深度强化学习首次在无监督视频摘要生成问题中的应用:实现state-of-the-art效果
【导读】近日,针对视频摘要自动生成中大多数方法均为多阶段建模的问题,来自中国科学院、伦敦大学玛丽皇后学院的学者发表论文提出基于深度强化学习的无监督视频摘要方法。其方法在一个端到端的强化学习框架下,利用一个新的奖励函数对视频摘要的多样性和代表性进行综合考虑,生成的视频摘要不依赖标签或用户交互。在训练期间,本文设计了新颖的奖励函数以判断生成摘要的多样性和代表性。本文在两个基准数据集上进行了大量实验,结果表明,本文提出的的无监督方法不仅超越了其他先进的无监督方法,甚至超过了大多数已发表的有监督方法。
论文链接:https://arxiv.org/abs/1801.00054

▌摘要:
在视频数据大规模爆炸的今天,如何提高视频的浏览效率是很重要的,视频摘要旨在生成简短、简洁的文字总结,以表达原视频的多样性和代表性,从而提高视频浏览速度。本文中,作者将视频摘要问题形式化为连续决策过程,并且开发了一个深度摘要网络(deep summarization network, DSN)来生成视频摘要。DSN为每个视频帧生成一个预测概率,这个概率用来指导选择视频帧以产生视频摘要。为了训练DSN,本文提出一个端到端(end-to-end)的强化学习框架,并设计了一个新的奖励函数对上述两点进行综合考虑,生成的视频摘要不依赖标签或用户交互。在训练期间,奖励函数可以判断生成的摘要的多样性和代表性,而DSN通过学习产生更多样化和更具代表性的摘要,进而获得更高的回报。 由于标签不是必需的,因此提出的方法是无监督的。 作者在两个基准数据集上进行了大量实验,结果表明,提出的无监督方法不仅胜过了其他先进的无监督方法,而且超过了大多数已发表的有监督方法。
▌介绍:
随着近年来在线视频的爆炸式增长,视频摘要受到越来越多的关注,业内产生了很多方法来提高大规模视频浏览效率。最近,循环神经网络(RNN),特别是长短期记忆(LSTM)模型提出以后,被广泛用于建模视频帧的序列模式,以及解决端到端训练问题。Zhang 等提出一个深度结构,通过组合双向LSTM网络和行列式点过程(Determinantal Point Process, DPP)模块,提高摘要的多样性。他们利用有监督学习来训练DPP-LSTM,既使用了视频级摘要又使用了帧级的重要性得分。在测试阶段,DPP-LSTM同时预测重要性分数并输出特征向量,这两个输出同时用于构建DPP矩阵。由于要进行DPP建模,DPP-LSTM需要分两阶段进行训练。
尽管DPP-LSTM与很多基准方法相比展示了最先进的性能,作者认为有监督的方法不能充分挖掘基于深度网络的视频摘要的潜力。因为在视频中不存在绝对单一的groundtruth摘要。有这样一个事实,即人类对选择视频的哪个部分来进行总结是具有自己的主观意见的。因此,设计更有效的视频摘要方法,应该较少地依赖标签。
Mahasseni等提出一个对抗学习框架来训练DPP-LSTM。在学习过程中,为了使DPP-LSTM选择更具有判别性的帧,DPP-LSTM选择关键帧,并且使用一个判别网络判断一个通过关键帧合成的视频是否真实。虽然他们的框架是无监督的,但对抗性使得训练不稳定,可能导致模型崩溃。 就提升多样性而言,如果没有标签的帮助,DPP-LSTM不能从DPP模块获得最大的收益。 由于在DPP-LSTM之后用于视频重建的基于RNN的编码器-解码器网络需要预训练,所以它们的框架需要多个训练阶段,这在实践中并不高效。
在本文中,作者将视频摘要定义为一个序列决策过程(sequential decision-making process),并开发一个深度摘要网络(DSN)来总结视频。 DSN具有编码器-解码器架构,其中编码器是对视频帧执行特征提取的卷积神经网络(CNN),解码器是双向LSTM网络,产生基于动作选择一个帧的概率。为了训练DSN,本文提出了一个端到端的、基于强化学习的框架,该框架具有多样性-代表性(diversity-representativeness, DR)奖励函数,综合考虑多样性和代表性来生成摘要,并且完全不需要依赖标签和用户交互。
DR奖励函数的启发来自产生高质量视频摘要应该具有的一般标准。 具体而言,奖励函数包括多样性奖励和代表性奖励。多样性奖励衡量的是选择的框架彼此之间的差异程度,而代表性奖励计算框架和最近选定框架之间的距离,这实质上是k-中心点(k-medoids)问题。 这两个奖励相辅相成,共同激励DSN生成多样化,有代表性的摘要。这个学习策略背后的思想是考虑人类如何总结视频。 据作者所知,本文是第一个将强化学习应用于无监督视频摘要的工作。
DSN的学习目标是最大化期望的奖励。 作者使用强化学习(RL)来训练DSN主要考虑两个原因:首先,本文使用RNN作为其模型的一部分,并关注无监督学习。 RNN需要在每个时间步骤接收监督信号,但是其奖励是在整个视频序列上计算的,即它们只能在序列结束后才能获得。 为了提供仅在序列结束时提供的奖励的监督信息,作者很自然地选择了RL。 其次,作者猜想DSN可以从RL中获得更多的收益,因为RL本质上是通过迭代地强制代理器(agent)采取更好的行动来优化其行为(帧选择)机制。 然而,在正常的有监督/无人监督环境下,优化行为机制并不特别突出。
由于训练过程不需要标签,提出的方法可以完全无监督。 为了适应有可用标签的情况,作者进一步将无监督方法扩展到有监督版本,方法是添加一个监督目标,直接最大化选择带标注的关键帧的对数概率。 通过学习标签中编码的高级概念,DSN可以识别全局的关键帧,并产生与人标注的摘要质量一致的摘要。
在两个数据集SumMe和TVSum上进行了大量的实验,对提出的方法进行了定量和定性的评估。 定量结果表明,无监督方法不仅胜过其他最先进的无监督方法,而且甚至超过了大量有监督方法。 更令人印象深刻的是,定性结果表明,用无监督学习算法训练的DSN可以识别与人类选择一致的关键帧。
本文的主要贡献如下:(1)作者开发了一个端到端的基于强化学习的DSN训练框架,在这个框架下作者提出了一个无监督的奖励函数,它同时考虑了生成摘要的多样性和代表性。 据作者所知,本文的工作是第一个将强化学习应用于无监督视频摘要的工作。 (2)将无监督的方法扩展到有监督的版本以充分利用标签。 (3)对两个基准数据集进行了大量的实验,证明了提出的无监督方法不仅胜过了其他先进的无监督方法,甚至超过了大多数有监督方法。
▌模型简介
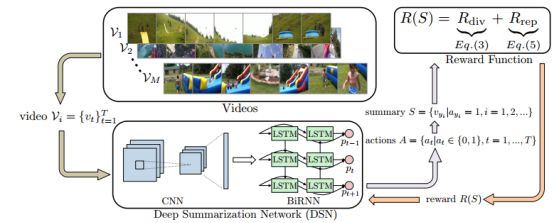
图1:通过强化学习训练深度摘要网络(DSN)。DSN接收一段视频,并且采取行动A(一系列二进制变量),选择视频的哪部分作为摘要S。其中,模型基于摘要的质量(多样性和代表性)来计算反馈奖励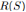
在训练时,DSN会接收到一个奖励R(S),来评估生成的摘要。而DSN的目标是不断生成高质量的视频摘要,让奖励最大化。通常,高质量的视频摘要必须既有代表性,又丰富多彩。为了达到这一目的,研究人员提出了一种新颖的奖励方式,它由多样性奖励Rdiv和代表性奖励Rrep组成。
在多样性奖励中,Rdiv可以用以下公式表示:
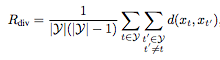
y表示已选中的帧,d(xt,xt')是多样化公式,如下表示:
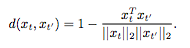
选出的视频帧越多样(越不相像),agent收到的多样性奖励越高。
而代表性奖励函数主要是测量生成的摘要是否能总结原始视频,研究人员将其看成k中心点问题,将Rrep定义为:
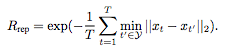
在这个奖励之下,agent能够选出最接近特征空间聚类中心的帧。
最后,Rdiv和Rrep共同工作,指导DSN学习:
R(S)=Rdiv+Rrep
▌实验分析
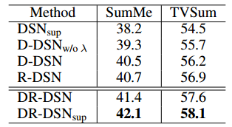
表1:提出的方法的不同变体在数据集SumMe和TVSum上的结果。
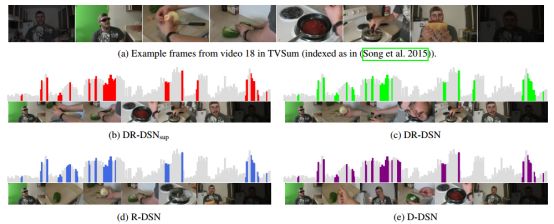
图2:由不同方式产生的数据集TVSum中视频18的视频摘要。(b)至(e)中的浅灰色条对应于groundtruth重要性分数,而有色区域对应于不同模型的选定部分。
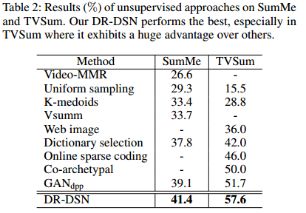
表2:无监督方法在数据集SumMe 和TVSum的结果。我们的DR-DSN效果最好,特别是在数据集TVSum中,我们的方法大大超过其他方法。
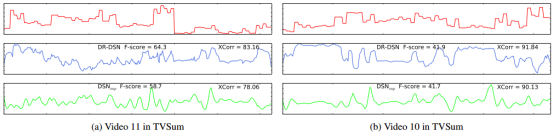
图3:Groundtruth(顶部)和通过
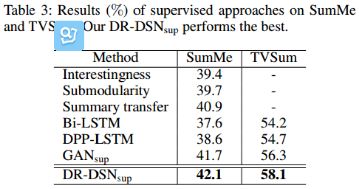
表3:有监督方法在数据集SumMe 和TVSum的结果,我们的 效果最好。
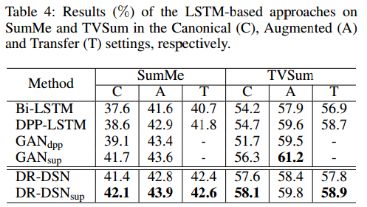
表4:基于LSTM的方法在数据集SumMe 和TVSum的结果,分别在Canonical (C), Augmented (A) 和Transfer (T) 设置进行试验。
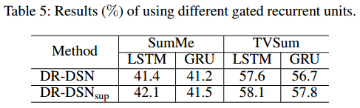
表5:使用不同门限循环单元的效果。
▌结论
在本文中,作者提出了一个不需标签的强化学习算法来解决无监督的视频摘要问题。 在两个基准数据集的大量实验表明,使用提出的基于无监督奖励函数的强化学习方法在性能上优于其他最先进的无监督方案,甚至胜过了大多数有监督方法。
原文链接:
https://arxiv.org/abs/1801.00054
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



