【干货】为什么深度学习要使用大量数据?
【导读】深度学习与机器学习一个很重要的区别在于数据量的大小。就目前大量的实验和工作证明,数据量的大小直接影响深度学习的性能。我们都希望利用小的数据集、简单的算法就能取得不错的效果,但目前的事实是小数据集上使用深度学习往往容易过拟合。本文中作者阐述了几个大容量训练数据的场景来展示大数据对深度学习的重要性。
作者 | Ida Jessie Sagina
编译 | 专知
参与 | Yingying, Xiaowen
Why go large with Data for Deep Learning?
我厌恶面条里的卷心菜,因此我挑出了卷心菜的碎片。我是如何区分卷心菜和面条的呢?如果不是想让神经网络模拟人类,我们可能不会思考这个问题。为了在神经网络上重现这个令人惊叹的人类智慧,人们付出了巨大的努力。
机器玩跳棋和国际象棋,并赢了人类的冠军。因此我们可以设想,如果人造系统能像我们一样学习,它们会变得多么有用,并在现实生活中服务于人,比如自动驾驶汽车。

学习的演变:
人工智能的概念虽然设想的是模拟人的行为,但很快范围就被缩小为预测和分类。
决策树,聚类和贝叶斯网络可用于预测用户音乐偏好和区分垃圾邮件。虽然这种传统机器方法为许多分类问题提供了一种简单的解决方案,但更好的方法是像人类一样无缝寻求识别语音,图像,音频,视频和文本。这催生了各种深度学习方法,它主要依赖于有史以来最好的学习机制 - 人工神经网络。人工神经网络近来使Facebook,亚马逊,谷歌等科技巨头正逐步应用深度学习。弗兰克罗森布拉特在1957年设计了第一个模拟单个神经元活动的rst感知器。
虽然人类大脑的工作机制本身是相当难以捉摸的,但我们知道,大脑通过树突层中的电信号的传播识别物体和声音,并且在跨越阈值时触发正信号。下图所示的感知器模拟了这个过程。
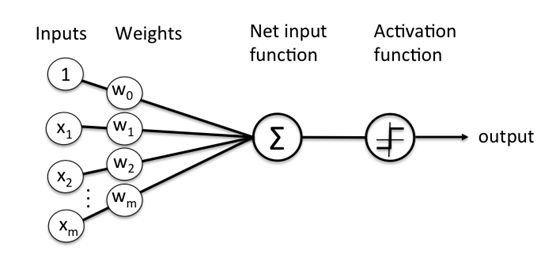
当输入的加权总和超过阈值时,将会触发输出。这只是一个单层感知机,它只能用于线性可分的函数。并像绘制一条线一样容易,一边是正例,一边是负例。但现实世界中并非如此。
图像识别——神经网络应用的主要领域之一,涉及识别隐藏在数据像素后面的大量特征。为了获取这些特征,采用了多层感知机。和单层感知机一样,将训练数据输入到输入层,经过输入层与输出层之间的许多“隐藏层”之后,将在输出层得到最终的结果。
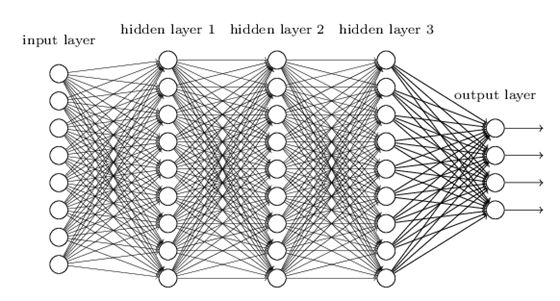
隐藏层的数量决定了学习的深度,并且在试错的基础上找到正确的层数。这些神经网络中的“学习”部分是这些层调整最初分配给它们的权重的方式。
虽然有各种学习方式,但最常用的是反向传播,将输出与训练数据的误差进行比较,并计算输出中的误差。然后,紧靠输出层的层会调整其权重,导致后续内层中的权重调整,直到错误率降低。
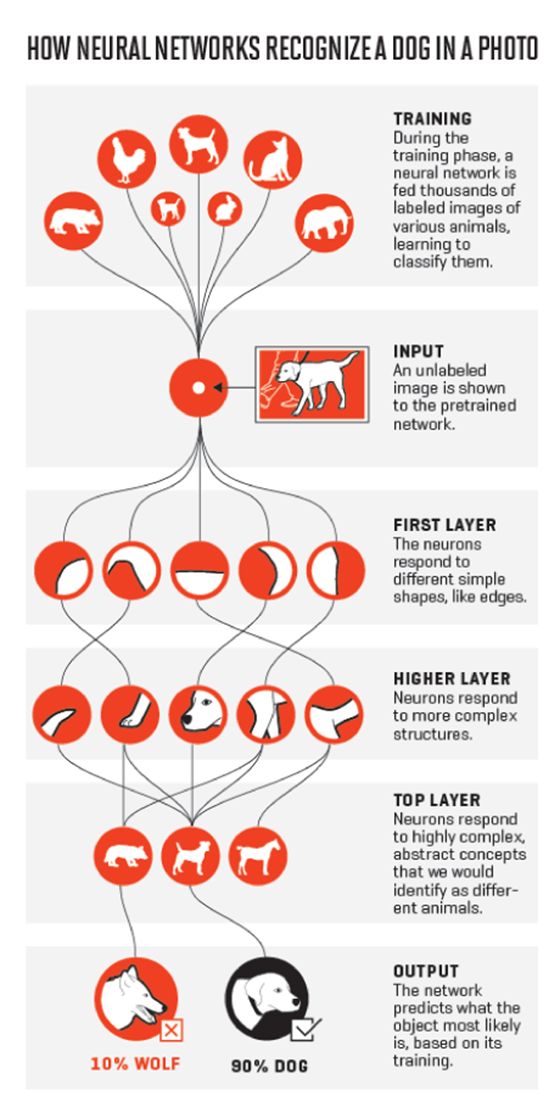
下图形象的展示了隐藏层干了什么。
就像在示例中看到的那样,每个图层都对应一个特定的特征,但解释隐藏层是如何工作的并不容易,这是因为在典型的无监督学习情景中,隐藏层被比作黑匣子,它们做它们做的事情,但每层背后的推理仍然像大脑一样神秘。
深度学习与其他机器学习方法有什么不同?
答案是深度学习所涉及的训练数据量和所需的计算能力。
在详细阐述差异之前,我们必须明白,深度学习是实现机器学习的许多手段之一。由于需要最低程度的人工干预,深度学习只是其中的一种,并迅速普及。
也就是说,传统的ML模型需要一个称为特征提取的过程,程序员必须明确地告诉某个特定训练集中必须查找哪些特征。此外,当任何一个特征被遗漏时,机器学习模型无法识别手中的物体。
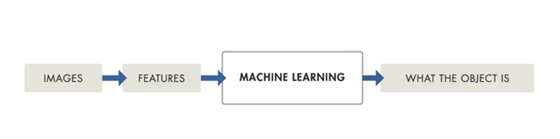
另一方面,深度学习需要大量不同实例的数据集,模型从中学习要查找的特征并生成带有概率向量的输出。
很好!那么,为什么我们不早点开始深度学习呢?
多层感知器和反向传播方法是在20世纪80年代在理论上设计的,但由于缺乏大量的数据和高处理能力,逐渐沉寂了。自大数据和Nvidia超级强大的GPU出现以来,深度学习的潜力正在被不断挖掘。
现在,很多关于深度学习的性能能否提升取决于数据集的大小。尽管有人声称更小但丰富的数据集可以做到这一点,但模型学习的参数越多,或者手中的问题越复杂,训练所需的数据也会增加。否则,具有更多维数和小数据的问题会导致过拟合,这意味着你的模型已经虽然实际取得了结果,但也仅适用于你训练的集合,深度网络失去作用。
为了验证大数据的必要性,我们来看看三个大容量训练数据的成功应用场景:
• Facebook上著名的现代人脸识别系统称为“DeepFace”,部署了一套4000多个身份的4百万面部图像,并且在带标签的数据集上达到了97.35%的准确率。他们的研究论文在许多地方重申了这样的大型训练集如何帮助克服过度拟合问题。
• Alex Krizhevsky - AlexNet开发者,在加入Google Brain之后,与Geoffrey Hinton等其他学者,描述了一个涉及手眼协调的机器人抓握学习模型。为了训练他们的网络,共收集了800,000次抓握尝试,机器人手臂成功地学习了更多种类的抓握策略。
• 特斯拉的AI总监Andrej Karpathy在斯坦福大学博士学位期间使用神经网络进行密集标注 - 识别图像的所有部分,而不仅仅是猫!该团队已经使用了94,000张图片和410万个基于区域的标注,从而提高了速度和准确度。
Andrej还声称他们的座右铭是保持他的数据量大,算法简单,标签少。
那么你的数据有多大?
另一方面,一些人认为数据集并不用太大。最近的一篇关于使用小数据的深度人脸表示的研究论文发现,在人脸识别的问题,用10,000个训练样本和用500,000个训练样本的效果是基本一致的。但对于目前涉及深度学习的其他地方(自动驾驶车辆中的语音识别,车辆,行人和地标识别,自然语言处理和医学成像)尚未证明。迁移学习的一个新方面也被发现需要大量的预先训练的数据集。
直到上述言论被证实,如果你希望应用神经网络,例如Microsoft的销售团队如何使用神经网络来推荐要联系的潜在客户或需要推荐的产品,则需要访问大量的数据。百度前首席数据科学家,深受欢迎的深度学习专家Andrew Ng将深度学习模型与火箭发动机相提并论,这些火箭发动机需要大量的数据燃料。
现在,当我从面条中取出卷心菜时(感谢我惊人的大脑),为什么不开始为你的人工神经网络提供丰富的数据!
原文链接:
https://towardsdatascience.com/why-go-large-with-data-for-deep-learning-12eee16f708
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



