同于其他讨论的方法:较小的学生模型可能与较大的教师模型参数化方法不同,从而提供更多的建模自由空间。教学生模型去匹配更大模型的硬真值分布的软输出标签分布对于许多任务都很有效,比如机器翻译和语言建模。
为了不局限于教师模型输出,一些方法通过注意力转移或通过特征图或中间模型输出来进行知识蒸馏。与当前工作更相关的是,Tang等人和Sun等人采用了这些技术的变体,通过减少 transformer层的数量来压缩BERT模型。然而,如前所述,由于教师模型和学生模型的词表不兼容,并且也没有充分关注嵌入矩阵的大小,这些方法不能直接应用于我们的设置。
03
方法
我们的知识蒸馏方法的核心是减少模型词汇表中的词标记的数量。在本节中,我们首先讨论这种减少背后的基本原理以及它所带来的挑战,然后再讨论我们的技术,即双训练和共享投影。
通过知识蒸馏得到最优子词嵌入
我们遵循一般知识蒸馏范式,从大的教师模型到小的学生模型进行训练。我们的教师模型是一个12层的uncased BERT-Base,使用30522个单词标记和768维的嵌入和隐藏状态进行训练。我们教师模型参数表示为θt。我们的学生模型包括同等数量的transformer层参数用θs表示,但是拥有更小的词量以及嵌入/隐藏的维度,如图1所示。使用与BERT相同的词算法和训练语料库,我们获得了包含4928个WordPieces,并将其用于学生模型。
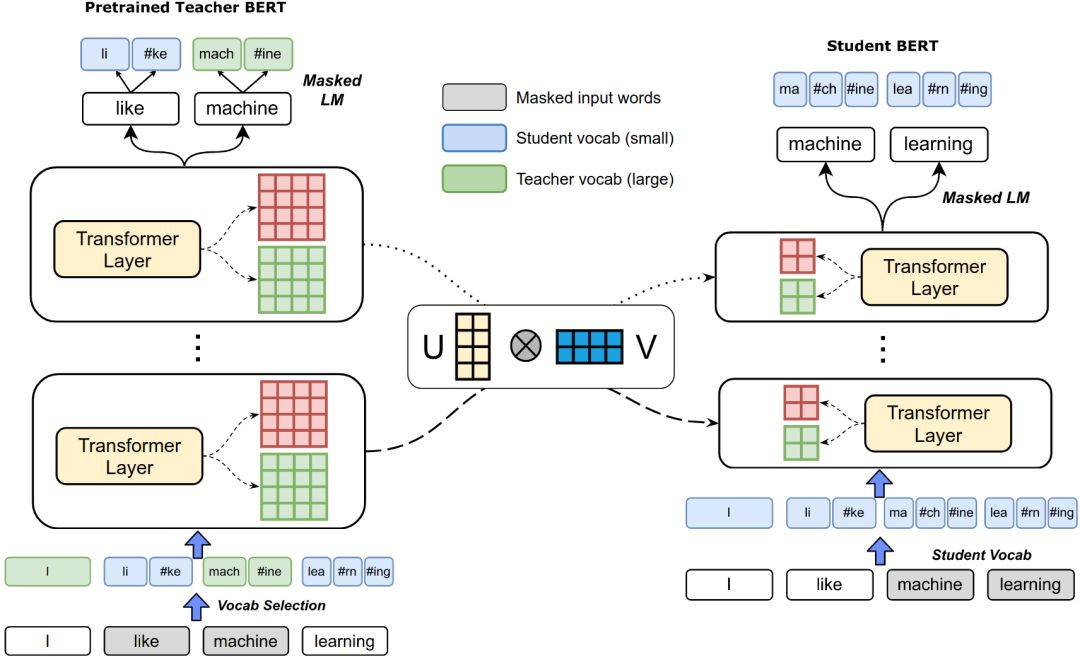
图1 用较少的学生词汇在BERT上进行知识蒸馏。(左)预训练的BERT参数教师BERT模型(如30K个词汇, 768维的隐藏状态)。(右)学生BERT模型从零开始训练,使用更少的词 (5K)和更小的隐藏状态维度(如48维)。在蒸馏过程中,教师模型随机选择一个词表来分割每个输入的单词。连接到transformer层的红色和绿色方块表示学生模型和教师模型的可训练参数——请注意,我们的学生模型具有更小的模型维度。具有代表性形状的投影矩阵U和V在具有相同维度的模型参数的所有层之间是共享的。
WordPiece标记是将贪心分割算法应用于训练语料库而获得的子词单元:选择所需数量(如D)的单词,使所用的segmentedcorpus在被使用的WordPiece数量上最小。粗略地看一下这两个词汇,发现学生词汇中有93.9%的单词也存在于教师的词汇中,这表明单词的词汇量从3万的标记减少了。
由于我们试图训练一个通用的学生语言模型,我们选择复用教师模型s的原始训练目标来优化学生模型,即,在任何微调之前进行掩码语言建模和预测下一句话。在前一个任务中,上下文中的单词是随机掩盖的,语言模型需要在掩盖的语境下预测这些单词。在后一个任务中,给定一对句子,语言模型预测这两个句子是否一致。
然而,由于学生词汇并不是教师词汇的完整子集,这两个词汇可能会以不同的方式表示相同的单词。因此,用于掩码语言建模任务的教师和学生模型的输出可能不一致。即使这两个词汇表之间有很高的重叠,也需要从零开始训练学生的嵌入,而且嵌入维度的变化妨碍了现有的知识蒸馏技术,这些技术依赖于两个模型输出空间的对齐。因此,我们探索了两种可选的方法,它们可以将知识隐式地转移到学生模型中,如下所述。
双训练
在蒸馏过程中,对于一个给定的训练序列的输入教师模型,我们建议把教师和学生词汇通过随机选择(概率p_DT, 一个超参数)标记使用学生的词汇量,从序列段与其他标记分段使用教师的词汇。如图1所示,给定输入上下文[I, like, ma- chine, learning],使用教师词汇(绿色)对单词I和machine进行分段,而使用学生词汇(蓝色)对like和learning进行分段。类似于 Lample & Conneau的跨语言训练,这促使教师和学生对同一个单词的表达对齐。这是通过掩码语言建模任务实现的:该模型现在需要学习使用教师词汇分段的上下文词汇从学生词汇中预测单词,反之亦然。
期望是学生的嵌入可以有效地从教师嵌入以及模型参数θt中进行学习。请注意,我们仅对教师模型输入执行双训练:学生模型接收仅使用学生词汇表分割的单词。此外,在掩码语言建模过程中,该模型为教师和学生的词汇表使用不同的softmax层,这取决于使用哪个词汇表来分割有问题的单词。
共享投影
仅仅依靠教师模型输出来训练学生模型可能不能很好地推广。因此,一些方法利用并试图使学生模型的中间预测与教师的预测一致。然而,在我们的设置中,由于学生和教师模型输出空间不相同,中间模型输出可能很难对齐。相反,我们寻求直接的损失最小化信息从老师对学生模型参数θt参数θs较小的尺寸。我们通过将模型参数投射到相同的空间来实现这一点,以鼓励对齐。
更具体地说,在图1中,我们计划每个可训练的变量在θtθs一样形状相应的变量。例如,对于所有的训练的768x768变量θt ,我们学习两个投影矩阵 U 和 V投影成相应的学生模型的空间变量θt’,其中d是学生模型隐藏维度模型。U和V对于该维度的所有BERT模型参数都是公共的;另外,蒸馏后不需要U和V进行微调或推理。为了对齐学生变量和教师变量的投影,我们引入了定义在公式1中的一个单独的均方误差损失,其中表示向下投影(因为投影是到一个更低的维度)。
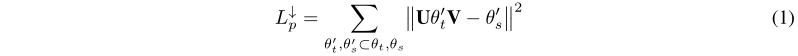
上面的损失函数将学生空间中的可训练变量对齐。或者,我们可以在θs项目可训练的变量在θt一样的形状。这样,公式2中的损失函数(向上投影)可以比较教师空间中的可训练变量。
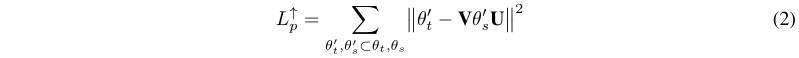
目标优化
我们最后的损失函数除了可选的投影损失外,还包括对学生和教师模型进行交叉熵修正的掩码语言损失,因为教师模型是用双词汇输入训练的,不是静态的。P(y_i=c|θs)和P(y_i=c|θt)分别表示c类学生和教师模型预测概率,1表示指标函数。下面的方程3和4定义了最终损失L_final,其中eta是超参数:
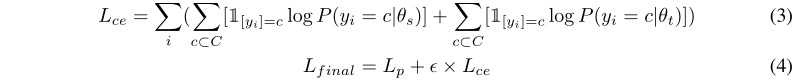
04
实验
为了评估我们的知识蒸馏方法,我们设计了两类实验。首先,我们使用一个不可见的评价语料库上的掩码词预测任务来评价所蒸馏的学生语言模型,以显式地评价该语言模型。其次,我们通过在学生语言模型输出的基础上添加一个特定于任务的仿射层来微调语言模型,该仿射层位于一组下游句子和句子对分类任务之上。这意味着对学生语言模型学习的表示的质量进行隐式评估。我们将描述这些实验,以及关于训练、实现和我们的基线的细节。
语言模型训练
在蒸馏教师BERT模型以训练学生BERT语言模型的过程中,我们使用了与训练教师相同的语料库,即BooksCorpus和英语Wikipedia,其中的空白用于将文本转换成单词。我们只使用了第3.3节中的掩码语言建模任务来计算整体的蒸馏损失,因为预测下一句的损失会略微影响性能。对教师模型输入启用双训练,,使用学生词汇对教师模型输入单词进行分段的概率p_DT设为0.5。在共享投影实验中,投影矩阵U和V使用了Xavier初始化。损失权重系数eta调优后设置为1。
值得注意的是,与许多现有的方法相比,我们直接蒸馏教师BERT语言模型(尚未对下游任务进行微调),以获得与任务无关的学生语言模型。对于后续的任务,我们对这个经过蒸馏的学生语言模型进行了微调。
蒸馏是在云TPUs上进行的,配置为4x4 pod 1(32个TPU核心)。我们使用LAMB优化了250K步骤的损耗,学习率为0.00125,批大小为4096。根据学生的模型尺寸,训练需要2-4天。
模型和基准
我们评估了三种经过蒸馏的学生模型的变体:只有教师和学生词汇的双训练(DualTrain)和教师模型参数的向下投影(DualTrain + SharedProjDown)或向上投影(DualTrain + SharedProjUp)的双训练。对于这些概念,我们用嵌入和隐藏维度48、96和192来训练学生模型,总共有9个变体,每个变体都使用一个紧凑的5000字词汇表。表1给出了关于这些模型大小的一些统计数据:我们最小的模型包含的参数少了两个数量级,并且与BERT-Base模型相比只需要1%的浮点运算。
在语言建模评估中,我们还评估了一个没有知识蒸馏的基线(称为NoKD),该基线的模型参数与经过蒸馏的学生模型相同,但从头开始直接针对教师模型目标进行训练。对于下游任务,我们与NoKD以及Sun等人(2019)的Patient Knowledge (PKD)进行了比较,他们使用教师模型s隐藏状态,将12层的BERT基模型提取为3层和6层的BERT模型。

表1 总结我们的学生模型大小与BERT-Base。#Params表示学生模型中的参数数量,模型大小以兆字节为单位度量,而FLOPS ratio是度量模型推理所需的浮点运算的相对比率。
评估任务和数据集
为了明确评估经过蒸馏的学生语言模型的广义语言视角,我们使用Reddit数据集来测量学生模型的掩模预测准确性,因为Reddit上使用的语言与训练语料库中的语言不同。数据集的预处理与训练语料库类似,只是我们不需要使用教师词汇表对其进行标记,因为我们只运行和评估学生模型。
对于下游语言理解任务的隐式评估,我们对GLUE基准测试中三个任务的学生模型进行了微调和评估:斯坦福情绪树库(SST-2),一个具有67K训练实例的双向句子情绪分类任务,微软研究释义语料库(MRPC),一个双向句子对分类任务,识别释义,3.7K训练实例,多体裁自然语言推理(MNLI)是一种具有393K训练实例的三向句子对分类任务。对于类型匹配和类型不匹配的前提-假设对,有单独的开发和测试集;我们仅在与版本匹配的开发集上调整我们的模型。
对于所有的下游任务评估,我们使用LAMB对10个epoch进行微调,学习率为0.0002,批大小为32。由于我们的语言模型训练的最大序列长度为128个标记,所以我们不需要在阅读理解数据集上进行评估,比如需要支持更长的序列的模型。

表2 掩码语言建模任务的准确性,为蒸馏的学生模型和微调,从零开始的基线。对于我们提出的方法,我们始终能观察到更好的性能。
05
结果
表2包含不同模型的掩码词预测精度和NoKD基线。我们观察到双训练对所有的模型维度都有显著的改善,而双训练所增加的共同投影损失进一步提高了单词预测的准确性。值得注意的是,对于所有的模型维度,投影到教师空间中的SharedProjUp要比SharedProjDown表现得更好,对于48维度来说,这是很明显的。意料之中的是,从192维到96维再到48维的隐藏状态模型,性能有了明显的下降。
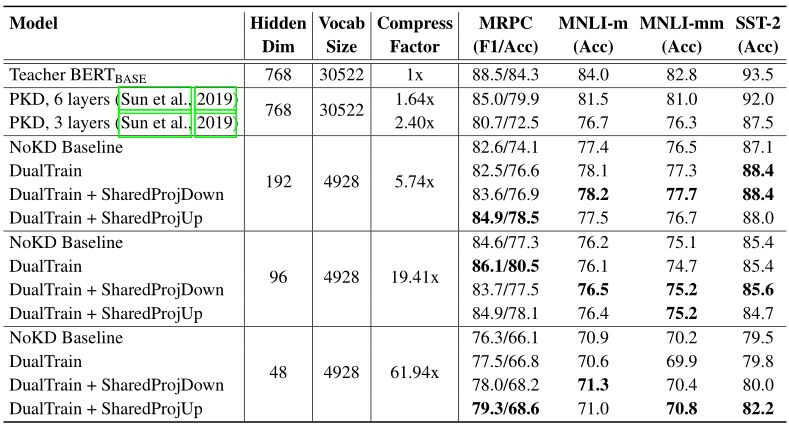
表3:从GLUE服务器获得的蒸馏模型、教师模型和下游语言理解任务测试集的基线,以及与教师BERT-Base比较的各个模型的尺寸参数和压缩比。MNLI-m和MNLI-mm是指MNLI的类型匹配和类型不匹配测试集。
注意,由于教师和学生模型的词汇量不同,教师BERT-Base模型的掩码词预测精度不能与学生模型直接比较。
表3显示了下游语言理解任务的结果,以及我们的方法的模型大小,BERT-Base教师模型,以及PKD和NoKD基线方法。我们注意到,使用我们提出的方法训练的模型比相同参数化的NoKD基线表现出更强和持续的改进,这表明双训练和共享投影技术是有效的,不会对BERT-Base教师模型造成重大损失。与PKD基线相比,我们的192维模型的压缩率高于任何一种PKD模型,其性能优于3层PKD基线,与较大的6层PKD基线相比,在任务准确性方面具有竞争力,但其精度几乎是后者的5倍。
我们做的另一个观察是,从192维模型到96维模型的性能下降是最小的(对于大多数任务来说低于2%)。对于MRPC任务,实际上,经过双训练的96维模型的准确率达到了80.5%,甚至比PKD 6层基线的准确率都要高,参数几乎是前者的12倍。最后,我们高度压缩的48维模型也有不错的表现:最好的48维模型与3层PKD模型的性能相当,后者的内存占用比前者大25倍。
06
讨论
共享的预测和模型性能:我们发现,对于下游的任务性能,双训练仍然不断地改进几乎所有实验的直接微调方法。然而,共享变量投影的效果不太明显,只有在MRPC和48维模型(即我们实验中最小的数据集和模型)上才可以看到一致的改进。这与我们对变量投影的直觉相一致,它是一种更直接的方式来提供来自教师模型内部的训练信号,在低数据或小模型场景中,这种方法更重要。然而,对于更大的模型和更多的数据,参数的线性投影可能会降低模型可用的自由度,因为线性投影是一个相当简单的对齐教师和学生参数空间的函数。
一个相关的有趣的比较是模型变量的上投影和下投影:我们注意到上投影在语言建模任务上表现得更好,而在下游任务上表现得稍好一些。一个训练好的教师模型的参数代表了教师空间中一个高质量的局部极小值,在向上投影时更容易搜索。
词汇表大小权衡:与输入词汇量有关的问题是自然语言处理中特有的问题:它们并不总是适用于其他领域比如计算机视觉,在这些领域中,少量固定数量的符号就可以编码大多数的输入。有一些方法可以减少NLP的输入词汇量,但通常不是针对模型压缩的。减少NLP模型词汇表的一个问题是,它会增加标记序列的平均长度,使模型训练更加困难。然而,在这项工作中,我们考虑短文本上的分类任务,这些任务不像机器翻译之类的任务那样受输入序列长度的影响。此外,许多实际的应用程序都以短文本输入为中心,这就是为什么需要在词汇表大小和序列长度之间进行更好的权衡。
蒸馏和微调的顺序:现有的大部分工作例如BERT和报告下游任务的结果以及一些基线工作中关于蒸馏语言模型,都是首先对教师模型的下游任务进行微调,然后再蒸馏该模型。然而,我们在这项工作中的目标,是探索BERT的语言建模能力本身的局限性,以及它在多大程度上是由其庞大的WordPiece词量所驱动的。我们把蒸馏经过微调的教师模型的实验留给未来的工作,这些模型可能会在后续任务中产生更好的结果。
07
结论
为了提高BERT的知识蒸馏效率,我们提出了两种新颖的方法,一种是使用更小的词汇量,另一种是使用更小的嵌入和隐藏因子。我们的双训练机制鼓励教师和学生WordPiece嵌入的隐式对齐,而共享变量投影允许更快和直接的将知识逐层转移到学生BERT模型。结合这两种技术,我们训练了一系列高度压缩的12层学生BERT模型。对这些模型的评价,包括通用的语言视角和四个标准化的下游任务,证明了我们提出的方法在模型准确性和压缩效率方面的有效性。
未来一个有趣的方向是将我们的方法与现有的工作相结合,以减少学生模型中的层数,并探索其他方法,如低秩矩阵分解,以将模型参数从教师空间转移到学生空间。此外,在训练嵌入时考虑单词标记的频率分布可能有助于进一步优化模型大小。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



