【干货】在Python中构建可部署的ML分类器
【导读】本文是机器学习爱好者 Sambit Mahapatra 撰写的一篇技术博文,利用Python设计一个二分类器,详细讨论了模型中的三个主要过程:处理不平衡数据、调整参数、保存模型和部署模型。文中以“红酒质量预测”作为二分类实例进行讲解,一步步构建二分类器并最终部署使用模型,事先了解numpy和pandas的使用方法能帮助读者更好地理解本文。
编译 | 专知
参与 | Yingying, huaiwen

Building a Deployable ML Classifier in Python
当今,由于问题的复杂性和大量相关的数据,机器学习已经成为解决很多问题的必要选择,有效且高效的方式。 在大多数资源中,用结构化数据构建机器学习模型只是为了检查模型的准确性。 但是,实际开发机器学习模型的主要目的是在构建模型时处理不平衡数据,并调整参数,并将模型保存到文件系统中供以后使用或部署。 在这里,我们将看到如何在处理上面指定的三个需求的同时在python中设计一个二分类器。
在开发机器学习模型时,我们通常将所有创新都放在标准工作流程中。 其中涉及的一些步骤是获取数据,特征工程,迭代训练和测试模型,并在生产环境中部署构建的模型。
我们将通过构建一个二类分类器用一些可见的特征来预测红酒的质量。 该数据集可在UCI Machine Learning Repository中获得。 Scikit学习库用于分类器设计。
源代码的github链接是
-https://github.com/sambit9238/Machine-Learning/blob/master/WineQuality.ipynb
首先,我们需要导入所有必需的依赖并加载数据集。 由于数据框架,矩阵和阵列操作都涉及到,所以在任何ml模型设计中,我们总是需要numpy和pandas。
import numpy as np
import pandas as pd
df = pd.read_csv("winequality-red.csv")
df.head()
数据集为:
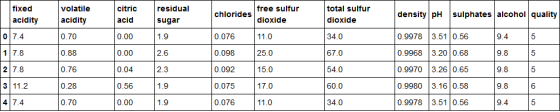
从这里可以看出,红酒质量已经由3到8的数字表示。为了使其成为二分类问题,让我们取> 5表示质量好,否则表示质量不好。
df["quality_bin"] = np.zeros(df.shape[0])
df["quality_bin"] = df["quality_bin"].where(df["quality"]>=6, 1)
#1 means good quality and 0 means bad quality
得到数据的摘要:
df.describe()
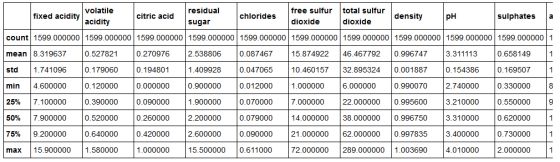
从快照中可以看到,数据值在某些属性上相当偏离。 比较好的做法是标准化这些值,因为它会使方差达到合理的水平。 另外,由于大多数算法使用欧几里德距离,因此在模型构建中缩放特征效果更好。
from sklearn.preprocessing import StandardScaler
X_data = df.iloc[:,:11].values
y_data = df.iloc[:,12].values
scaler = StandardScaler()
X_data = scaler.fit_transform(X_data)
这里使用了fit_transform,以便StandardScaler可以适应X_data并转换X_data。 如果您需要在两个不同的数据集上进行拟合和转换,您也可以分别调用拟合和转换函数。 现在,我们共有1599个数据实例,其中855个为劣质葡萄酒,744个为优质。 数据在这里显然是不平衡的。 由于数据实例的数量较少,所以我们将进行过采样。 但重要的是,过采样应该总是只在训练数据上进行,而不是在测试/验证数据上进行。 现在,我们将数据集划分为模型构建的训练和测试数据集。
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.3, random_state=42)
#so that 30% will be selected for testing data randomly
除了训练和测试拆分之外,您还可以选择更有效的交叉验证方法。 现在我们有588个劣质和531个优质的样本。 仍有267个质量差和213个质量好的样本用于测试。 然后就该对训练数据进行重新采样来平衡它,这样模型就不会出现偏差。 这里我们将使用SMOTE算法进行过采样。
from imblearn.over_sampling import SMOTE
#resampling need to be done on training dataset only
X_train_res, y_train_res = SMOTE().fit_sample(X_train, y_train)
经过过采样,共有588例来自训练组优质和劣质葡萄酒。 然后进行模型选择。 我在这里采用了随机梯度分类器。 但是,你可以检查几个模型,并比较它们的准确性来选择合适的。
from sklearn.linear_model import SGDClassifier
sg = SGDClassifier(random_state=42)
sg.fit(X_train_res,y_train_res)
pred = sg.predict(X_test)
from sklearn.metrics import classification_report,accuracy_score
print(classification_report(y_test, pred))
print(accuracy_score(y_test, pred))
结果为:
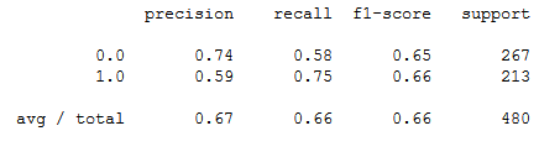
得到的准确度是65.625%。 学习率,损失函数等参数对模型的性能起主要作用。 我们可以使用GridSearchCV有效地选择模型的最佳参数。
#parameter tuning
from sklearn.model_selection import GridSearchCV
#model
model = SGDClassifier(random_state=42)
#parameters
params = {'loss': ["hinge", "log", "perceptron"],
'alpha':[0.001, 0.0001, 0.00001]}
#carrying out grid search
clf = GridSearchCV(model, params)
clf.fit(X_train_res, y_train_res)
#the selected parameters by grid search
print(clf.best_estimator_)

从这里可以看出,这里只提供了损失函数和alpha,以便为它们找到最佳选择。 其他参数也可以做到这一点。 损失函数的最佳选择似乎是'Hinge' 如线性SVM和α值似乎是0.001。 现在,我们将使用网格搜索选择的最佳参数来构建模型。
#final model by taking suitable parameters
clf = SGDClassifier(random_state=42, loss="hinge", alpha=0.001)
clf.fit(X_train_res, y_train_res)
pred = clf.predict(X_test)
现在,我们选择模型,调整参数,以便在部署之前验证模型。
print(classification_report(y_test, pred))
print(accuracy_score(y_test, pred))
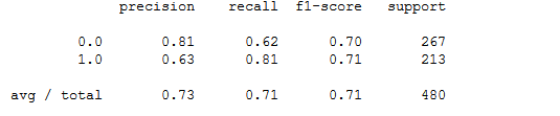
从这里可以看出,调整参数后,度量值已经提高了2-3%。 准确度也从65.625%提高到70.625%。 如果您对该模型不满意,可以通过一些训练和测试迭代来尝试其他算法。 现在,由于模型已经建立,所以需要将其保存到文件系统以备后用或在其他地方部署。
from sklearn.externals import joblib
joblib.dump(clf, "wine_quality_clf.pkl")
当您需要分类器时,可以使用joblib加载它,并传递特征数组以获取结果。
clf1 = joblib.load("wine_quality_clf.pkl")
clf1.predict([X_test[0]])
原文链接:
https://towardsdatascience.com/building-a-deployable-ml-classifier-in-python-46ba55e1d720
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



