【论文笔记】基于文本语料库中分类法学习的综述:问题、资源和最新进展
分类法是由IS-A关系链接的概念组成的一种语义层次结构。虽然大量的分类法是从人工编译的资源(如维基百科)中构建的,但是从文本语料库中学习分类法已经受到越来越多的关注,并且这种学习方法对于长期和特定领域的知识获取是必不可少的。本文综述了近年来自由文本分类法构建的最新进展,将相关子任务重组为一个完整的框架。我们还概述了评估资源,并讨论了未来研究的挑战。
原文链接:
https://aclweb.org/anthology/D17-1123/

介绍
分类法是一种语义层次结构,这种层次结构是通过IS-A关系组织相关概念,它表现出许多改进NLP和IR任务的能力,例如查询理解、个性化推荐、问答等等。它还支持各种实际应用,包括信息管理、电子商务和生物医学系统。因为有大量的可用网络数据,许多分类法都是从人工编译的资源中构建的,如维基百科、维基数据等。但即使是大型的分类法也可能缺乏特定领域及长期知识。最近,人们已经开发出了几种从文本语料库中归纳出分类法的方法,但是对于大型分类法可能缺乏特定领域及长期知识的问题还远未解决,其中的主要原因有三个:
一、文本,正文可能在大小、主题和质量上有所不同。它不太可能为所有场景开发一个“一刀切”的解决方案;
二、自由文本分类法的准确性通常低于许多基于维基百科的分类法,这是因为从文本中完全提取知识是非常困难的;
三、分类学习没有得到充分的研究。
本文从文本语料库出发,将相关子任务重组为一个完整的框架,综述了分类法构建的最新进展。子任务包括下位词获取、上位词预测、结构归纳等,并对资源、评估指标和最新研究成果进行了总结。此外,本文中还讨论了未来研究的问题和方向。
分类构建技术
基于自由文本的分类法构建系统通常分为两个步骤:
一、利用模板法或分布方法抽取IS-A关系对;
二、将抽取的IS-A关系对数据构造出完整的分类结构。在下文中,我们对于模板法和分布方法进行介绍。
模板法
传统的模板方法是如果x和y出现在同一个句子中并且满足某个特定的模式,则一个术语对(x,y)之间存在IS-A关系。该领域最早且最具影响力的就是Hearst,他是这一领域的重要研究者,他设计了几种词汇模板来获取IS-A关系对。典型的模板是“[C] such as [E]”,其中[C]和[E]是名词短语的占位符,[C]和[E]分别被视为IS-A关系对(x,y)的超(类)y和下(实体)x。Probase也是基于Hearst模式,它由数十亿个网页构成。Probase包括265万个概念和2076万个IS-A关系。Kozareva和Hovy使用Hearst模式从网页中归纳出分类法。
传统的模板方法虽然也有一些成功的应用,但这些模板过于具体以至于无法涵盖所有语言环境,因此召回率会很低。简单模板匹配因为未知常用语、错误表达、抽取不全和歧义问题而容易出错。因此在下一部分中,我们总结了提高模板法精确度和召回率的关键技术。需要注意的是,一个健壮的IS-A关系提取系统可以结合多种技术来实现高精度和召回率。
改进召回模板泛化的方法
有几种可以提高召回率的方法:通过语言规则扩展原始Hearst模式或者学习更广泛的词汇句法模式。如,Ritter等人将Hearst模式中的名词短语“[E]”(即候选下位词)用一个K名词短语列表替换从而增加召回率。Luu等人设计了更灵活的模板,在这种模板中,几个单词可以互换。Snow等人使用两个术语的依赖路径来表示这样一种模板,其中两个术语的句法和词汇连接都可以被建模。这种做法比表面匹配更能抵抗噪声,所以被许多关系提取系统所采用。
但文本语料库生成的模板数目太大了容易造成特征稀疏问题,所以需要从这些“原始”模板中学习更多的抽象模板从而提高这些模板的通用性,从而提高召回率。Navigli和Velardi引入了“star pattern”的概念(使用通配符替换句子中的低频实体词)。许多普通模板都是通过对“star pattern”进行聚类才创建出来的。在PATTY系统中,依赖路径上的词子集被它们POS标记、本体类型或通配符所替换。
迭代抽取
由于语言的歧义和语义漂移,迭代抽取错误的关系往往是从过于泛化的模板中抽取的。与上述方法相反,另一个方法是使用非常具体的模板。Kozareva等人使用“doubly-anchored”模板(例如,“汽车,如福特和*”)来获取特定上位词的下位词,并通过bootstrapping loop扩展上位词和下位词。将每一个模板作为一个搜索,并将搜索引擎结果作为web语料库。这种方法的优点是术语的歧义可以通过“doubly-anchored”模板来消除。类似于Kozareva和Hovy,Carlson等人提出的,新的IS-A关系和上位词模板可以以自动方式迭代抽取。
上位词推断
这种方法克服了x和y必须出现在同一个句子中的限制。Ritter等人以为,如果y是x的一个上位词,同时另一个术语x’与x非常相似,那么y很可能是x’的一个上位词。同时他们训练了HMM来研究比基于向量法更好的相似性预测。在句法语境包容(SCS)方法中,给定一个非分类关系r,S_r(x)为对象集合,因此对于每个s∈S_r(x),x和s都有关系r。如果S_r(y)主要包含S_r(x),反之不成立,那么我们可以推断y是x的一个上位词。
下位修饰词的句法推断可以产生附加的IS-A关系。例如,机器可以根据“灰熊”的头部词是“熊”推断灰熊是熊。在Taxify系统中,如果将一个多词术语添加到分类法中,系统会将该术语的语言头词作为其直接的上位词。Suchanek等人将概念上的维基百科类别链接到基于类别头词的WordNet语法集上。Gupta等人引入语言启发式从维基百科类别网络中导出IS-A关系。除了英语,类似的观察也适用于汉语。
提高准确率的方法
可信度评估在提取候选IS-A关系对(x,y)后,可以用统计方法评估可信度得分,低分数的关系会被抛弃。在KnowItAll系统中,借助搜索引擎点击次数来计算x和y的点互信息(PMI)。在Probase中使用似然概率来表示y是x上位的概率,并反向确定x是y下位的概率。Wu 等人进一步计算基于朴素贝叶斯分类器抽取的IS-A对的似然概率。除提取结果统计外,Luu等人还考虑了外部因素,例如包含在WordNet和词典中概念的内容,以及数据源(如网页)的可信度等。Dong等人在建立谷歌知识库方面的经验表明,评估可信度得分对于从不同抽取器获取和融合知识至关重要。
否定的证据可以用来估计可信度分数是不可取的。最近有这样一种方法,使用上位词和同下位词模板的统计数据,给每一关系对一个正分和一个负分。实验结果表明,使用负分数可以通过舍弃模型中被错误预测为IS-A关系的同下位词关系来提高精确度。
基于分类的验证
这种方法通过训练分类器f来预测一对提取对(x,y)的正确性。选择的模型通常包括SVM(支持向量机)、logistic回归和神经网络。f的特征可以大致分为以下几类:表面名称、句法、统计、外部资源等。记载中,Snow等人在对应的词汇句法模式中使用x和y之间的依赖路径作为特征。Ritter等人引入一个基于对和Hearst模式匹配频率的特征列表,例如语料库中“x is a y”的匹配数。表面名称特征考虑x和y的构词方式,包括x和y是否大写,x是否以y结尾。Bansal 等人进一步利用语料库和维基百科摘要中Hearst模式匹配的统计数据来进行研究。这是因为维基百科摘要中包含可用于推断IS-A关系的概念定义和概述。
像Surrz等人研究的那样,使用模板法和分布式方法表示的x和y也可以增强分类器的性能。这种技术可以被看作是模板法和分布式方法的结合,这将在下面详细讨论。
分布方法
分布方法根据术语的分布表示,通过无监督模型或监督模型预测术语之间的IS-A关系。由于它们直接预测IS-A关系而不是提取语料库中的所有IS-A关系,因此我们简要介绍如何获取关键项以形成候选IS-A关系的术语对。
种子数据集抽取
预测IS-A关系的第一步是生成候选的下位词/上位词。对于自由文本,下位词/上位词通常是种子数据集,这些种子数据集频繁出现在语料库中的名词、名词短语和/或命名实体。种子数据集可以通过在语料库中应用POS标注或NER工具识别出来,然后使用基于规则的提取器提取。现有的关键词或关键词短语提取器也可用于自动识别这些术语。
对于研究特定领域的分类法,提取种子数据集后的一个重要的后处理步骤是领域过滤。这个步骤将过滤掉不包含在关注领域中的术语,提高分类精度。一个术语可以通过基于统计的剪辑进行过滤,这种剪辑包括TF、TF-IDF、域相关性、领域一致性和领域特异性得分。为了确保提取的术语是特定领域中的重要概念,现在已经有几种仅从领域限定句中提取术语的方法。特别是Navigli等人提出的,建议使用领域权重来选择定义与关注领域相关的明确术语的句子。
无监督模型
我们首先调查了用于IS-A关系识别的各种无监督模型。然后,针对这些模型引入特征表示。
分布相似性模型
分布相似性模型的早期工作主要集中在对称模型上,如cosine、Jaccard、Jensen-Shannon 发散和被广泛引用的LIN模型:
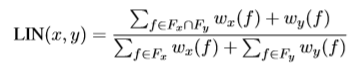
其中x和y分别是候选的下位词和上位词。F_x和F_y是x和y的特征,W_x(f)是x的特征值f的权重,但上述工作只研究了单词的语义相似度。
非对称模型根据DIH建立IS-A关系的非对称性模型。这个模型假设一个下位词只出现在它的上位词的一些上下文中,而一个上位词出现在它的下位词的所有上下文中。例如,“水果”这一概念的上下文范围比其下位词要广,如“苹果”、“香蕉”和“梨”。因此,Weeds等人提出一个简单的WeedsPrec模型,用于计算y的特征值在x特征值中的加权包含:
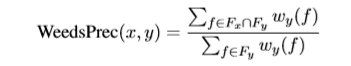
在各种研究中也有引入其他不对称模型,例如WeedsRec、BalAPInc、ClarkeDE、cosWeeds、invCL、WeightedCosine。在向量空间语义模型的早期调查中可以发现分布相似性模型的详细总结。
最近一些研究表明,DIH并不适用于所有情况。例如,“美国人”是“巴拉克奥巴马”的上位词,但“巴拉克奥巴马”的(政治相关的)语境不能被“美国人”的语境所覆盖。与下位词相比,上位词的大多数上下文信息量较小,且比较笼统。为了解决这个问题,Santus等人提出了一种基于熵的上位词检测方法SLQS。Roller等人引入选择性分布包含假设,即原始DIH是正确的,但仅适用于相关维度。
特征
对于每个术语x,特征F_x的集合是从文本语料库中生成的,其中每个特征f∈F_x代表一个上下文单词,x与之同时出现。在一些研究中,f还规定了x和f之间的句法关系。如Pado和lapata的研究,使用基于句法的向量空间模型比简单的“词袋”共现模型能更好地区分不同的词汇关系。此外,Schutze还使用了上下文词和相对于目标词的位置作为特征。Baroni和Lenci提出了一个分布式记忆框架来生成单词链接单词的特征。Yamaba等人使用原始的动名词依赖项对这些依赖项进行聚类以生成特征向量。
每个特征的值由权重函数W_x(f)确定,该权重函数量化了特征值f和相应单词x之间的统计关联。W_x(f)的选择包括(点)互信息(PPMI)、局部互信息。SVD等降维方法可以用来创建稠密向量。
监督模型
在训练集可用的情况下,用分类/排序方法训练一个基于术语对(x,y)表示的预测上位词的模型。基于嵌入空间中下位词的表示,上位词生成方法直接建立如何“生成”上位词的模型。其中无监督模型中有分布相似型模型和特征;监督模型中有分类、上位词生成方法、排序。
分类
在分类方法中,x和y最常用的表示是由预先训练好的神经语言模型如Word2Vec、GloVe和ivLBL生成的单词嵌入。
concat模型用~x⊕~y组合术语对向量训练一个类似于SVM的现成的分类器,其中~x是单词x的嵌入向量。在一些论文中,该模型被视为一个强大的基线。最近的研究指出,它存在着严重的词汇记忆问题。这意味着这种分类器学习的是术语的语义,而不是术语之间的关系。因此,当训练集和测试集明显不同时,该模型的性能较差。
为了解决这个问题,diff模型使用向量偏移作为特征,表示为~y-~x。Roller等人利用向量差和平方向量差特征提出了不对称模型。simDiff模型使用两个词上下文矩阵(即域矩阵和函数矩阵)的差异作为关系分类的特征值。此外,记载中还提到了向量的其他组合,例如向量和~x+~y和点积~x × ~y。Roller 和Erk利用分布向量中的Hearst模式,引入了一种类-PCA的迭代过程来学习concat分类器。Kruszewski等人学习从分布向量到布尔值向量的映射,其中输出向量对应于词之间的附带内容。
在神经语言模型中,出现在相似上下文中的单词具有相似的嵌入。Yu等人认为这种建模技术不足以学习IS-A关系预测的术语嵌入。对于每个单词x,他们研究了~X_0和~X_e嵌入的两种类型,分别表示当x函数作为下位词和上位词时x的嵌入。嵌入是通过基于距离边缘的神经网络训练产生的。Luu等人通过在动态神经加权网络中建立上下位词之间的上下文模型,进一步扩展了该方法。Li等人设计了一个基于负抽样的联合模型,将实体和类别联合嵌入到同一语义空间中。这种模型表现出的高性能证明,使用目标特定的嵌入比通用的嵌入更有效。
上位词生成方法
上位词生成方法通过模型是否可以将映射到接近y的向量来预测关系对(x,y)。Fu等人是该领域的先驱,他们采用统一线性投影和分段线性投影,将下位词的嵌入映射到上位词。之后,又有人提出了三种方法来扩展Fu 等人的方法。Wang和He通过更新转换矩阵并迭代来提取新的IS-A关系。当训练集和测试集在语义空间几乎没有重叠时,他们提高了分段投影模型的性能。Yamane等人通过动态聚类IS-A对,联合学习聚类数和转移矩阵。Tan等人用嵌入 “IS-A”替换过渡矩阵。像Yamane等人研究的那样,这些方法在F式测量方面与最先进的分类方法相当。此外,通过领域聚类,Fu等人提出的方法修改为对域适应的目标数据源敏感的转移学习版本。
负采样技术对提高投影学习效果是有效的。这是因为上位词关系的表示有时会与同义词、共下位词和代名词混淆。在Ustalov等人的研究中,在Fu等人的模型中增加了一个额外的正则化项以利用非IS-A关系的语义。Wang等人直接研究了非IS-A关系的表示,以便更好地区分真正的上位词关系。该方法考虑了导入式学习环境中IS-A和非IS-A关系的表示、上位词级相似度和语言规则。
排序
作为一种替代方法,Fu等人提出了一个排序模型,用来选择实体最可能的上位词。用排序模型代替分类模型并不是提取IS-A关系的常用方法,因为它的召回率很低。然而,这种方法像是专门为中文设计的。但是,由于汉语灵活的语言表达方式,所以学习汉语是一种挑战。因此,有必要建立一个高精度的汉语IS-A关系的排序模型。
讨论
在一些文献记载中,人们对于IS-A关系预测的有效方法存在一些分歧。例如,Shwartz等人声称分布方法优于基于模式的方法,而Levy等人认为分布方法基本不起作用。我们概述了研究界的主要观点,并分析了这两种方法的利弊。
模板法是基于语料库中连接x和y的词汇句法路径来提取IS-A关系对(x,y),从而显式地表达这种关系。原始的Hearst模式和比较普遍的模式已经在大量分类中使用这种方法。这样做的缺点是,使用模式作为特征可能导致特征空间的稀疏性。大多数方法要求x和y同时出现在同一个句子中。因此,召回率是有限的。此外,它们过于依赖语言,如果在其他语言中很少有类似Hearst的模式,则很难使用。像Fu等人的研究结果,他们的汉语召回率极低。
与此相反,分布方法使用从上下文中派生的单词表示,而不依赖于它的上位词和下位词。单词嵌入的使用允许机器基于整个语料库进行预测。然而,分布方法在检测特定的、严格的IS-A关系方面不太精确,并且倾向于发现术语之间的广泛语义相似性。类似于Weeds等人的研究,通过分布方法检测到的一些术语是共下位词和同义词,而不是上位词。另一个缺点是,这种方法依赖于域且模型与训练集密切相关。此外,Levy等人指出另一些问题,他们发现,有监督的分布方法实际上是在学习y是否是一个“原型上位词”,而不是x和y之间的关系,这是因为特征和是独立生成的。它们通过核函数将对内相似度与diff模型相结合,但只取得了增量改进。
尽管这两种方法都有其自身的缺点,但是人们认为基于模式和分布法是互补的。很早就有人提出了整合它们的想法,但多年来并没有引起太多关注。最近,HyperNET系统通过分布特征和基于模式的特征来表示关系对(x,y)。每个模式都由依赖路径表示,并由LSTM模型嵌入。实验表明,在两个大数据集上,联合表示明显提高了性能,F1得分分别为0.901和0.700。相比之下,最好的基于模式的方法的得分分别为0.761和0.660。基于concat模型的最优分布方法的性能得分分别为0.746和0.637。基于之前模型扩展的lexNET模型可以用来识别多个关系。
分类归纳
在对上述方法介绍后,在论文中我们总结了用IS-A关系构造分类结构的技术。
增量学习
有几种通过增量学习从“种子”分类法中构建完整的分类法的方法。Snow等人通过最大化扩展分类法的概率来丰富WordNet,这种扩展分类法基于从文本中获得的IS-A对和继承关系的证据。他们专注于提取新的实体并将它们附加到WordNet的语义层次结构中。Shen等人观察到所提取的术语可以引用分类中的现有实体或新的实体,并提出一种基于图形的方法来将这些术语链接到分类或往分类中插入新的实体。虽然这些方法在很大程度上依赖于现有的分类法,但是Kozareva和Hovy将根概念作为输入,并迭代地提取IS-A关系来扩展分类法。Alfarone和Davis进一步考虑了在特定领域无法获得“种子”分类法的问题。他们通过Hearst模式匹配和启发式规则构建了“种子”分类法。
聚类
分类学习可以作为聚类问题的一类来建立模型,在这类聚类问题中,类似的术语聚集在一起可以共享相同的上位词。采用层次聚类法将相似术语聚类成一个分类法。Song等人通过可伸缩贝叶斯玫瑰树改进分层聚类技术。Alfarone和Davis也提出了类似的想法,其中K-Medods聚类的一组术语的最低共同祖先被推断为它们的共同上位词。SCS方法也与聚类有关,因为它按非分类关系对相似的术语进行分组,并推断其上位词以提高分类覆盖率。
基于图的归纳
基于图的方法一般适合于分类目标,因为分类通常是图。Kozareva和Hovy通过在原始图中找到表示噪声IS-A关系的最长路径,推导出从根到目标项的路径。Anke等人通过乘以其边缘的域相关性得分来计算路径权重。另一个常用的算法是最优分支算法,它首先根据图的连通性(如度、中间度等)来分配边缘权值,然后根据Chu-Liu/Edmonds′s算法找到最优分支。在去除噪声边缘后,用最大权值构造有根树。Bansal等人采用因子图模型表示术语和IS-A关系。分类法的学习被视为模型的结构化学习问题,这个问题可以通过loopy belief propagation来解决。
分类法清理
分类法学习的最后一步是分类法清理,它消除错误的IS-A关系以提高质量。最近对Probase的研究表明,不正确的IS-A关系可能以循环的形式存在于分类学中。通过消除循环,可以检测到74k个错误的IS-A关系。这种循环去除工艺也适用于Deshpande等人、Fu等人、Li等人的研究。
另一个问题是实体的模糊性。如Liang等人所研究的,传递性属性不一定适用于自动构建的分类法。例如,“(阿尔伯特爱因斯坦,is-a,教授)”和“(教授,isa,职位)”并不意味着“(阿尔伯特爱因斯坦,is-a,职位)”。通过词义消歧,有一些系统已经解决了歧义问题。然而,这种问题并没有完全解决。虽然现在学习“银行”(金融机构或者 riverside)一词的多种含义很容易,但在分类法学习过程中,区分“教授”一词是指某个特定的人还是指某个职位仍具挑战性。基于Liang等人的研究,我们推断,解决完全消除歧义的分类法这个问题还有很长的路要走。
资源与分析
在本节中,我们将总结分类法学习的资源和评估指标。并讨论了研究结果及对未来研究的建议。
资源
现在已经有很多关于IS-A关系预测研究的资源。第一种是高质量的分类法。此外还有知识库和语义网络。这些系统中的知识可以用于生成远程监督模型学习的训练集。典型的英语资源包括WordNet、YAGO、WiBi和DefIE。对于英语以外的语言,请参考多语言系统、BabelNet、MultiWiBi。我们需要指出的是,这些系统并不一定都是分类法,而是包含丰富的类型层次知识。我们还总结了最近的一些测试集和统计数据,见表一。
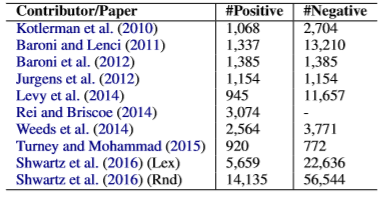
表1:IS-A关系预测的测试集
有两个共享任务是专门为分类学习设计的,即TExEval和TExEval-2。在TExEval中,目标是在四个目标领域(即化学、设备、食品和科学)构建分类法,每个领域都提供有黄金标准。这种设置已扩展到TExEval-2中的四种欧洲语言(即英语、荷兰语、法语和意大利语)。这项任务鼓励参与者使用维基百科语料库作为输入,但对数据源没有限制。在以前的研究中,一些特定领域的语料库也被用作分类的输入,包括人工智能论文、生物医学语料库、与动物、植物和车辆相关的网页和MH370、恐怖主义报告、疾病报告和电子邮件以及与特定主题相关的维基百科语料库。
评估指标
评价上位词预测算法绝非易事。给定IS-A和非IS-A术语对作为地面实况的集合,可以使用标准关系分类指标,如精度(P)、回忆(R)和F得分(F)来进行比较。
然而,评估整个分类法的质量是一项非常重要的任务,因为i)分类法的规模很大,ii)很难获得黄金标准,以及iii)应该考虑的多个方面的存在,如拓扑、正确性和覆盖率。如果黄金标准分类法可用,则将S=(VS,ES)和G=(VG,EG)表示为提取的黄金标准分类法,其中VS和VG是节点集,ES和EG是边缘集。两个共享任务中引入的评估指标简要总结如下。
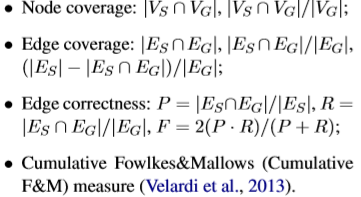
结果分析与讨论
我们第二章讨论的是一个IS-A关系预测。而本部分主要关注分类学习的整体表现。
我们首先分析两个共享任务的结果,因为结果中报告了各种方法的性能。在这两项任务中,两种模板方法始终优于其他方法。INRIASAC使用基于频率的共现统计和子串包含启发式方法提取下义词的一组上义词。TAXI对特定领域的语料库进行爬取,并使用词汇句法模式和子串进行领域IS-A关系抽取。然而,由于只有一个系统使用这种技术,分布式方法的潜力没有得到充分开发。此外,不同的系统可能会在这些任务中使用自己的语料库,因此结果并不能直接反映这些算法的“优点”。在多语种任务中, TAXI中其他语言的w.r.t.性能有很大的下降。Fu等人的研究说明了类似的问题,即当时几种有效的英语算法并不能真正适用于汉语。这种现象需要非英语语言源的特定语言算法。
对于其他的研究,虽然知识来源和领域可能有所不同,但我们注意到它们都存在低召回率问题。例如,Bansal等人、Luu等人研究结果的召回值。Navigli等人、Kozareva和Hovy等人的召回值在大多数情况下和在领域中都低于50%。虽然通过施加约束来提高精确性相对容易,但提高召回率更具挑战性,因为我们的目标是识别所有IS-A关系,无论这些关系是在一个或多个句子中显式表达还是隐式表达。当考虑低集中和动态域时,召回率低的问题会变得严重。
我们的建议
基于我们的分析,我们给出了我们的建议以提高分类学习的性能,但上述问题并没有得到充分的解决。
集合表示和深层结构
Shwartz等人认为模板法和分布式方法相结合可以提高IS-A关系提取的性能。我们建议,通过研究这两种方法如何相互加强,可以进一步提高性能。神经网络模型可以有效地学习这两种模型的更深层表示。我们认为,可以通过将从模板中挖掘的术语对之间的语义关联信息添加到分布式表述中来解决Levy等人提出的问题。
另一个相关的问题是,尽管上面提到了几种嵌入学习方法,但是用于分类法归纳的深度学习范式的成功率有限。我们认为这主要是因为很难为神经网络设计一个单一的目标来优化这项任务。因此,如何利用深度学习的热潮进行分类归纳是一个值得研究的问题。
基准和评估
分类学习的基准对于量化前端水平的表现至关重要。基准应该包含文本语料库、黄金标准和评估指标。Bordea等人在多个领域和语言中提供了一些黄金标准分类法,但不要求所有系统运行在同一个语料库上。其他研究中使用标准测试集和数据源,如我们在第3.1节中总结的。
以往的工作已经指出了现行基准和方法中的若干问题。Levy等人表示,由于词汇记忆问题,监督系统实际上表现过度。Shwartz等人表明无监督方法比有监督方法更稳健,但有监督方法优于无监督方法。CamachoCollados讨论了在分类学习系统的背景下,或在下游应用程序中的集成,上位词检测任务是否确实是评估IS-A关系的合适任务。我们可以了解到,应该进行更深入的研究以建立一个完整的,被广泛接受的评估基准。
明确且规范的术语
对于词汇分类法来说,一个术语可能有多种表面形式和意义。歧义问题使得基于分类法的应用程序容易出错。所以需要构造这样的分类法,即其中每个节点表示与其可能的表面形式及其上下文相关联的明确术语。这样,分类法自动支持实体链接,有利于IR应用(例如,web搜索)。
整合领域知识
在特定领域的语料库中,融合领域知识对于术语和关系的提取是必不可少的,但要从这些有限的语料库中获取这些知识是很困难的。通过利用来自领域知识库的数据信息,我们可以通过远程监控学习领域分类法,这种方法比现有方法具有更高的覆盖率。因此,构建基于文本语料库和特定领域知识库的分类体系是一项重要的任务。
非英语和资源不足的语言
在本文中所提到的各种研究及任务并没有被广泛的应用到资源不足的语言研究中去。具体来说,模板法虽然对英语有效,但有很强的语言依赖性。如何将现有的方法应用于与英语(如汉语、阿拉伯语和日语)明显不同的语言是值得研究的。
结论
本文综述了从文本语料库中学习分类法的研究进展。我们概述了用模板法和分布方法从文本中学习上位词的方法,并讨论了用I-A关系归纳出分类结构的方法。虽然取得了重大成功,但这项任务仍远未解决。通过解决本文所讨论的问题,我们建议在NLP和IR研究中具有巨大影响的领域和语言中构建高质量的分类。



展开全文



