【ACL2018】什么都能GAN,无监督神经网络翻译新方法
【导读】无监督神经机器翻译是最近提出的, 旨在不使用没有双语平行语料的情况下, 用各自语言来做翻译(有原始语言语料,也有目标语言语料, 但是没有对应)。本文利用了两个独立的编码器,来对源语言和目标语言进行编码,但是共享它们的一些负责提取输入句子的高级表示部分层。 此外,为了加强跨语言翻译能力,本文提出了两种不同的生成对抗网络(GAN),即局部GAN和全局GAN。 其中局部 GAN用来约束 两个Encoder能够将不同语种的句子映射的同一个语义空间; 而全局 GAN,用来约束交叉的 Encoder和 Decoder 能够做好相互翻译。这篇文章发表在ACL 2018上。
【ACL 2018 论文】
Unsupervised Neural Machine Translation with Weight Sharing

Github 代码:
https://github.com/ZhenYangIACAS/unsupervised-NMT
介绍
常见的神经网络翻译模型是有监督的, 它们通常由两部分组成: Encoder和 Decoder。 Encoder部分读入原始文本,并将它们编码成向量,Decoder部分根据向量,迭代的生成目标语句。有监督是指,训练语句的时候,我们有双语的平行语料(原始语言语句,及其对应目标语言翻译)。
无监督神经机器翻译是最近提出的, 新的神经翻译技术。旨在不使用没有双语平行语料的情况下, 用各自语言来做翻译(有原始语言语料,也有目标语言语料, 但是没有对应)。由于没有对应信息,无监督神经翻译非常有挑战性。 不过也有一个优势,就是单语料的数据集非常好收集,所以训练数据可以有非常多。
无监督神经机器翻译有一个基本假设,就是:来自不同语言,但是意思一致的句子,可以经过 Encoder编码到同一个隐藏空间的同一个表示。为了满足上述假设,很多工作都对原始语言文本和目标语言文本使用同一个 Encoder去编码它们的信息。换句话说,源语言和目标语言共享了一个编码器。 这样做有个巨大的问题,即:难以保持每种语言的独特和内部特征,比如样式(style),术语(item)和句子的结构(structure)。
为了解决这个问题,本文利用了两个独立的编码器,来对源语言和目标语言进行编码,但是共享它们的一些负责提取输入句子的高级表示部分层。 此外,为了加强跨语言翻译能力,本文来提出了两种不同的生成对抗网络(GAN),即局部GAN和全局GAN。 其中局部 GAN用来约束 两个Encoder能够将不同语种的句子映射的同一个语义空间; 而全局 GAN,用来约束交叉的 Encoder和 Decoder 能够做好相互翻译。采用上述方法,本文实现了英-德,英-法和中-英翻译任务的显着改进。
本文的贡献点:
•为了利用两个 Encoder来刻画源语言与目标语言的信息,本文提出了共享部分负责提取高级句子表示的层的方法,同时,为了让两个 Encoder能够将信息映射到同一空间,本文提出了两种不同的 GAN。
•对英德,英法和中英翻译任务进行了广泛的实验。 实验结果表明,所提出的方法一直取得巨大成功。
•将引入方向self-attention 来刻画,模型的时间序列信息。 实验结果表明,人们需要更多努力来研究NMT中 self-attention层内的时间系列信息。
本文提出的方法
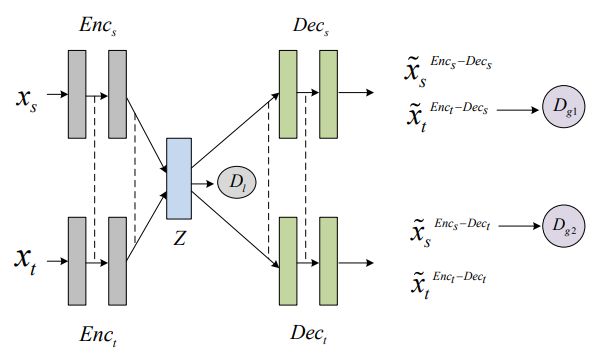
本文使用两个 Encoder来编码源文本和目标文本,每一个 Encoder和 Decoder 都有4个 block组成,每个 block是经典的 transformer的 block,即一个 multi-head self-attention ,一个 position-wise 的全连接前向神经网络。
文中也提出了使用Embedding reinforced encoder技术,使用cross-lingual embedding作为 Encoder的一部分,为 Encoder提供的多通道的信息提取,同时加强了两个 Encoder映射到同一空间的能力。
Encoder和 Decoder之间的虚线部分,即提取和分解句子的高级特征的部分被两个 Encoder和两个 Decoder共享。
水平来看上图, 路径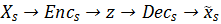
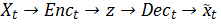
交叉来看上图,路径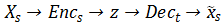
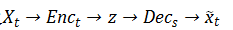
只看上图的左边部分,路径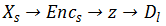
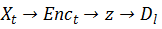
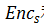
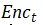
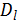
出了 局部 GAN,文章还用了两种全局 GAN,分别是路径: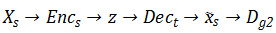
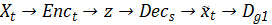
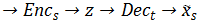
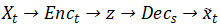
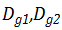
实验
文章在 WMT14英-法,WMT16 英-德,LDC 中-英 等语料上做了充分的实验。
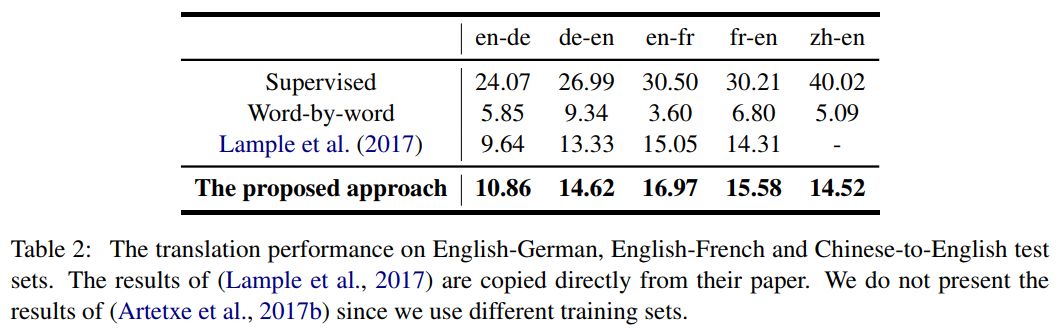
对比了目前state-of-the-art 的无监督机器翻译方法,本文提出的方法全面领先。
上图,显示了两个 Encoder和 Decoder共享层数的不同对实验结果的影响, 结果发现,共享1层,比全部共享(共享4层,即 Lample et al.(2017))和全都不共享(共享0层)都要有显著的提升, 显然,共享部分层,并保留部分独立层,能够更好的进行多语言的翻译。
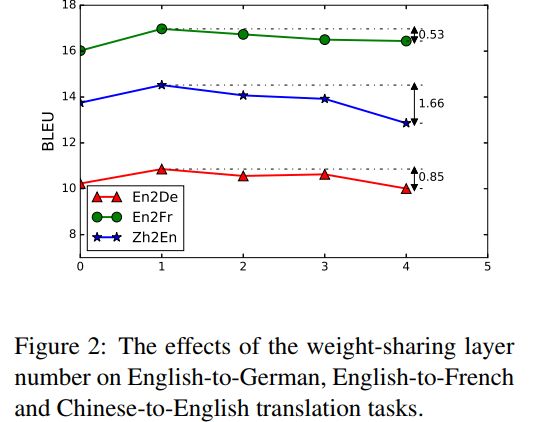
表3中,作者将本文所提出的模型的某一部分移除, 然后观察移除部分对实验结果的影响, 显然,文章中提出的每一个步骤, 都对结果有很积极的影响。
原文链接:
http://www.iri.upc.edu/files/scidoc/2024-Unsupervised-person-image-synthesis-in-arbitrary-poses.pdf
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



